Getting Started¶
Overview¶
Transformer Engine (TE) is a library for accelerating Transformer models on NVIDIA GPUs, providing better performance with lower memory utilization in both training and inference. It provides support for 8-bit floating point (FP8) precision on Hopper GPUs, implements a collection of highly optimized building blocks for popular Transformer architectures, and exposes an automatic-mixed-precision-like API that can be used seamlessy with your PyTorch code. It also includes a framework-agnostic C++ API that can be integrated with other deep learning libraries to enable FP8 support for Transformers.
Let’s build a Transformer layer!¶
Summary
We build a basic Transformer layer using regular PyTorch modules. This will be our baseline for later comparisons with Transformer Engine.
Let’s start with creating a GPT encoder layer using plain PyTorch. Figure 1 shows the overall structure.
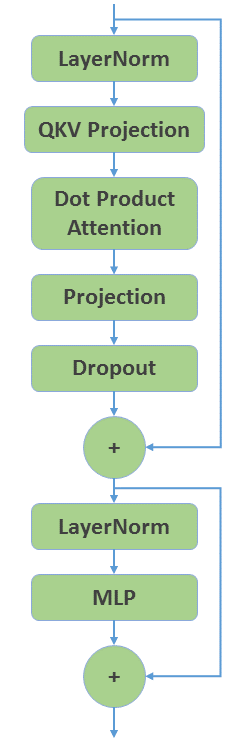
Figure 1: Structure of a GPT encoder layer.
We construct the components as follows:
LayerNorm:torch.nn.LayerNormQKV Projection:torch.nn.Linear(conceptually threeLinearlayers for Q, K, and V separately, but we fuse into a singleLinearlayer that is three times larger)DotProductAttention:DotProductAttentionfrom quickstart_utils.pyProjection:torch.nn.LinearDropout:torch.nn.DropoutMLP:BasicMLPfrom quickstart_utils.py
Over the course of this tutorial we will use a few modules and helper functions defined in quickstart_utils.py. Putting it all together:
[1]:
import torch
import quickstart_utils as utils
class BasicTransformerLayer(torch.nn.Module):
def __init__(
self,
hidden_size: int,
ffn_hidden_size: int,
num_attention_heads: int,
layernorm_eps: int = 1e-5,
attention_dropout: float = 0.1,
hidden_dropout: float = 0.1,
):
super().__init__()
self.num_attention_heads = num_attention_heads
self.kv_channels = hidden_size // num_attention_heads
self.ln1 = torch.nn.LayerNorm(hidden_size, eps=layernorm_eps)
self.qkv_projection = torch.nn.Linear(hidden_size, 3 * hidden_size, bias=True)
self.attention = utils.DotProductAttention(
num_attention_heads=num_attention_heads,
kv_channels=self.kv_channels,
attention_dropout=attention_dropout,
)
self.projection = torch.nn.Linear(hidden_size, hidden_size, bias=True)
self.dropout = torch.nn.Dropout(hidden_dropout)
self.ln2 = torch.nn.LayerNorm(hidden_size, eps=layernorm_eps)
self.mlp = utils.BasicMLP(
hidden_size=hidden_size,
ffn_hidden_size=ffn_hidden_size,
)
def forward(
self,
x: torch.Tensor,
attention_mask: torch.Tensor
) -> torch.Tensor:
res = x
x = self.ln1(x)
# Fused QKV projection
qkv = self.qkv_projection(x)
qkv = qkv.view(qkv.size(0), qkv.size(1), self.num_attention_heads, 3 * self.kv_channels)
q, k, v = torch.split(qkv, qkv.size(3) // 3, dim=3)
x = self.attention(q, k, v, attention_mask)
x = self.projection(x)
x = self.dropout(x)
x = res + x
res = x
x = self.ln2(x)
x = self.mlp(x)
return x + res
That’s it! We now have a simple Transformer layer. We can test it:
[2]:
# Layer configuration
hidden_size = 4096
sequence_length = 2048
batch_size = 4
ffn_hidden_size = 16384
num_attention_heads = 32
dtype = torch.float16
# Synthetic data
x = torch.rand(sequence_length, batch_size, hidden_size).cuda().to(dtype=dtype)
dy = torch.rand(sequence_length, batch_size, hidden_size).cuda().to(dtype=dtype)
[3]:
basic_transformer = BasicTransformerLayer(
hidden_size,
ffn_hidden_size,
num_attention_heads,
)
basic_transformer.to(dtype=dtype).cuda()
[3]:
BasicTransformerLayer(
(ln1): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(qkv_projection): Linear(in_features=4096, out_features=12288, bias=True)
(attention): DotProductAttention(
(dropout): Dropout(p=0.1, inplace=False)
)
(projection): Linear(in_features=4096, out_features=4096, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(ln2): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(mlp): BasicMLP(
(linear1): Linear(in_features=4096, out_features=16384, bias=True)
(linear2): Linear(in_features=16384, out_features=4096, bias=True)
)
)
[4]:
torch.manual_seed(1234)
y = basic_transformer(x, attention_mask=None)
[5]:
utils.speedometer(
basic_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
)
Mean time: 43.0663916015625 ms
Meet Transformer Engine¶
Summary
We modify the example Transformer layer to include the simplest TE modules: Linear and LayerNorm.
