Guardrails Process#
This guide provides an overview of the main types of rails supported in NeMo Guardrails and the process of invoking them.
Overview#
NeMo Guardrails has support for five main categories of rails: input, dialog, output, retrieval, and execution. The diagram below provides an overview of the high-level flow through these categories of flows.
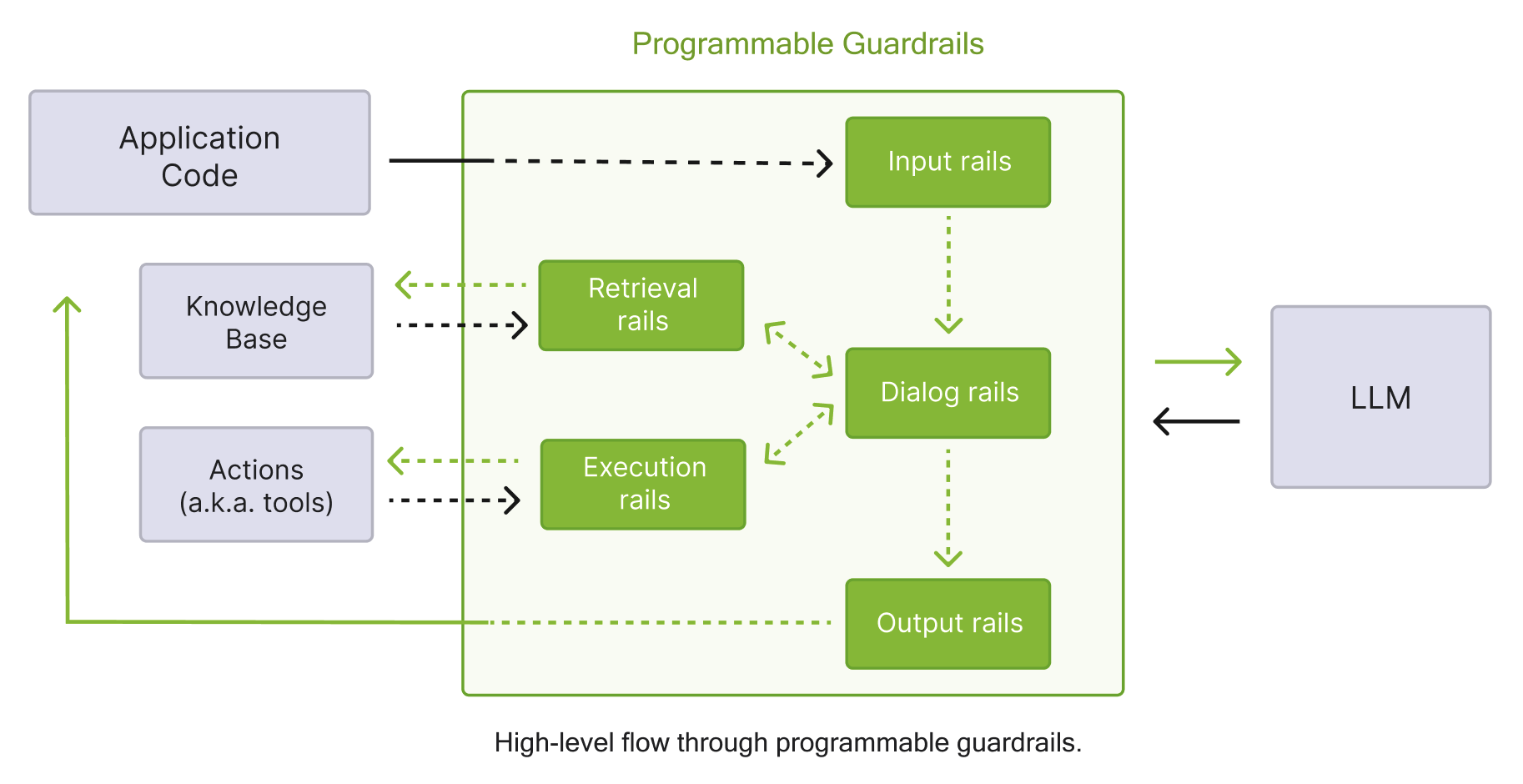
Categories of Rails#
There are five types of rails supported in NeMo Guardrails:
Input rails: applied to the input from the user; an input rail can reject the input ( stopping any additional processing) or alter the input (e.g., to mask potentially sensitive data, to rephrase).
Dialog rails: influence how the dialog evolves and how the LLM is prompted; dialog rails operate on canonical form messages (more details here) and determine if an action should be executed, if the LLM should be invoked to generate the next step or a response, if a predefined response should be used instead, etc.
