Data Flow
Dataset Flavors
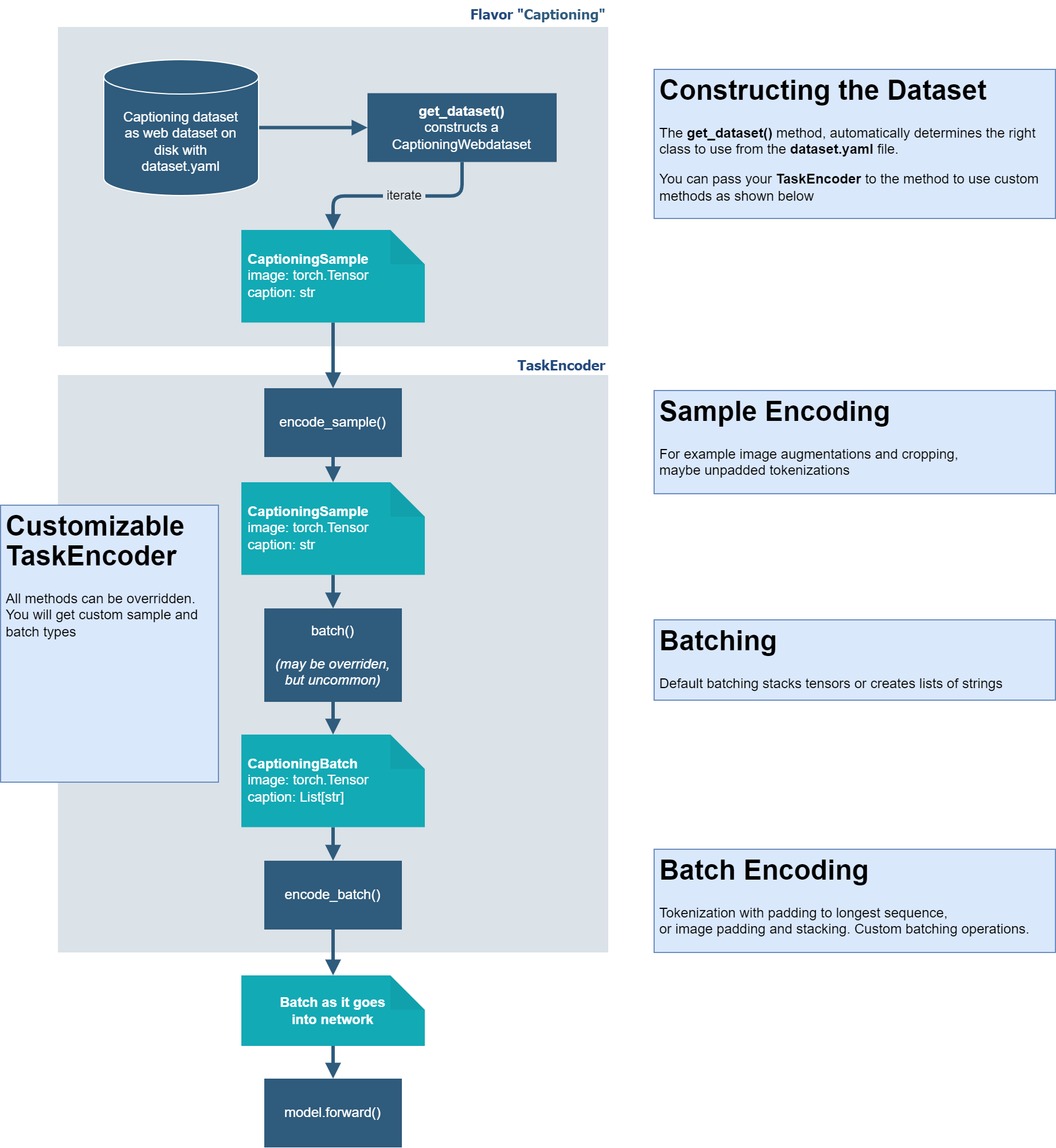
The datasets are organized in “flavors”, i.e. each modality returned by the dataset is a “flavor”.
A modality can for example be a CaptioningSample or an
VQASample. The dataset class combines the source data format
and the iterated sample format. For example, the CaptioningWebdataset
combines the webdataset loader with the CaptioningSample.
For all types, see Dataset Flavors below.
Task Encoders
The task encoder define how the data is processed after loading from the dataset, before iterating batches in the training/validation loop. You should typically define your own task encoder, as you always need to encode text tokens specifically for your network, or want image augmentations.
For more details see Task Encoders.