Now that we have a basic Transformer layer, let’s use Transformer Engine to speed up the training.
[6]:
import transformer_engine.pytorch as te
TE provides a set of PyTorch modules that can be used to build Transformer layers. The simplest of the provided modules are the Linear and LayerNorm layers, which we can use instead of torch.nn.Linear and torch.nn.LayerNorm. Let’s modify BasicTransformerLayer:
[7]:
class BasicTEMLP(torch.nn.Module):
def __init__(self,
hidden_size: int,
ffn_hidden_size: int) -> None:
super().__init__()
self.linear1 = te.Linear(hidden_size, ffn_hidden_size, bias=True)
self.linear2 = te.Linear(ffn_hidden_size, hidden_size, bias=True)
def forward(self, x):
x = self.linear1(x)
x = torch.nn.functional.gelu(x, approximate='tanh')
x = self.linear2(x)
return x
class BasicTETransformerLayer(torch.nn.Module):
def __init__(self,
hidden_size: int,
ffn_hidden_size: int,
num_attention_heads: int,
layernorm_eps: int = 1e-5,
attention_dropout: float = 0.1,
hidden_dropout: float = 0.1):
super().__init__()
self.num_attention_heads = num_attention_heads
self.kv_channels = hidden_size // num_attention_heads
self.ln1 = te.LayerNorm(hidden_size, eps=layernorm_eps)
self.qkv_projection = te.Linear(hidden_size, 3 * hidden_size, bias=True)
self.attention = utils.DotProductAttention(
num_attention_heads=num_attention_heads,
kv_channels=self.kv_channels,
attention_dropout=attention_dropout,
)
self.projection = te.Linear(hidden_size, hidden_size, bias=True)
self.dropout = torch.nn.Dropout(hidden_dropout)
self.ln2 = te.LayerNorm(hidden_size, eps=layernorm_eps)
self.mlp = BasicTEMLP(
hidden_size=hidden_size,
ffn_hidden_size=ffn_hidden_size,
)
def forward(self,
x: torch.Tensor,
attention_mask: torch.Tensor):
res = x
x = self.ln1(x)
# Fused QKV projection
qkv = self.qkv_projection(x)
qkv = qkv.view(qkv.size(0), qkv.size(1), self.num_attention_heads, 3 * self.kv_channels)
q, k, v = torch.split(qkv, qkv.size(3) // 3, dim=3)
x = self.attention(q, k, v, attention_mask)
x = self.projection(x)
x = self.dropout(x)
x = res + x
res = x
x = self.ln2(x)
x = self.mlp(x)
return x + res
[8]:
basic_te_transformer = BasicTETransformerLayer(
hidden_size,
ffn_hidden_size,
num_attention_heads,
)
basic_te_transformer.to(dtype=dtype).cuda()
utils.share_parameters_with_basic_te_model(basic_te_transformer, basic_transformer)
[9]:
torch.manual_seed(1234)
y = basic_te_transformer(x, attention_mask=None)
[10]:
utils.speedometer(
basic_te_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
)
Mean time: 43.1413232421875 ms
Fused TE Modules¶
Summary
We optimize the example Transformer layer with TE modules for fused operations.