Retrieval rails: applied to the retrieved chunks in the case of a RAG (Retrieval Augmented Generation) scenario; a retrieval rail can reject a chunk, preventing it from being used to prompt the LLM, or alter the relevant chunks (e.g., to mask potentially sensitive data).
Execution rails: applied to input/output of the custom actions (a.k.a. tools) that need to be called.
Output rails: applied to the output generated by the LLM; an output rail can reject the output, preventing it from being returned to the user or alter it (e.g., removing sensitive data).
The Guardrails Process#
The diagram below depicts the guardrails process in detail:
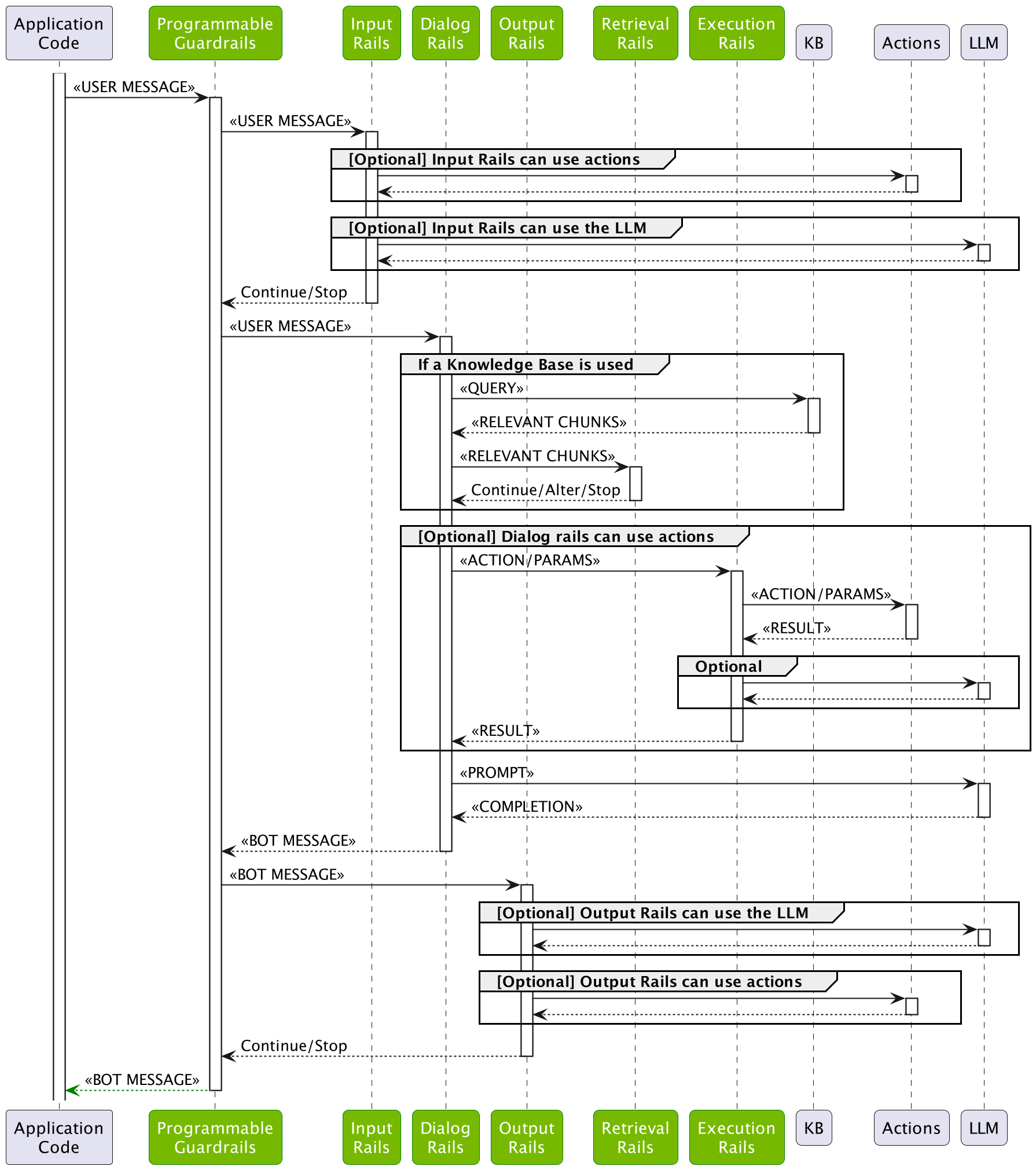
The guardrails process has multiple stages that a user message goes through:
Input Validation stage: The user input is first processed by the input rails. The input rails decide if the input is allowed, whether it should be altered or rejected.
