Features#
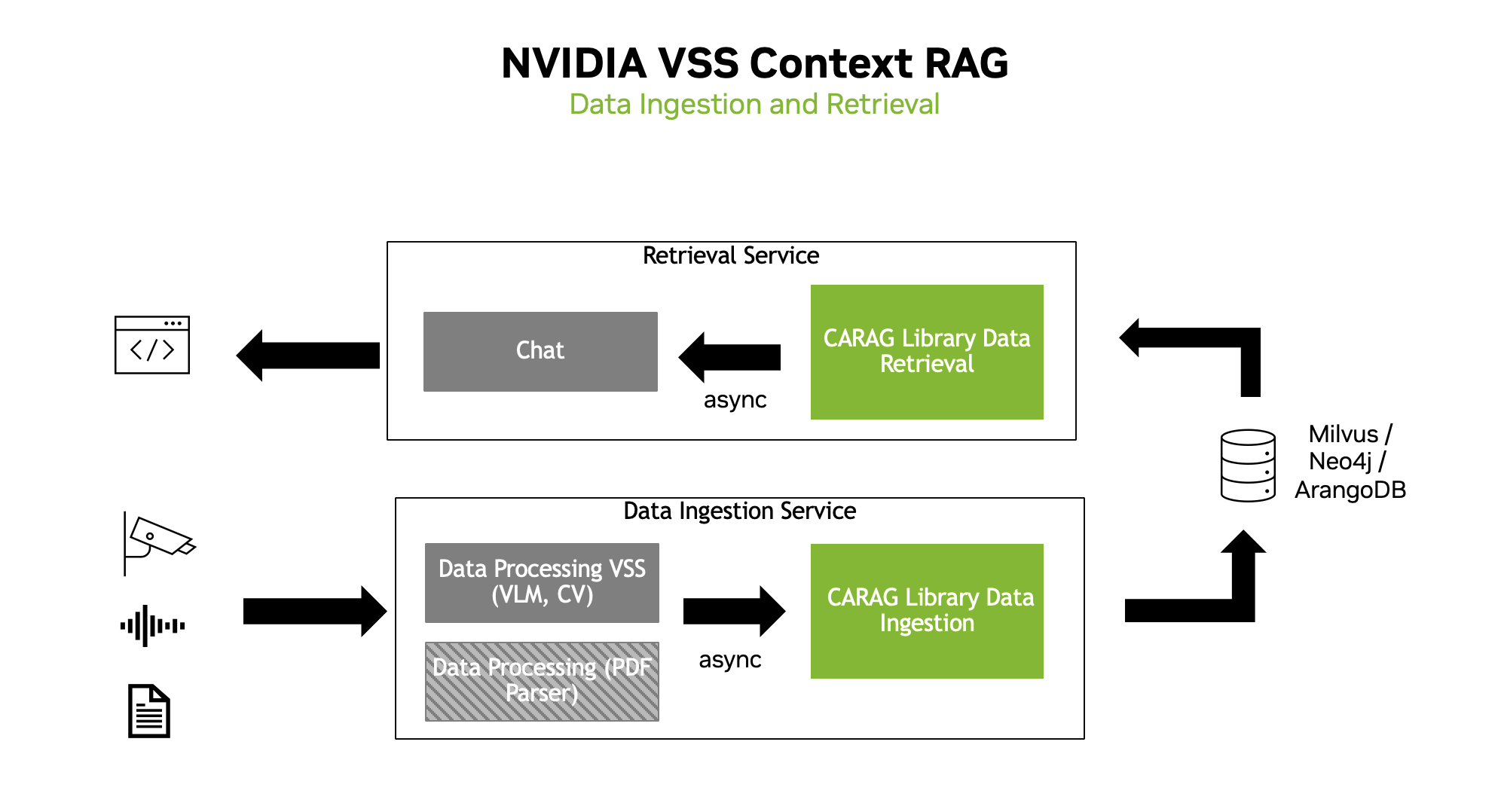
The codebase distinguishes between services for data ingestion and data retrieval:
Data Ingestion and Data Retrieval Services#
Data Ingestion Service:
Responsible for receiving and processing incoming documents.
Uses the context manager to add documents, process them via batching, and prepare them for subsequent retrieval.
Data Retrieval Service:
Focuses on extracting the relevant context in response to user queries.
Leverages Graph-RAG, Vector-RAG or Foundation-RAG functions to deliver precise, context-aware answers.
Ingestion Strategies#
Parallel and Asynchronous Ingestion:
Documents are ingested in parallel and asynchronously processed to avoid blocking the main process.
Documents can be added with doc_index and doc_meta.
doc_indexis used to uniquely identify the document (doc_0,doc_1,doc_2, etc.).doc_metais used to store additional metadata about the document ({stream_id: 0, timestamp: 1716393600}).
Processing is done in Context-Aware RAG separate process.
Documents can arrive in any order.
Batcher:
Batcher groups documents into fixed-size, duplicate-checked batches (using doc_id//batch_size).
When a batch fills up, downstream processing can be triggered immediately (e.g., graph extraction).
Example Batching Process (with batch_size = 2):
If
doc_4arrives first, it’s placed in batch 2 (doc_id 4 // batch_size 2 = 2)When
doc_0arrives, it’s placed in batch 0 (doc_id 0 // batch_size 2 = 0)When
doc_1arrives, it completes batch 0 (doc_id 1 // batch_size 2 = 0)Batch
0is now full and triggers asynchronous processing:Partial graph construction begins for documents
0and1
This process continues until all documents arrive
Once all batches are processed, the final lexical graph is constructed.
Retrieval Strategies#
Retrieval in this codebase can be configured through different approaches:
VectorRAG
Captions generated by the Vision-Language Model (VLM), along with their embeddings, are stored in Milvus DB.
Embeddings can be created using any embedding NIM
By default, embeddings are created using nvidia/llama-3_2-nv-embedqa-1b-v2.
For a query, the top five most similar chunks are retrieved, re-ranked using any reranker NIM and passed to a Large Language Model (LLM) NIM to generate the final answer.
By default, the reranker NIM is set to nvidia/llama-3_2-nv-rerankqa-1b-v2.
GraphRAG
Graph Extraction: Entities and relationships are extracted from VLM captions, using an LLM, and stored in a GraphDB. Captions and embeddings, generated with any embedding NIM, are also linked to these entities.
Graph Retrieval: For a given query, relevant entities, relationships, and captions are retrieved from the GraphDB and passed to an LLM NIM to generate the final answer.
Multi-stream Support:
CA-RAG supports multi-stream processing, allowing users to process multiple live streams or files concurrently.
For multi-stream processing, stream-id is stored with each caption and entity. This allows to retrieve the captions and corresponding entities and relationships for a specific stream.
To enable multi-stream processing, set the
multi-channelparameter totruein theconfig/config.yamlfile. By default, it is set tofalse.
Database Support: GraphRAG is compatible with Neo4j and ArangoDB databases for graph storage and retrieval.
Chain-of-Thought Retrieval (COT)
Enhanced Reasoning: Builds upon GraphRAG by adding chain-of-thought reasoning capabilities to improve query understanding and response quality.
Graph-Based Foundation: Uses the same graph extraction and storage approach as GraphRAG with Neo4j or ArangoDB databases.
Reasoning Process: For a given query, the system performs multi-step reasoning over the graph structure, considering entity relationships and context to generate more comprehensive answers.
Vision Language Model Integration: Could incorporate a separate VLM (like GPT-4o) alongside the main LLM for enhanced reasoning capabilities.
Database Compatibility: Works with Neo4j and ArangoDB databases.
Chain-of-Thought Retrieval with Vision Language Model (VLM)
Visual Understanding: Enables visual understanding capabilities for image-based retrieval and analysis.
Graph-Based Storage: Uses graph databases (Neo4j/ArangoDB) to store entities, relationships, and visual content metadata.
Image Processing: Integrates with image fetching services (MinIO) to retrieve and analyze visual content during query processing.
Multimodal Model Architecture: Combines a standard LLM for text processing with a specialized VLM for visual understanding.
Foundation-RAG (FRAG)
Enhanced Vector Retrieval: Provides advanced vector-based retrieval with Nvidia-RAG blueprint built on top of VectorRAG.
Vector Database Support: Compatible with the Milvus vector database.
Reranking Integration: Incorporates NVIDIA reranker models for improved result relevance.
Advanced Graph Retrieval with Planning and VLM (Planner)
Advanced Graph Retrieval: Uses
adv_graph_retrievaltype for sophisticated multi-step query processing and iterative search.Planning Capabilities: Incorporates planning algorithms to break down complex queries into manageable sub-tasks.
Tool Integration: Supports multiple retrieval tools including:
chunk_search: For finding relevant document chunkschunk_filter: For filtering results based on criteriaentity_search: For searching generated graph entitieschunk_reader: For detailed content analysis which uses VLM over extracted chunk’s frames and captions
Multi-Modal Support: Combines graph databases or vector databases, LLMs, and VLMs for comprehensive information retrieval.
Database Flexibility: Works with Neo4j and ArangoDB databases.
Database Backend Support#
CA-RAG supports multiple database backends for different retrieval strategies:
Milvus: Vector database optimized for VectorRAG and Foundation-RAG
Elasticsearch: Alternative vector database for VectorRAG
Neo4j: Graph database for GraphRAG, COT, VLM, and Planner strategies
ArangoDB: Alternative graph database for GraphRAG, COT, VLM, and Planner strategies
Each retrieval strategy can be configured with appropriate database backends as shown in the compatibility matrix in the Advanced Setup Guide.
Summarization#
The summarization feature allows users to summarize documents.
Context Aware RAG provides the following methods for summarizing content.
Batch: This method performs summarization in two stages:
Batching: Groups together documents into batches and generates summaries for each batch.
Aggregation: Combines batch summaries using a secondary prompt (summary_aggregation).
Offline Summarization: Batch summarization summarizes as a batch of documents as soon as the batch is full while still receiving documents. Offline summarization on the other hand, summarizes the batches only when the user requests for it.
Summary Retriever: Retrieves documents between given start and end times and summarizes it based on the configured prompt.
Alerts#
The Alerts feature allows event-based notifications. For each document added, an LLM analyzes and generates alerts based on the natural language defined event criteria.
For example, to configure alerts for a document stream detailing a traffic incident, important events can be defined in natural language:
incident: accident on the road;
response: first responders arrive for help;
When an alert is detected, the response is sent to the user via the notification system. Here is an example of the alert notification:
Alert Name: incident
Detected Events: accident on the road
Time: 80 seconds
Details: 2025-03-15 12:07:39 PM: The scene depicts an intersection with painted
stop lines and directional arrows on the road surface. A red sedan and a yellow
sedan are involved in a collision within the intersection. The red sedan appears to
be impacting the yellow sedan on its front passenger side.