The Linear layer is enough to build any Transformer model and it enables usage of Transformer Engine even for very custom Transformers. However, having more knowledge about the model allows for additional optimizations like kernel fusion, increasing the achievable speedup.
Transformer Engine therefore provides coarser modules that span multiple layers:
LayerNormLinearLayerNormMLPTransformerLayer
Building a third iteration of our Transformer layer with LayerNormLinear and LayerNormMLP:
[11]:
class FusedTETransformerLayer(torch.nn.Module):
def __init__(self,
hidden_size: int,
ffn_hidden_size: int,
num_attention_heads: int,
layernorm_eps: int = 1e-5,
attention_dropout: float = 0.1,
hidden_dropout: float = 0.1):
super().__init__()
self.num_attention_heads = num_attention_heads
self.kv_channels = hidden_size // num_attention_heads
self.ln_qkv = te.LayerNormLinear(hidden_size, 3 * hidden_size, eps=layernorm_eps, bias=True)
self.attention = utils.DotProductAttention(
num_attention_heads=num_attention_heads,
kv_channels=self.kv_channels,
attention_dropout=attention_dropout,
)
self.projection = te.Linear(hidden_size, hidden_size, bias=True)
self.dropout = torch.nn.Dropout(hidden_dropout)
self.ln_mlp = te.LayerNormMLP(hidden_size, ffn_hidden_size, eps=layernorm_eps, bias=True)
def forward(self,
x: torch.Tensor,
attention_mask: torch.Tensor):
res = x
qkv = self.ln_qkv(x)
# Split qkv into query, key and value
qkv = qkv.view(qkv.size(0), qkv.size(1), self.num_attention_heads, 3 * self.kv_channels)
q, k, v = torch.split(qkv, qkv.size(3) // 3, dim=3)
x = self.attention(q, k, v, attention_mask)
x = self.projection(x)
x = self.dropout(x)
x = res + x
res = x
x = self.ln_mlp(x)
return x + res
[12]:
fused_te_transformer = FusedTETransformerLayer(hidden_size, ffn_hidden_size, num_attention_heads)
fused_te_transformer.to(dtype=dtype).cuda()
utils.share_parameters_with_fused_te_model(fused_te_transformer, basic_transformer)
[13]:
torch.manual_seed(1234)
y = fused_te_transformer(x, attention_mask=None)
[14]:
utils.speedometer(
fused_te_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
)
Mean time: 43.1981201171875 ms
Finally, the TransformerLayer module is convenient for creating standard Transformer architectures and it provides the highest degree of performance optimization:
[15]:
te_transformer = te.TransformerLayer(hidden_size, ffn_hidden_size, num_attention_heads)
te_transformer.to(dtype=dtype).cuda()
utils.share_parameters_with_transformerlayer_te_model(te_transformer, basic_transformer)
[16]:
torch.manual_seed(1234)
y = te_transformer(x, attention_mask=None)
[17]:
utils.speedometer(
te_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
)
Mean time: 39.99169921875 ms
Enabling FP8¶
Summary
We configure a TE module to perform compute in FP8.
Enabling FP8 support is very simple in Transformer Engine. We just need to wrap the modules within an fp8_autocast context manager. Note that fp8_autocast should only be used to wrap the forward pass and must exit before starting a backward pass. See the FP8 tutorial for a detailed explanation of FP8 recipes and the supported options.
[18]:
from transformer_engine.common.recipe import Format, DelayedScaling
te_transformer = te.TransformerLayer(hidden_size, ffn_hidden_size, num_attention_heads)
te_transformer.to(dtype=dtype).cuda()
utils.share_parameters_with_transformerlayer_te_model(te_transformer, basic_transformer)
fp8_format = Format.HYBRID
fp8_recipe = DelayedScaling(fp8_format=fp8_format, amax_history_len=16, amax_compute_algo="max")
torch.manual_seed(1234)
with te.fp8_autocast(enabled=True, fp8_recipe=fp8_recipe):
y = te_transformer(x, attention_mask=None)
[19]:
utils.speedometer(
te_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
fp8_autocast_kwargs = { "enabled": True, "fp8_recipe": fp8_recipe },
)
Mean time: 28.61394775390625 ms