Dialog stage: If the input is allowed and the configuration contains dialog rails (i.e., at least one user message is defined), then the user message is processed by the dialog flows. This will ultimately result in a bot message.
Output Validation stage: After a bot message is generated by the dialog rails, it is processed by the output rails. The Output rails decide if the output is allowed, whether it should be altered, or rejected.
The Dialog Rails Flow#
The diagram below depicts the dialog rails flow in detail:
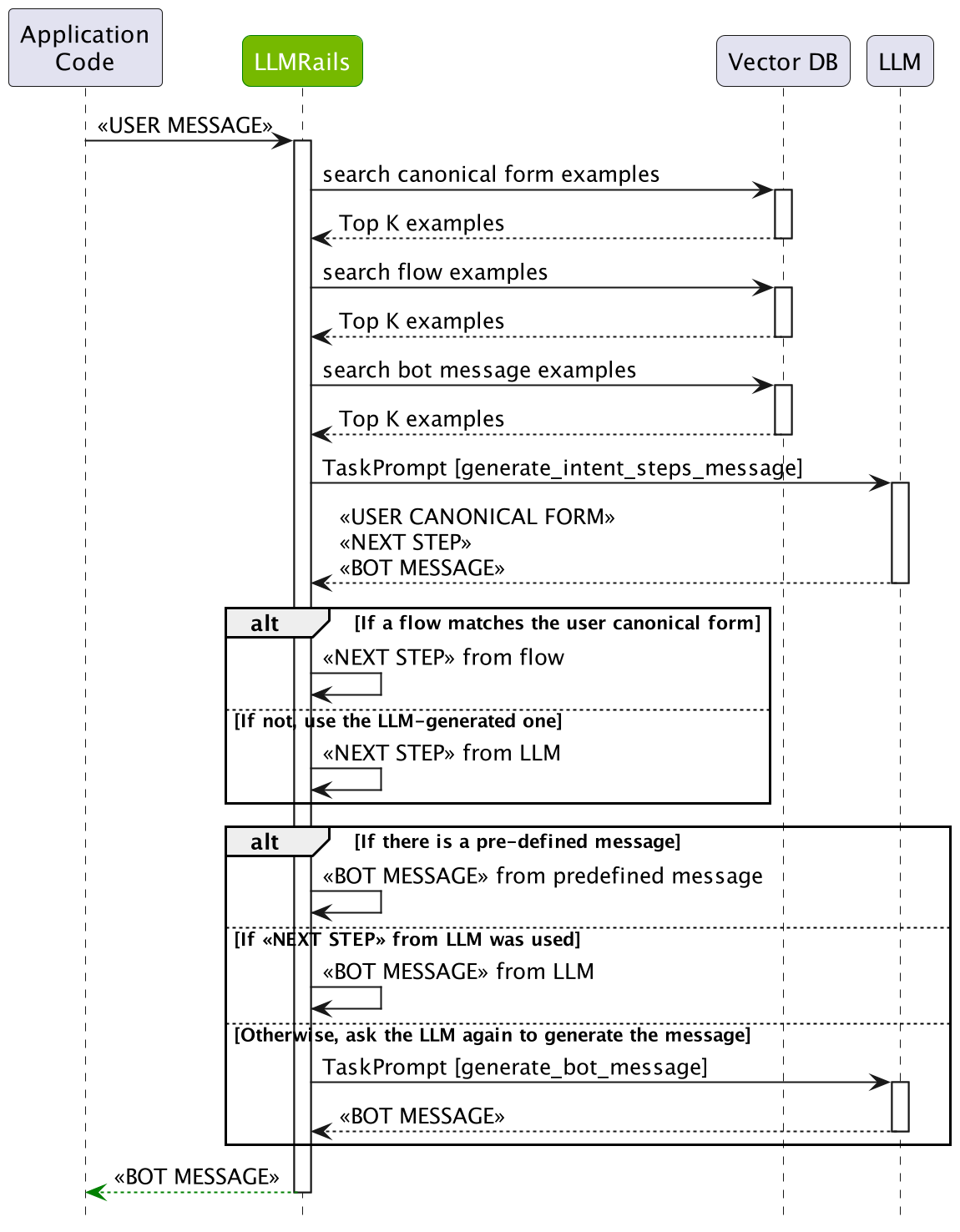
The dialog rails flow has multiple stages that a user message goes through:
User Intent Generation: First, the user message has to be interpreted by computing the canonical form (a.k.a. user intent). This is done by searching the most similar examples from the defined user messages, and then asking LLM to generate the current canonical form.
