Using Quantum Hardware Providers¶
CUDA-Q contains support for using a set of hardware providers (Amazon Braket, Infleqtion, IonQ, IQM, OQC, ORCA Computing, Quantinuum, and QuEra Computing). For more information about executing quantum kernels on different hardware backends, please take a look at hardware.
Amazon Braket¶
The following code illustrates how to run kernels on Amazon Braket’s backends.
import cudaq
# NOTE: Amazon Braket credentials must be set before running this program.
# Amazon Braket costs apply.
cudaq.set_target("braket")
# The default device is SV1, state vector simulator. Users may choose any of
# the available devices by supplying its `ARN` with the `machine` parameter.
# For example,
# ```
# cudaq.set_target("braket", machine="arn:aws:braket:eu-north-1::device/qpu/iqm/Garnet")
# ```
# Create the kernel we'd like to execute
@cudaq.kernel
def kernel():
qvector = cudaq.qvector(2)
h(qvector[0])
x.ctrl(qvector[0], qvector[1])
mz(qvector)
# Execute and print out the results.
# Option A:
# By using the asynchronous `cudaq.sample_async`, the remaining
# classical code will be executed while the job is being handled
# by Amazon Braket.
async_results = cudaq.sample_async(kernel)
# ... more classical code to run ...
async_counts = async_results.get()
print(async_counts)
# Option B:
# By using the synchronous `cudaq.sample`, the execution of
# any remaining classical code in the file will occur only
# after the job has been returned from Amazon Braket.
counts = cudaq.sample(kernel)
print(counts)
// Compile and run with:
// ```
// nvq++ --target braket braket.cpp -o out.x && ./out.x
// ```
// This will submit the job to the Amazon Braket state vector simulator
// (default). Alternatively, users can choose any of the available devices by
// specifying its `ARN` with the `--braket-machine`, e.g.,
// ```
// nvq++ --target braket --braket-machine \
// "arn:aws:braket:eu-north-1::device/qpu/iqm/Garnet" braket.cpp -o out.x
// ./out.x
// ```
// Assumes a valid set of credentials have been set prior to execution.
#include <cudaq.h>
#include <fstream>
// Define a simple quantum kernel to execute on Amazon Braket.
struct ghz {
// Maximally entangled state between 5 qubits.
auto operator()() __qpu__ {
cudaq::qvector q(5);
h(q[0]);
for (int i = 0; i < 4; i++) {
x<cudaq::ctrl>(q[i], q[i + 1]);
}
auto result = mz(q);
}
};
int main() {
// Submit asynchronously (e.g., continue executing
// code in the file until the job has been returned).
auto future = cudaq::sample_async(ghz{});
// ... classical code to execute in the meantime ...
// Get the results of the read in future.
auto async_counts = future.get();
async_counts.dump();
// OR: Submit synchronously (e.g., wait for the job
// result to be returned before proceeding).
auto counts = cudaq::sample(ghz{});
counts.dump();
}
Infleqtion¶
The following code illustrates how to run kernels on Infleqtion’s backends.
import cudaq
# You only have to set the target once! No need to redefine it
# for every execution call on your kernel.
# To use different targets in the same file, you must update
# it via another call to `cudaq.set_target()`
cudaq.set_target("infleqtion")
# Create the kernel we'd like to execute on Infleqtion.
@cudaq.kernel
def kernel():
qvector = cudaq.qvector(2)
h(qvector[0])
x.ctrl(qvector[0], qvector[1])
mz(qvector)
# Note: All measurements must be terminal when performing the sampling.
# Execute on Infleqtion and print out the results.
# Option A (recommended):
# By using the asynchronous `cudaq.sample_async`, the remaining
# classical code will be executed while the job is being handled
# by the Superstaq API. This is ideal when submitting via a queue
# over the cloud.
async_results = cudaq.sample_async(kernel)
# ... more classical code to run ...
# We can either retrieve the results later in the program with
# ```
# async_counts = async_results.get()
# ```
# or we can also write the job reference (`async_results`) to
# a file and load it later or from a different process.
file = open("future.txt", "w")
file.write(str(async_results))
file.close()
# We can later read the file content and retrieve the job
# information and results.
same_file = open("future.txt", "r")
retrieved_async_results = cudaq.AsyncSampleResult(str(same_file.read()))
counts = retrieved_async_results.get()
print(counts)
# Option B:
# By using the synchronous `cudaq.sample`, the execution of
# any remaining classical code in the file will occur only
# after the job has been returned from Superstaq.
counts = cudaq.sample(kernel)
print(counts)
// Compile and run with:
// ```
// nvq++ --target infleqtion infleqtion.cpp -o out.x && ./out.x
// ```
// This will submit the job to the Infleqtion's ideal simulator,
// cq_sqale_simulator (default). Alternatively, we can enable hardware noise
// model simulation by specifying `noise-sim` to the flag `--infleqtion-method`,
// e.g.,
// ```
// nvq++ --target infleqtion --infleqtion-machine cq_sqale_qpu
// --infleqtion-method noise-sim infleqtion.cpp -o out.x && ./out.x
// ```
// where "noise-sim" instructs Superstaq to perform a noisy emulation of the
// QPU. An ideal dry-run execution on the QPU may be performed by passing
// `dry-run` to the `--infleqtion-method` flag, e.g.,
// ```
// nvq++ --target infleqtion --infleqtion-machine cq_sqale_qpu
// --infleqtion-method dry-run infleqtion.cpp -o out.x && ./out.x
// ```
// Note: If targeting ideal cloud simulation, `--infleqtion-machine
// cq_sqale_simulator` is optional since it is the default configuration if not
// provided.
#include <cudaq.h>
#include <fstream>
// Define a simple quantum kernel to execute on Infleqtion backends.
struct ghz {
// Maximally entangled state between 5 qubits.
auto operator()() __qpu__ {
cudaq::qvector q(5);
h(q[0]);
for (int i = 0; i < 4; i++) {
x<cudaq::ctrl>(q[i], q[i + 1]);
}
auto result = mz(q);
}
};
int main() {
// Submit to infleqtion asynchronously (e.g., continue executing
// code in the file until the job has been returned).
auto future = cudaq::sample_async(ghz{});
// ... classical code to execute in the meantime ...
// Can write the future to file:
{
std::ofstream out("saveMe.json");
out << future;
}
// Then come back and read it in later.
cudaq::async_result<cudaq::sample_result> readIn;
std::ifstream in("saveMe.json");
in >> readIn;
// Get the results of the read in future.
auto async_counts = readIn.get();
async_counts.dump();
// OR: Submit to infleqtion synchronously (e.g., wait for the job
// result to be returned before proceeding).
auto counts = cudaq::sample(ghz{});
counts.dump();
}
IonQ¶
The following code illustrates how to run kernels on IonQ’s backends.
import cudaq
# You only have to set the target once! No need to redefine it
# for every execution call on your kernel.
# To use different targets in the same file, you must update
# it via another call to `cudaq.set_target()`
cudaq.set_target("ionq")
# Create the kernel we'd like to execute on IonQ.
@cudaq.kernel
def kernel():
qvector = cudaq.qvector(2)
h(qvector[0])
x.ctrl(qvector[0], qvector[1])
# Note: All qubits will be measured at the end upon performing
# the sampling. You may encounter a pre-flight error on IonQ
# backends if you include explicit measurements.
# Execute on IonQ and print out the results.
# Option A:
# By using the asynchronous `cudaq.sample_async`, the remaining
# classical code will be executed while the job is being handled
# by IonQ. This is ideal when submitting via a queue over
# the cloud.
async_results = cudaq.sample_async(kernel)
# ... more classical code to run ...
# We can either retrieve the results later in the program with
# ```
# async_counts = async_results.get()
# ```
# or we can also write the job reference (`async_results`) to
# a file and load it later or from a different process.
file = open("future.txt", "w")
file.write(str(async_results))
file.close()
# We can later read the file content and retrieve the job
# information and results.
same_file = open("future.txt", "r")
retrieved_async_results = cudaq.AsyncSampleResult(str(same_file.read()))
counts = retrieved_async_results.get()
print(counts)
# Option B:
# By using the synchronous `cudaq.sample`, the execution of
# any remaining classical code in the file will occur only
# after the job has been returned from IonQ.
counts = cudaq.sample(kernel)
print(counts)
// Compile and run with:
// ```
// nvq++ --target ionq ionq.cpp -o out.x && ./out.x
// ```
// This will submit the job to the IonQ ideal simulator target (default).
// Alternatively, we can enable hardware noise model simulation by specifying
// the `--ionq-noise-model`, e.g.,
// ```
// nvq++ --target ionq --ionq-machine simulator --ionq-noise-model aria-1
// ionq.cpp -o out.x && ./out.x
// ```
// where we set the noise model to mimic the 'aria-1' hardware device.
// Please refer to your IonQ Cloud dashboard for the list of simulator noise
// models.
// Note: `--ionq-machine simulator` is optional since 'simulator' is the
// default configuration if not provided. Assumes a valid set of credentials
// have been stored.
#include <cudaq.h>
#include <fstream>
// Define a simple quantum kernel to execute on IonQ.
struct ghz {
// Maximally entangled state between 5 qubits.
auto operator()() __qpu__ {
cudaq::qvector q(5);
h(q[0]);
for (int i = 0; i < 4; i++) {
x<cudaq::ctrl>(q[i], q[i + 1]);
}
auto result = mz(q);
}
};
int main() {
// Submit to IonQ asynchronously (e.g., continue executing
// code in the file until the job has been returned).
auto future = cudaq::sample_async(ghz{});
// ... classical code to execute in the meantime ...
// Can write the future to file:
{
std::ofstream out("saveMe.json");
out << future;
}
// Then come back and read it in later.
cudaq::async_result<cudaq::sample_result> readIn;
std::ifstream in("saveMe.json");
in >> readIn;
// Get the results of the read in future.
auto async_counts = readIn.get();
async_counts.dump();
// OR: Submit to IonQ synchronously (e.g., wait for the job
// result to be returned before proceeding).
auto counts = cudaq::sample(ghz{});
counts.dump();
}
IQM¶
The following code illustrates how to run kernels on IQM’s backends.
import cudaq
# You only have to set the target once! No need to redefine it
# for every execution call on your kernel.
# To use different targets in the same file, you must update
# it via another call to `cudaq.set_target()`
cudaq.set_target("iqm",
url="http://localhost/cocos",
**{"qpu-architecture": "Adonis"})
# Adonis QPU architecture:
# QB1
# |
# QB2 - QB3 - QB4
# |
# QB5
# Create the kernel we'd like to execute on IQM.
@cudaq.kernel
def kernel():
qvector = cudaq.qvector(5)
h(qvector[2]) # QB3
x.ctrl(qvector[2], qvector[0])
mz(qvector)
# Execute on IQM Server and print out the results.
# Option A:
# By using the asynchronous `cudaq.sample_async`, the remaining
# classical code will be executed while the job is being handled
# by IQM Server. This is ideal when submitting via a queue over
# the cloud.
async_results = cudaq.sample_async(kernel)
# ... more classical code to run ...
# We can either retrieve the results later in the program with
# ```
# async_counts = async_results.get()
# ```
# or we can also write the job reference (`async_results`) to
# a file and load it later or from a different process.
file = open("future.txt", "w")
file.write(str(async_results))
file.close()
# We can later read the file content and retrieve the job
# information and results.
same_file = open("future.txt", "r")
retrieved_async_results = cudaq.AsyncSampleResult(str(same_file.read()))
counts = retrieved_async_results.get()
print(counts)
# Option B:
# By using the synchronous `cudaq.sample`, the execution of
# any remaining classical code in the file will occur only
# after the job has been returned from IQM Server.
counts = cudaq.sample(kernel)
print(counts)
// Compile and run with:
// ```
// nvq++ --target iqm iqm.cpp --iqm-machine Adonis -o out.x && ./out.x
// ```
// Assumes a valid set of credentials have been stored.
#include <cudaq.h>
#include <fstream>
// Define a simple quantum kernel to execute on IQM Server.
struct adonis_ghz {
// Maximally entangled state between 5 qubits on Adonis QPU.
// QB1
// |
// QB2 - QB3 - QB4
// |
// QB5
void operator()() __qpu__ {
cudaq::qvector q(5);
h(q[0]);
// Note that the CUDA-Q compiler will automatically generate the
// necessary instructions to swap qubits to satisfy the required
// connectivity constraints for the Adonis QPU. In this program, that means
// that despite QB1 not being physically connected to QB2, the user can
// still perform joint operations q[0] and q[1] because the compiler will
// automatically (and transparently) inject the necessary swap instructions
// to execute the user's program without the user having to worry about the
// physical constraints.
for (int i = 0; i < 4; i++) {
x<cudaq::ctrl>(q[i], q[i + 1]);
}
auto result = mz(q);
}
};
int main() {
// Submit to IQM Server asynchronously. E.g, continue executing
// code in the file until the job has been returned.
auto future = cudaq::sample_async(adonis_ghz{});
// ... classical code to execute in the meantime ...
// Can write the future to file:
{
std::ofstream out("saveMe.json");
out << future;
}
// Then come back and read it in later.
cudaq::async_result<cudaq::sample_result> readIn;
std::ifstream in("saveMe.json");
in >> readIn;
// Get the results of the read in future.
auto async_counts = readIn.get();
async_counts.dump();
// OR: Submit to IQM Server synchronously. E.g, wait for the job
// result to be returned before proceeding.
auto counts = cudaq::sample(adonis_ghz{});
counts.dump();
}
OQC¶
The following code illustrates how to run kernels on OQC’s backends.
import cudaq
# You only have to set the target once! No need to redefine it
# for every execution call on your kernel.
# To use different targets in the same file, you must update
# it via another call to `cudaq.set_target()`
# To use the OQC target you will need to set the following environment variables
# OQC_URL
# OQC_EMAIL
# OQC_PASSWORD
# To setup an account, contact oqc_qcaas_support@oxfordquantumcircuits.com
cudaq.set_target("oqc")
# Create the kernel we'd like to execute on OQC.
@cudaq.kernel
def kernel():
qvector = cudaq.qvector(2)
h(qvector[0])
x.ctrl[qvector[1], qvector[1]]
mz(qvector)
# Option A:
# By using the asynchronous `cudaq.sample_async`, the remaining
# classical code will be executed while the job is being handled
# by OQC. This is ideal when submitting via a queue over
# the cloud.
async_results = cudaq.sample_async(kernel)
# ... more classical code to run ...
# We can either retrieve the results later in the program with
# ```
# async_counts = async_results.get()
# ```
# or we can also write the job reference (`async_results`) to
# a file and load it later or from a different process.
file = open("future.txt", "w")
file.write(str(async_results))
file.close()
# We can later read the file content and retrieve the job
# information and results.
same_file = open("future.txt", "r")
retrieved_async_results = cudaq.AsyncSampleResult(str(same_file.read()))
counts = retrieved_async_results.get()
print(counts)
# Option B:
# By using the synchronous `cudaq.sample`, the execution of
# any remaining classical code in the file will occur only
# after the job has been returned from OQC.
counts = cudaq.sample(kernel)
print(counts)
ORCA Computing¶
The following code illustrates how to run kernels on ORCA Computing’s backends.
ORCA Computing’s PT Series implement the boson sampling model of quantum computation, in which multiple photons are interfered with each other within a network of beam splitters, and photon detectors measure where the photons leave this network.
The following image shows the schematic of a Time Bin Interferometer (TBI) boson sampling experiment that runs on ORCA Computing’s backends. A TBI uses optical delay lines with reconfigurable coupling parameters. A TBI can be represented by a circuit diagram, like the one below, where this illustration example corresponds to 4 photons in 8 modes sent into alternating time-bins in a circuit composed of two delay lines in series.
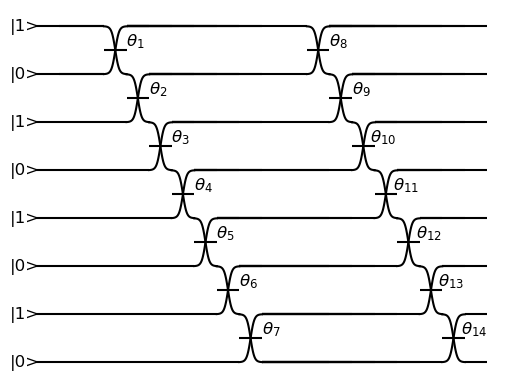
The parameters needed to define the time bin interferometer are the the input state, the loop lengths, beam splitter angles, and optionally the phase shifter angles, and the number of samples. The input state is the initial state of the photons in the time bin interferometer, the left-most entry corresponds to the first mode entering the loop. The loop lengths are the lengths of the different loops in the time bin interferometer. The beam splitter angles and the phase shifter angles are controllable parameters of the time bin interferometer.
This experiment is performed on ORCA’s backends by the code below.
import cudaq
import time
import numpy as np
import os
# You only have to set the target once! No need to redefine it
# for every execution call on your kernel.
# To use different targets in the same file, you must update
# it via another call to `cudaq.set_target()`
# To use the ORCA Computing target you will need to set the ORCA_ACCESS_URL
# environment variable or pass a URL.
orca_url = os.getenv("ORCA_ACCESS_URL", "http://localhost/sample")
cudaq.set_target("orca", url=orca_url)
# A time-bin boson sampling experiment: An input state of 4 indistinguishable
# photons mixed with 4 vacuum states across 8 time bins (modes) enter the
# time bin interferometer (TBI). The interferometer is composed of two loops
# each with a beam splitter (and optionally with a corresponding phase
# shifter). Each photon can either be stored in a loop to interfere with the
# next photon or exit the loop to be measured. Since there are 8 time bins
# and 2 loops, there is a total of 14 beam splitters (and optionally 14 phase
# shifters) in the interferometer, which is the number of controllable
# parameters.
# half of 8 time bins is filled with a single photon and the other half is
# filled with the vacuum state (empty)
input_state = [1, 0, 1, 0, 1, 0, 1, 0]
# The time bin interferometer in this example has two loops, each of length 1
loop_lengths = [1, 1]
# Calculate the number of beam splitters and phase shifters
n_beam_splitters = len(loop_lengths) * len(input_state) - sum(loop_lengths)
# beam splitter angles
bs_angles = np.linspace(np.pi / 3, np.pi / 6, n_beam_splitters)
# Optionally, we can also specify the phase shifter angles, if the system
# includes phase shifters
# ```
# ps_angles = np.linspace(np.pi / 3, np.pi / 5, n_beam_splitters)
# ```
# we can also set number of requested samples
n_samples = 10000
# Option A:
# By using the synchronous `cudaq.orca.sample`, the execution of
# any remaining classical code in the file will occur only
# after the job has been returned from ORCA Server.
print("Submitting to ORCA Server synchronously")
counts = cudaq.orca.sample(input_state, loop_lengths, bs_angles, n_samples)
# If the system includes phase shifters, the phase shifter angles can be
# included in the call
# ```
# counts = cudaq.orca.sample(input_state, loop_lengths, bs_angles, ps_angles,
# n_samples)
# ```
# Print the results
print(counts)
# Option B:
# By using the asynchronous `cudaq.orca.sample_async`, the remaining
# classical code will be executed while the job is being handled
# by Orca. This is ideal when submitting via a queue over
# the cloud.
print("Submitting to ORCA Server asynchronously")
async_results = cudaq.orca.sample_async(input_state, loop_lengths, bs_angles,
n_samples)
# ... more classical code to run ...
# We can either retrieve the results later in the program with
# ```
# async_counts = async_results.get()
# ```
# or we can also write the job reference (`async_results`) to
# a file and load it later or from a different process.
file = open("future.txt", "w")
file.write(str(async_results))
file.close()
# We can later read the file content and retrieve the job
# information and results.
time.sleep(0.2) # wait for the job to be processed
same_file = open("future.txt", "r")
retrieved_async_results = cudaq.AsyncSampleResult(str(same_file.read()))
counts = retrieved_async_results.get()
print(counts)
// Compile and run with:
// ```
// nvq++ --target orca --orca-url $ORCA_ACCESS_URL orca.cpp -o out.x && ./out.x
// ```
// To use the ORCA Computing target you will need to set the ORCA_ACCESS_URL
// environment variable or pass the URL to the `--orca-url` flag.
#include <chrono>
#include <cudaq.h>
#include <cudaq/orca.h>
#include <fstream>
#include <iostream>
#include <thread>
int main() {
using namespace std::this_thread; // sleep_for, sleep_until
using namespace std::chrono_literals; // `ns`, `us`, `ms`, `s`, `h`, etc.
// A time-bin boson sampling experiment: An input state of 4 indistinguishable
// photons mixed with 4 vacuum states across 8 time bins (modes) enter the
// time bin interferometer (TBI). The interferometer is composed of two loops
// each with a beam splitter (and optionally with a corresponding phase
// shifter). Each photon can either be stored in a loop to interfere with the
// next photon or exit the loop to be measured. Since there are 8 time bins
// and 2 loops, there is a total of 14 beam splitters (and optionally 14 phase
// shifters) in the interferometer, which is the number of controllable
// parameters.
// half of 8 time bins is filled with a single photon and the other half is
// filled with the vacuum state (empty)
std::vector<std::size_t> input_state = {1, 0, 1, 0, 1, 0, 1, 0};
// The time bin interferometer in this example has two loops, each of length 1
std::vector<std::size_t> loop_lengths = {1, 1};
// helper variables to calculate the number of beam splitters and phase
// shifters needed in the TBI
std::size_t sum_loop_lengths{std::accumulate(
loop_lengths.begin(), loop_lengths.end(), static_cast<std::size_t>(0))};
const std::size_t n_loops = loop_lengths.size();
const std::size_t n_modes = input_state.size();
const std::size_t n_beam_splitters = n_loops * n_modes - sum_loop_lengths;
// beam splitter angles (created as a linear spaced vector of angles)
std::vector<double> bs_angles =
cudaq::linspace(M_PI / 3, M_PI / 6, n_beam_splitters);
// Optionally, we can also specify the phase shifter angles (created as a
// linear spaced vector of angles), if the system includes phase shifters
// ```
// std::vector<double> ps_angles = cudaq::linspace(M_PI / 3, M_PI / 5,
// n_beam_splitters);
// ```
// we can also set number of requested samples
int n_samples = 10000;
// Submit to ORCA synchronously (e.g., wait for the job result to be
// returned before proceeding with the rest of the execution).
std::cout << "Submitting to ORCA Server synchronously" << std::endl;
auto counts =
cudaq::orca::sample(input_state, loop_lengths, bs_angles, n_samples);
// Print the results
counts.dump();
// If the system includes phase shifters, the phase shifter angles can be
// included in the call
// ```
// auto counts = cudaq::orca::sample(input_state, loop_lengths, bs_angles,
// ps_angles, n_samples);
// ```
// Alternatively we can submit to ORCA asynchronously (e.g., continue
// executing code in the file until the job has been returned).
std::cout << "Submitting to ORCA Server asynchronously" << std::endl;
auto async_results = cudaq::orca::sample_async(input_state, loop_lengths,
bs_angles, n_samples);
// Can write the future to file:
{
std::ofstream out("saveMe.json");
out << async_results;
}
// Then come back and read it in later.
cudaq::async_result<cudaq::sample_result> readIn;
std::ifstream in("saveMe.json");
in >> readIn;
sleep_for(200ms); // wait for the job to be processed
// Get the results of the read in future.
auto async_counts = readIn.get();
async_counts.dump();
return 0;
}
Quantinuum¶
The following code illustrates how to run kernels on Quantinuum’s backends.
import cudaq
# You only have to set the target once! No need to redefine it
# for every execution call on your kernel.
# By default, we will submit to the Quantinuum syntax checker.
cudaq.set_target("quantinuum")
# Create the kernel we'd like to execute on Quantinuum.
@cudaq.kernel
def kernel():
qvector = cudaq.qvector(2)
h(qvector[0])
x.ctrl(qvector[0], qvector[1])
mz(qvector[0])
mz(qvector[1])
# Submit to Quantinuum's endpoint and confirm the program is valid.
# Option A:
# By using the synchronous `cudaq.sample`, the execution of
# any remaining classical code in the file will occur only
# after the job has been executed by the Quantinuum service.
# We will use the synchronous call to submit to the syntax
# checker to confirm the validity of the program.
syntax_check = cudaq.sample(kernel)
if (syntax_check):
print("Syntax check passed! Kernel is ready for submission.")
# Now we can update the target to the Quantinuum emulator and
# execute our program.
cudaq.set_target("quantinuum", machine="H1-2E")
# Option B:
# By using the asynchronous `cudaq.sample_async`, the remaining
# classical code will be executed while the job is being handled
# by Quantinuum. This is ideal when submitting via a queue over
# the cloud.
async_results = cudaq.sample_async(kernel)
# ... more classical code to run ...
# We can either retrieve the results later in the program with
# ```
# async_counts = async_results.get()
# ```
# or we can also write the job reference (`async_results`) to
# a file and load it later or from a different process.
file = open("future.txt", "w")
file.write(str(async_results))
file.close()
# We can later read the file content and retrieve the job
# information and results.
same_file = open("future.txt", "r")
retrieved_async_results = cudaq.AsyncSampleResult(str(same_file.read()))
counts = retrieved_async_results.get()
print(counts)
// Compile and run with:
// ```
// nvq++ --target quantinuum --quantinuum-machine H1-2E quantinuum.cpp -o out.x
// ./out.x
// ```
// Assumes a valid set of credentials have been stored.
// To first confirm the correctness of the program locally,
// Add a --emulate to the `nvq++` command above.
#include <cudaq.h>
#include <fstream>
// Define a simple quantum kernel to execute on Quantinuum.
struct ghz {
// Maximally entangled state between 5 qubits.
auto operator()() __qpu__ {
cudaq::qvector q(5);
h(q[0]);
for (int i = 0; i < 4; i++) {
x<cudaq::ctrl>(q[i], q[i + 1]);
}
mz(q);
}
};
int main() {
// Submit to Quantinuum asynchronously (e.g., continue executing
// code in the file until the job has been returned).
auto future = cudaq::sample_async(ghz{});
// ... classical code to execute in the meantime ...
// Can write the future to file:
{
std::ofstream out("saveMe.json");
out << future;
}
// Then come back and read it in later.
cudaq::async_result<cudaq::sample_result> readIn;
std::ifstream in("saveMe.json");
in >> readIn;
// Get the results of the read in future.
auto async_counts = readIn.get();
async_counts.dump();
// OR: Submit to Quantinuum synchronously (e.g., wait for the job
// result to be returned before proceeding).
auto counts = cudaq::sample(ghz{});
counts.dump();
}
QuEra Computing¶
The following code illustrates how to run kernels on QuEra’s backends.
import cudaq
from cudaq.operator import *
import numpy as np
## NOTE: QuEra Aquila system is available via Amazon Braket.
# Credentials must be set before running this program.
# Amazon Braket costs apply.
# This example illustrates how to use QuEra's Aquila device on Braket with CUDA-Q.
# It is a CUDA-Q implementation of the getting started materials for Braket available here:
# https://docs.aws.amazon.com/braket/latest/developerguide/braket-get-started-hello-ahs.html
cudaq.set_target("quera")
# Define the 2-dimensional atom arrangement
a = 5.7e-6
register = []
register.append(tuple(np.array([0.5, 0.5 + 1 / np.sqrt(2)]) * a))
register.append(tuple(np.array([0.5 + 1 / np.sqrt(2), 0.5]) * a))
register.append(tuple(np.array([0.5 + 1 / np.sqrt(2), -0.5]) * a))
register.append(tuple(np.array([0.5, -0.5 - 1 / np.sqrt(2)]) * a))
register.append(tuple(np.array([-0.5, -0.5 - 1 / np.sqrt(2)]) * a))
register.append(tuple(np.array([-0.5 - 1 / np.sqrt(2), -0.5]) * a))
register.append(tuple(np.array([-0.5 - 1 / np.sqrt(2), 0.5]) * a))
register.append(tuple(np.array([-0.5, 0.5 + 1 / np.sqrt(2)]) * a))
time_max = 4e-6 # seconds
time_ramp = 1e-7 # seconds
omega_max = 6300000.0 # rad / sec
delta_start = -5 * omega_max
delta_end = 5 * omega_max
# Times for the piece-wise linear waveforms
steps = [0.0, time_ramp, time_max - time_ramp, time_max]
schedule = Schedule(steps, ["t"])
# Rabi frequencies at each step
omega = ScalarOperator(lambda t: omega_max if time_ramp < t < time_max else 0.0)
# Global phase at each step
phi = ScalarOperator.const(0.0)
# Global detuning at each step
delta = ScalarOperator(lambda t: delta_end
if time_ramp < t < time_max else delta_start)
async_result = evolve_async(RydbergHamiltonian(atom_sites=register,
amplitude=omega,
phase=phi,
delta_global=delta),
schedule=schedule,
shots_count=10).get()
async_result.dump()
## Sample result
# ```
# {
# __global__ : { 12121222:1 21202221:1 21212121:2 21212122:1 21221212:1 21221221:2 22121221:1 22221221:1 }
# post_sequence : { 01010111:1 10101010:2 10101011:1 10101110:1 10110101:1 10110110:2 11010110:1 11110110:1 }
# pre_sequence : { 11101111:1 11111111:9 }
# }
# ```
## Interpreting result
# `pre_sequence` has the measurement bits, one for each atomic site, before the
# quantum evolution is run. The count is aggregated across shots. The value is
# 0 if site is empty, 1 if site is filled.
# `post_sequence` has the measurement bits, one for each atomic site, at the
# end of the quantum evolution. The count is aggregated across shots. The value
# is 0 if atom is in Rydberg state or site is empty, 1 if atom is in ground
# state.
# `__global__` has the aggregate of the state counts from all the successful
# shots. The value is 0 if site is empty, 1 if atom is in Rydberg state (up
# state spin) and 2 if atom is in ground state (down state spin).