Next Step Prediction: After the canonical form for the user message is computed, the next step needs to be predicted. If there is a Colang flow that matches the canonical form, then the flow will be used to decide. If not, the LLM will be asked to generate the next step using the most similar examples from the defined flows.
Bot Message Generation: Ultimately, a bot message needs to be generated based on a canonical form. If a pre-defined message exists, the message will be used. If not, the LLM will be asked to generate the bot message using the most similar examples.
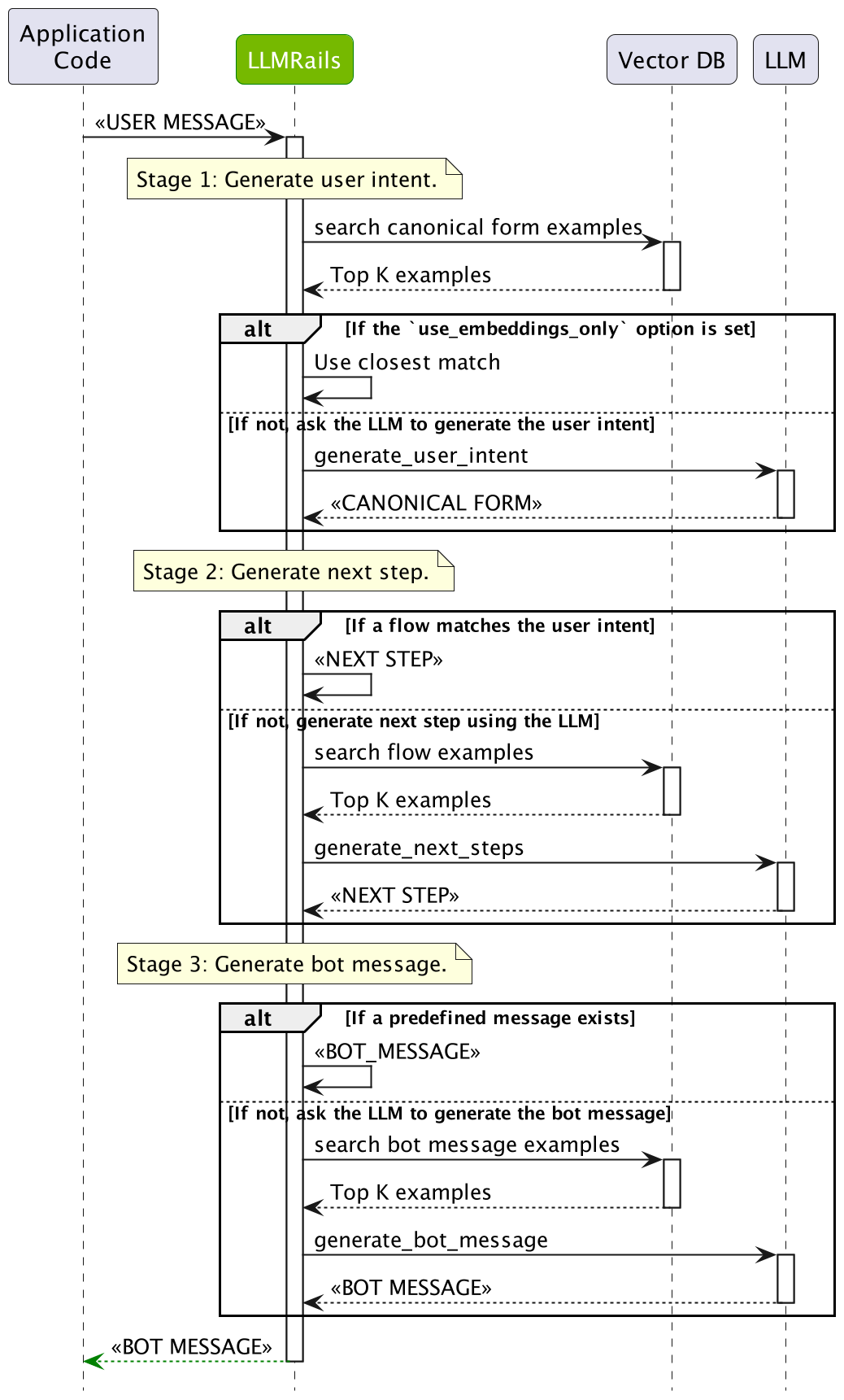
Single LLM Call#
When the single_llm_call.enabled is set to True, the dialog rails flow will be simplified to a single LLM call that predicts all the steps at once. The diagram below depicts the simplified dialog rails flow: