cub::DeviceRadixSort#
-
struct DeviceRadixSort#
DeviceRadixSort provides device-wide, parallel operations for computing a radix sort across a sequence of data items residing within device-accessible memory.
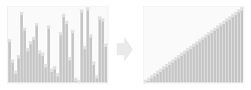
Overview#
The radix sorting method arranges items into ascending (or descending) order. The algorithm relies upon a positional representation for keys, i.e., each key is comprised of an ordered sequence of symbols (e.g., digits, characters, etc.) specified from least-significant to most-significant. For a given input sequence of keys and a set of rules specifying a total ordering of the symbolic alphabet, the radix sorting method produces a lexicographic ordering of those keys.
For multi-dimensional blocks, threads are linearly ranked in row-major order.
Supported Types#
DeviceRadixSort can sort all of the built-in C++ numeric primitive types (
unsigned char,int,double, etc.) as well as CUDA’s__halfand__nv_bfloat1616-bit floating-point types. User-defined types are supported as long as a decomposer object is provided.Floating-Point Special Cases#
Positive and negative zeros are considered equivalent, and will be treated as such in the output.
No special handling is implemented for NaN values; these are sorted according to their bit representations after any transformations.
Transformations#
Although the direct radix sorting method can only be applied to unsigned integral types, DeviceRadixSort is able to sort signed and floating-point types via simple bit-wise transformations that ensure lexicographic key ordering. Additional transformations occur for descending sorts. These transformations must be considered when restricting the
[begin_bit, end_bit)range, as the bitwise transformations will occur before the bit-range truncation.Any transformations applied to the keys prior to sorting are reversed while writing to the final output buffer.
Type Specific Bitwise Transformations#
To convert the input values into a radix-sortable bitwise representation, the following transformations take place prior to sorting:
For unsigned integral values, the keys are used directly.
For signed integral values, the sign bit is inverted.
For positive floating point values, the sign bit is inverted.
For negative floating point values, the full key is inverted.
For floating point types, positive and negative zero are a special case and will be considered equivalent during sorting.
Descending Sort Bitwise Transformations#
If descending sort is used, the keys are inverted after performing any type-specific transformations, and the resulting keys are sorted in ascending order.
Stability#
DeviceRadixSort is stable. For floating-point types,
-0.0and+0.0are considered equal and appear in the result in the same order as they appear in the input.Usage Considerations#
Dynamic parallelism. DeviceRadixSort methods can be called within kernel code on devices in which CUDA dynamic parallelism is supported.
Performance#
The work-complexity of radix sort as a function of input size is linear, resulting in performance throughput that plateaus with problem sizes large enough to saturate the GPU.
KeyT-value pairs
-
template<typename KeyT, typename ValueT, typename NumItemsT>
static inline cudaError_t SortPairs( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- const KeyT *d_keys_in,
- KeyT *d_keys_out,
- const ValueT *d_values_in,
- ValueT *d_values_out,
- NumItemsT num_items,
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8,
- cudaStream_t stream = 0
Sorts key-value pairs into ascending order using \(\approx 2N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The contents of the input data are not altered by the sorting operation.
Pointers to contiguous memory must be used; iterators are not currently supported.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys_in, d_keys_in + num_items)[d_keys_out, d_keys_out + num_items)[d_values_in, d_values_in + num_items)[d_values_out, d_values_out + num_items)
An optional bit subrange
[begin_bit, end_bit)of differentiating key bits can be specified. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires an allocation of temporary device storage that is
O(N+P), whereNis the length of the input andPis the number of streaming multiprocessors on the device. For sorting using onlyO(P)temporary storage, see the sorting interface using DoubleBuffer wrappers below.When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
The code snippet below illustrates the sorting of a device vector of
intkeys with associated vector ofintvalues.#include <cub/cub.cuh> // or equivalently <cub/device/device_radix_sort.cuh> // Declare, allocate, and initialize device-accessible pointers // for sorting data int num_items; // e.g., 7 int *d_keys_in; // e.g., [8, 6, 7, 5, 3, 0, 9] int *d_keys_out; // e.g., [ ... ] int *d_values_in; // e.g., [0, 1, 2, 3, 4, 5, 6] int *d_values_out; // e.g., [ ... ] ... // Determine temporary device storage requirements void *d_temp_storage = nullptr; size_t temp_storage_bytes = 0; cub::DeviceRadixSort::SortPairs(d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, d_values_in, d_values_out, num_items); // Allocate temporary storage cudaMalloc(&d_temp_storage, temp_storage_bytes); // Run sorting operation cub::DeviceRadixSort::SortPairs(d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, d_values_in, d_values_out, num_items); // d_keys_out <-- [0, 3, 5, 6, 7, 8, 9] // d_values_out <-- [5, 4, 3, 1, 2, 0, 6]
- Template Parameters:
KeyT – [inferred] KeyT type
ValueT – [inferred] ValueT type
NumItemsT – [inferred] Type of num_items
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys_in – [in] Pointer to the input data of key data to sort
d_keys_out – [out] Pointer to the sorted output sequence of key data
d_values_in – [in] Pointer to the corresponding input sequence of associated value items
d_values_out – [out] Pointer to the correspondingly-reordered output sequence of associated value items
num_items – [in] Number of items to sort
begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
sizeof(unsigned int) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename ValueT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortPairs( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- const KeyT *d_keys_in,
- KeyT *d_keys_out,
- const ValueT *d_values_in,
- ValueT *d_values_out,
- NumItemsT num_items,
- DecomposerT decomposer,
- int begin_bit,
- int end_bit,
- cudaStream_t stream = 0
Sorts key-value pairs into ascending order using \(\approx 2N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The contents of the input data are not altered by the sorting operation.
Pointers to contiguous memory must be used; iterators are not currently supported.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys_in, d_keys_in + num_items)[d_keys_out, d_keys_out + num_items)[d_values_in, d_values_in + num_items)[d_values_out, d_values_out + num_items)
A bit subrange
[begin_bit, end_bit)is provided to specify differentiating key bits. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires an allocation of temporary device storage that is
O(N+P), whereNis the length of the input andPis the number of streaming multiprocessors on the device. For sorting using only \(O(P)\) temporary storage, see the sorting interface using DoubleBuffer wrappers below.When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortPairs:constexpr int num_items = 2; c2h::device_vector<custom_t> keys_in = { {24.2f, 1ll << 61}, // {42.4f, 1ll << 60} // }; c2h::device_vector<int> vals_in = {1, 0}; constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000001110000011001100110011010 00100000000000...0000 // decompose(in[1]) = 01000010001010011001100110011010 00010000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> c2h::device_vector<custom_t> keys_out(num_items); c2h::device_vector<int> vals_out(num_items); const custom_t* d_keys_in = thrust::raw_pointer_cast(keys_in.data()); custom_t* d_keys_out = thrust::raw_pointer_cast(keys_out.data()); const int* d_vals_in = thrust::raw_pointer_cast(vals_in.data()); int* d_vals_out = thrust::raw_pointer_cast(vals_out.data()); // 1) Get temp storage size std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; cub::DeviceRadixSort::SortPairs( d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, d_vals_in, d_vals_out, num_items, decomposer_t{}, begin_bit, end_bit); // 2) Allocate temp storage c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); // 3) Sort keys cub::DeviceRadixSort::SortPairs( d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, d_vals_in, d_vals_out, num_items, decomposer_t{}, begin_bit, end_bit); c2h::device_vector<custom_t> expected_keys = { {42.4f, 1ll << 60}, // {24.2f, 1ll << 61} // }; c2h::device_vector<int> expected_vals = {0, 1};
- Template Parameters:
KeyT – [inferred] KeyT type
ValueT – [inferred] ValueT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys_in – [in] Pointer to the input data of key data to sort
d_keys_out – [out] Pointer to the sorted output sequence of key data
d_values_in – [in] Pointer to the corresponding input sequence of associated value items
d_values_out – [out] Pointer to the correspondingly-reordered output sequence of associated value items
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename ValueT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortPairs( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- const KeyT *d_keys_in,
- KeyT *d_keys_out,
- const ValueT *d_values_in,
- ValueT *d_values_out,
- NumItemsT num_items,
- DecomposerT decomposer,
- cudaStream_t stream = 0
Sorts key-value pairs into ascending order using \(\approx 2N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The contents of the input data are not altered by the sorting operation.
Pointers to contiguous memory must be used; iterators are not currently supported.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys_in, d_keys_in + num_items)[d_keys_out, d_keys_out + num_items)[d_values_in, d_values_in + num_items)[d_values_out, d_values_out + num_items)
This operation requires an allocation of temporary device storage that is
O(N+P), whereNis the length of the input andPis the number of streaming multiprocessors on the device. For sorting using only \(O(P)\) temporary storage, see the sorting interface using DoubleBuffer wrappers below.When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortPairs:std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; constexpr int num_items = 6; c2h::device_vector<custom_t> keys_in = { {+2.5f, 4}, // {-2.5f, 0}, // {+1.1f, 3}, // {+0.0f, 1}, // {-0.0f, 2}, // {+3.7f, 5} // }; c2h::device_vector<custom_t> keys_out(num_items); const custom_t* d_keys_in = thrust::raw_pointer_cast(keys_in.data()); custom_t* d_keys_out = thrust::raw_pointer_cast(keys_out.data()); c2h::device_vector<int> vals_in = {4, 0, 3, 1, 2, 5}; c2h::device_vector<int> vals_out(num_items); const int* d_vals_in = thrust::raw_pointer_cast(vals_in.data()); int* d_vals_out = thrust::raw_pointer_cast(vals_out.data()); cub::DeviceRadixSort::SortPairs( d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, d_vals_in, d_vals_out, num_items, decomposer_t{}); c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); cub::DeviceRadixSort::SortPairs( d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, d_vals_in, d_vals_out, num_items, decomposer_t{}); c2h::device_vector<custom_t> expected_keys = { {-2.5f, 0}, // {+0.0f, 1}, // {-0.0f, 2}, // {+1.1f, 3}, // {+2.5f, 4}, // {+3.7f, 5} // }; c2h::device_vector<int> expected_vals = {0, 1, 2, 3, 4, 5};
- Template Parameters:
KeyT – [inferred] KeyT type
ValueT – [inferred] ValueT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys_in – [in] Pointer to the input data of key data to sort
d_keys_out – [out] Pointer to the sorted output sequence of key data
d_values_in – [in] Pointer to the corresponding input sequence of associated value items
d_values_out – [out] Pointer to the correspondingly-reordered output sequence of associated value items
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename ValueT, typename NumItemsT>
static inline cudaError_t SortPairs( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- DoubleBuffer<KeyT> &d_keys,
- DoubleBuffer<ValueT> &d_values,
- NumItemsT num_items,
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8,
- cudaStream_t stream = 0
Sorts key-value pairs into ascending order using \(\approx N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The sorting operation is given a pair of key buffers and a corresponding pair of associated value buffers. Each pair is managed by a DoubleBuffer structure that indicates which of the two buffers is “current” (and thus contains the input data to be sorted).
The contents of both buffers within each pair may be altered by the sorting operation.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys.Current(), d_keys.Current() + num_items)[d_keys.Alternate(), d_keys.Alternate() + num_items)[d_values.Current(), d_values.Current() + num_items)[d_values.Alternate(), d_values.Alternate() + num_items)
Upon completion, the sorting operation will update the “current” indicator within each DoubleBuffer wrapper to reference which of the two buffers now contains the sorted output sequence (a function of the number of key bits specified and the targeted device architecture).
An optional bit subrange
[begin_bit, end_bit)of differentiating key bits can be specified. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires a relatively small allocation of temporary device storage that is
O(P), wherePis the number of streaming multiprocessors on the device (and is typically a small constant relative to the input sizeN).When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
The code snippet below illustrates the sorting of a device vector of
intkeys with associated vector ofintvalues.#include <cub/cub.cuh> // or equivalently <cub/device/device_radix_sort.cuh> // Declare, allocate, and initialize device-accessible pointers for // sorting data int num_items; // e.g., 7 int *d_key_buf; // e.g., [8, 6, 7, 5, 3, 0, 9] int *d_key_alt_buf; // e.g., [ ... ] int *d_value_buf; // e.g., [0, 1, 2, 3, 4, 5, 6] int *d_value_alt_buf; // e.g., [ ... ] ... // Create a set of DoubleBuffers to wrap pairs of device pointers cub::DoubleBuffer<int> d_keys(d_key_buf, d_key_alt_buf); cub::DoubleBuffer<int> d_values(d_value_buf, d_value_alt_buf); // Determine temporary device storage requirements void *d_temp_storage = nullptr; size_t temp_storage_bytes = 0; cub::DeviceRadixSort::SortPairs( d_temp_storage, temp_storage_bytes, d_keys, d_values, num_items); // Allocate temporary storage cudaMalloc(&d_temp_storage, temp_storage_bytes); // Run sorting operation cub::DeviceRadixSort::SortPairs( d_temp_storage, temp_storage_bytes, d_keys, d_values, num_items); // d_keys.Current() <-- [0, 3, 5, 6, 7, 8, 9] // d_values.Current() <-- [5, 4, 3, 1, 2, 0, 6]
- Template Parameters:
KeyT – [inferred] KeyT type
ValueT – [inferred] ValueT type
NumItemsT – [inferred] Type of num_items
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys – [inout] Reference to the double-buffer of keys whose “current” device-accessible buffer contains the unsorted input keys and, upon return, is updated to point to the sorted output keys
d_values – [inout] Double-buffer of values whose “current” device-accessible buffer contains the unsorted input values and, upon return, is updated to point to the sorted output values
num_items – [in] Number of items to sort
begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
sizeof(unsigned int) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename ValueT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortPairs( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- DoubleBuffer<KeyT> &d_keys,
- DoubleBuffer<ValueT> &d_values,
- NumItemsT num_items,
- DecomposerT decomposer,
- cudaStream_t stream = 0
Sorts key-value pairs into ascending order using \(\approx N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The sorting operation is given a pair of key buffers and a corresponding pair of associated value buffers. Each pair is managed by a DoubleBuffer structure that indicates which of the two buffers is “current” (and thus contains the input data to be sorted).
The contents of both buffers within each pair may be altered by the sorting operation.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys.Current(), d_keys.Current() + num_items)[d_keys.Alternate(), d_keys.Alternate() + num_items)[d_values.Current(), d_values.Current() + num_items)[d_values.Alternate(), d_values.Alternate() + num_items)
Upon completion, the sorting operation will update the “current” indicator within each DoubleBuffer wrapper to reference which of the two buffers now contains the sorted output sequence (a function of the number of key bits specified and the targeted device architecture).
This operation requires a relatively small allocation of temporary device storage that is
O(P), wherePis the number of streaming multiprocessors on the device (and is typically a small constant relative to the input sizeN).When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortPairs:std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; constexpr int num_items = 6; c2h::device_vector<custom_t> keys_buf = { {+2.5f, 4}, // {-2.5f, 0}, // {+1.1f, 3}, // {+0.0f, 1}, // {-0.0f, 2}, // {+3.7f, 5} // }; c2h::device_vector<custom_t> keys_alt_buf(num_items); custom_t* d_keys_buf = thrust::raw_pointer_cast(keys_buf.data()); custom_t* d_keys_alt_buf = thrust::raw_pointer_cast(keys_alt_buf.data()); c2h::device_vector<int> vals_buf = {4, 0, 3, 1, 2, 5}; c2h::device_vector<int> vals_alt_buf(num_items); int* d_vals_buf = thrust::raw_pointer_cast(vals_buf.data()); int* d_vals_alt_buf = thrust::raw_pointer_cast(vals_alt_buf.data()); cub::DoubleBuffer<custom_t> d_keys(d_keys_buf, d_keys_alt_buf); cub::DoubleBuffer<int> d_vals(d_vals_buf, d_vals_alt_buf); cub::DeviceRadixSort::SortPairs(d_temp_storage, temp_storage_bytes, d_keys, d_vals, num_items, decomposer_t{}); c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); cub::DeviceRadixSort::SortPairs(d_temp_storage, temp_storage_bytes, d_keys, d_vals, num_items, decomposer_t{}); c2h::device_vector<custom_t>& current_keys = // d_keys.Current() == d_keys_buf ? keys_buf : keys_alt_buf; c2h::device_vector<int>& current_vals = // d_vals.Current() == d_vals_buf ? vals_buf : vals_alt_buf; c2h::device_vector<custom_t> expected_keys = { {-2.5f, 0}, // {+0.0f, 1}, // {-0.0f, 2}, // {+1.1f, 3}, // {+2.5f, 4}, // {+3.7f, 5} // }; c2h::device_vector<int> expected_vals = {0, 1, 2, 3, 4, 5};
- Template Parameters:
KeyT – [inferred] KeyT type
ValueT – [inferred] ValueT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys – [inout] Reference to the double-buffer of keys whose “current” device-accessible buffer contains the unsorted input keys and, upon return, is updated to point to the sorted output keys
d_values – [inout] Double-buffer of values whose “current” device-accessible buffer contains the unsorted input values and, upon return, is updated to point to the sorted output values
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename ValueT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortPairs( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- DoubleBuffer<KeyT> &d_keys,
- DoubleBuffer<ValueT> &d_values,
- NumItemsT num_items,
- DecomposerT decomposer,
- int begin_bit,
- int end_bit,
- cudaStream_t stream = 0
Sorts key-value pairs into ascending order using \(\approx N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The sorting operation is given a pair of key buffers and a corresponding pair of associated value buffers. Each pair is managed by a DoubleBuffer structure that indicates which of the two buffers is “current” (and thus contains the input data to be sorted).
The contents of both buffers within each pair may be altered by the sorting operation.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys.Current(), d_keys.Current() + num_items)[d_keys.Alternate(), d_keys.Alternate() + num_items)[d_values.Current(), d_values.Current() + num_items)[d_values.Alternate(), d_values.Alternate() + num_items)
Upon completion, the sorting operation will update the “current” indicator within each DoubleBuffer wrapper to reference which of the two buffers now contains the sorted output sequence (a function of the number of key bits specified and the targeted device architecture).
An optional bit subrange
[begin_bit, end_bit)of differentiating key bits can be specified. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires a relatively small allocation of temporary device storage that is
O(P), wherePis the number of streaming multiprocessors on the device (and is typically a small constant relative to the input sizeN).When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortPairs:constexpr int num_items = 2; c2h::device_vector<custom_t> keys_buf = { {24.2f, 1ll << 61}, // {42.4f, 1ll << 60} // }; c2h::device_vector<int> vals_buf = {1, 0}; constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000001110000011001100110011010 00100000000000...0000 // decompose(in[1]) = 01000010001010011001100110011010 00010000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> c2h::device_vector<custom_t> keys_alt_buf(num_items); c2h::device_vector<int> vals_alt_buf(num_items); custom_t* d_keys_buf = thrust::raw_pointer_cast(keys_buf.data()); custom_t* d_keys_alt_buf = thrust::raw_pointer_cast(keys_alt_buf.data()); int* d_vals_buf = thrust::raw_pointer_cast(vals_buf.data()); int* d_vals_alt_buf = thrust::raw_pointer_cast(vals_alt_buf.data()); cub::DoubleBuffer<custom_t> d_keys(d_keys_buf, d_keys_alt_buf); cub::DoubleBuffer<int> d_vals(d_vals_buf, d_vals_alt_buf); // 1) Get temp storage size std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; cub::DeviceRadixSort::SortPairs( d_temp_storage, temp_storage_bytes, d_keys, d_vals, num_items, decomposer_t{}, begin_bit, end_bit); // 2) Allocate temp storage c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); // 3) Sort keys cub::DeviceRadixSort::SortPairs( d_temp_storage, temp_storage_bytes, d_keys, d_vals, num_items, decomposer_t{}, begin_bit, end_bit); c2h::device_vector<custom_t>& current_keys = // d_keys.Current() == d_keys_buf ? keys_buf : keys_alt_buf; c2h::device_vector<int>& current_vals = // d_vals.Current() == d_vals_buf ? vals_buf : vals_alt_buf; c2h::device_vector<custom_t> expected_keys = { {42.4f, 1ll << 60}, // {24.2f, 1ll << 61} // }; c2h::device_vector<int> expected_vals = {0, 1};
- Template Parameters:
KeyT – [inferred] KeyT type
ValueT – [inferred] ValueT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys – [inout] Reference to the double-buffer of keys whose “current” device-accessible buffer contains the unsorted input keys and, upon return, is updated to point to the sorted output keys
d_values – [inout] Double-buffer of values whose “current” device-accessible buffer contains the unsorted input values and, upon return, is updated to point to the sorted output values
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename ValueT, typename NumItemsT>
static inline cudaError_t SortPairsDescending( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- const KeyT *d_keys_in,
- KeyT *d_keys_out,
- const ValueT *d_values_in,
- ValueT *d_values_out,
- NumItemsT num_items,
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8,
- cudaStream_t stream = 0
Sorts key-value pairs into descending order using \(\approx 2N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The contents of the input data are not altered by the sorting operation.
Pointers to contiguous memory must be used; iterators are not currently supported.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys_in, d_keys_in + num_items)[d_keys_out, d_keys_out + num_items)[d_values_in, d_values_in + num_items)[d_values_out, d_values_out + num_items)
An optional bit subrange
[begin_bit, end_bit)of differentiating key bits can be specified. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires an allocation of temporary device storage that is
O(N+P), whereNis the length of the input andPis the number of streaming multiprocessors on the device. For sorting using onlyO(P)temporary storage, see the sorting interface using DoubleBuffer wrappers below.When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
The code snippet below illustrates the sorting of a device vector of
intkeys with associated vector ofintvalues.#include <cub/cub.cuh> // or equivalently <cub/device/device_radix_sort.cuh> // Declare, allocate, and initialize device-accessible pointers // for sorting data int num_items; // e.g., 7 int *d_keys_in; // e.g., [8, 6, 7, 5, 3, 0, 9] int *d_keys_out; // e.g., [ ... ] int *d_values_in; // e.g., [0, 1, 2, 3, 4, 5, 6] int *d_values_out; // e.g., [ ... ] ... // Determine temporary device storage requirements void *d_temp_storage = nullptr; size_t temp_storage_bytes = 0; cub::DeviceRadixSort::SortPairsDescending( d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, d_values_in, d_values_out, num_items); // Allocate temporary storage cudaMalloc(&d_temp_storage, temp_storage_bytes); // Run sorting operation cub::DeviceRadixSort::SortPairsDescending( d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, d_values_in, d_values_out, num_items); // d_keys_out <-- [9, 8, 7, 6, 5, 3, 0] // d_values_out <-- [6, 0, 2, 1, 3, 4, 5]
- Template Parameters:
KeyT – [inferred] KeyT type
ValueT – [inferred] ValueT type
NumItemsT – [inferred] Type of num_items
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys_in – [in] Pointer to the input data of key data to sort
d_keys_out – [out] Pointer to the sorted output sequence of key data
d_values_in – [in] Pointer to the corresponding input sequence of associated value items
d_values_out – [out] Pointer to the correspondingly-reordered output sequence of associated value items
num_items – [in] Number of items to sort
begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
sizeof(unsigned int) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename ValueT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortPairsDescending( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- const KeyT *d_keys_in,
- KeyT *d_keys_out,
- const ValueT *d_values_in,
- ValueT *d_values_out,
- NumItemsT num_items,
- DecomposerT decomposer,
- int begin_bit,
- int end_bit,
- cudaStream_t stream = 0
Sorts key-value pairs into descending order using \(\approx 2N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The contents of the input data are not altered by the sorting operation.
Pointers to contiguous memory must be used; iterators are not currently supported.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys_in, d_keys_in + num_items)[d_keys_out, d_keys_out + num_items)[d_values_in, d_values_in + num_items)[d_values_out, d_values_out + num_items)
A bit subrange
[begin_bit, end_bit)is provided to specify differentiating key bits. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires an allocation of temporary device storage that is
O(N+P), whereNis the length of the input andPis the number of streaming multiprocessors on the device. For sorting using only \(O(P)\) temporary storage, see the sorting interface using DoubleBuffer wrappers below.When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortPairsDescending:constexpr int num_items = 2; c2h::device_vector<custom_t> keys_in = { {42.4f, 1ll << 60}, // {24.2f, 1ll << 61} // }; c2h::device_vector<int> vals_in = {1, 0}; constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000010001010011001100110011010 00010000000000...0000 // decompose(in[1]) = 01000001110000011001100110011010 00100000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> c2h::device_vector<custom_t> keys_out(num_items); c2h::device_vector<int> vals_out(num_items); const custom_t* d_keys_in = thrust::raw_pointer_cast(keys_in.data()); custom_t* d_keys_out = thrust::raw_pointer_cast(keys_out.data()); const int* d_vals_in = thrust::raw_pointer_cast(vals_in.data()); int* d_vals_out = thrust::raw_pointer_cast(vals_out.data()); // 1) Get temp storage size std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; cub::DeviceRadixSort::SortPairsDescending( d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, d_vals_in, d_vals_out, num_items, decomposer_t{}, begin_bit, end_bit); // 2) Allocate temp storage c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); // 3) Sort keys cub::DeviceRadixSort::SortPairsDescending( d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, d_vals_in, d_vals_out, num_items, decomposer_t{}, begin_bit, end_bit); c2h::device_vector<custom_t> expected_keys = { {24.2f, 1ll << 61}, // {42.4f, 1ll << 60} // }; c2h::device_vector<int> expected_vals = {0, 1};
- Template Parameters:
KeyT – [inferred] KeyT type
ValueT – [inferred] ValueT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys_in – [in] Pointer to the input data of key data to sort
d_keys_out – [out] Pointer to the sorted output sequence of key data
d_values_in – [in] Pointer to the corresponding input sequence of associated value items
d_values_out – [out] Pointer to the correspondingly-reordered output sequence of associated value items
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename ValueT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortPairsDescending( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- const KeyT *d_keys_in,
- KeyT *d_keys_out,
- const ValueT *d_values_in,
- ValueT *d_values_out,
- NumItemsT num_items,
- DecomposerT decomposer,
- cudaStream_t stream = 0
Sorts key-value pairs into descending order using \(\approx 2N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The contents of the input data are not altered by the sorting operation.
Pointers to contiguous memory must be used; iterators are not currently supported.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys_in, d_keys_in + num_items)[d_keys_out, d_keys_out + num_items)[d_values_in, d_values_in + num_items)[d_values_out, d_values_out + num_items)
This operation requires an allocation of temporary device storage that is
O(N+P), whereNis the length of the input andPis the number of streaming multiprocessors on the device. For sorting using only \(O(P)\) temporary storage, see the sorting interface using DoubleBuffer wrappers below.When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortPairsDescending:std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; constexpr int num_items = 6; c2h::device_vector<custom_t> keys_in = { {+1.1f, 2}, // {+2.5f, 1}, // {-0.0f, 4}, // {+0.0f, 3}, // {-2.5f, 5}, // {+3.7f, 0} // }; c2h::device_vector<custom_t> keys_out(num_items); const custom_t* d_keys_in = thrust::raw_pointer_cast(keys_in.data()); custom_t* d_keys_out = thrust::raw_pointer_cast(keys_out.data()); c2h::device_vector<int> vals_in = {2, 1, 4, 3, 5, 0}; c2h::device_vector<int> vals_out(num_items); const int* d_vals_in = thrust::raw_pointer_cast(vals_in.data()); int* d_vals_out = thrust::raw_pointer_cast(vals_out.data()); cub::DeviceRadixSort::SortPairsDescending( d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, d_vals_in, d_vals_out, num_items, decomposer_t{}); c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); cub::DeviceRadixSort::SortPairsDescending( d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, d_vals_in, d_vals_out, num_items, decomposer_t{}); c2h::device_vector<custom_t> expected_keys = { {+3.7f, 0}, // {+2.5f, 1}, // {+1.1f, 2}, // {-0.0f, 4}, // {+0.0f, 3}, // {-2.5f, 5} // }; c2h::device_vector<int> expected_vals = {0, 1, 2, 4, 3, 5};
- Template Parameters:
KeyT – [inferred] KeyT type
ValueT – [inferred] ValueT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys_in – [in] Pointer to the input data of key data to sort
d_keys_out – [out] Pointer to the sorted output sequence of key data
d_values_in – [in] Pointer to the corresponding input sequence of associated value items
d_values_out – [out] Pointer to the correspondingly-reordered output sequence of associated value items
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename ValueT, typename NumItemsT>
static inline cudaError_t SortPairsDescending( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- DoubleBuffer<KeyT> &d_keys,
- DoubleBuffer<ValueT> &d_values,
- NumItemsT num_items,
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8,
- cudaStream_t stream = 0
Sorts key-value pairs into descending order using \(\approx N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The sorting operation is given a pair of key buffers and a corresponding pair of associated value buffers. Each pair is managed by a DoubleBuffer structure that indicates which of the two buffers is “current” (and thus contains the input data to be sorted).
The contents of both buffers within each pair may be altered by the sorting operation.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys.Current(), d_keys.Current() + num_items)[d_keys.Alternate(), d_keys.Alternate() + num_items)[d_values.Current(), d_values.Current() + num_items)[d_values.Alternate(), d_values.Alternate() + num_items)
Upon completion, the sorting operation will update the “current” indicator within each DoubleBuffer wrapper to reference which of the two buffers now contains the sorted output sequence (a function of the number of key bits specified and the targeted device architecture).
An optional bit subrange
[begin_bit, end_bit)of differentiating key bits can be specified. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires a relatively small allocation of temporary device storage that is
O(P), wherePis the number of streaming multiprocessors on the device (and is typically a small constant relative to the input sizeN).When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
The code snippet below illustrates the sorting of a device vector of
intkeys with associated vector ofintvalues.#include <cub/cub.cuh> // or equivalently <cub/device/device_radix_sort.cuh> // Declare, allocate, and initialize device-accessible pointers // for sorting data int num_items; // e.g., 7 int *d_key_buf; // e.g., [8, 6, 7, 5, 3, 0, 9] int *d_key_alt_buf; // e.g., [ ... ] int *d_value_buf; // e.g., [0, 1, 2, 3, 4, 5, 6] int *d_value_alt_buf; // e.g., [ ... ] ... // Create a set of DoubleBuffers to wrap pairs of device pointers cub::DoubleBuffer<int> d_keys(d_key_buf, d_key_alt_buf); cub::DoubleBuffer<int> d_values(d_value_buf, d_value_alt_buf); // Determine temporary device storage requirements void *d_temp_storage = nullptr; size_t temp_storage_bytes = 0; cub::DeviceRadixSort::SortPairsDescending( d_temp_storage, temp_storage_bytes, d_keys, d_values, num_items); // Allocate temporary storage cudaMalloc(&d_temp_storage, temp_storage_bytes); // Run sorting operation cub::DeviceRadixSort::SortPairsDescending( d_temp_storage, temp_storage_bytes, d_keys, d_values, num_items); // d_keys.Current() <-- [9, 8, 7, 6, 5, 3, 0] // d_values.Current() <-- [6, 0, 2, 1, 3, 4, 5]
- Template Parameters:
KeyT – [inferred] KeyT type
ValueT – [inferred] ValueT type
NumItemsT – [inferred] Type of num_items
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys – [inout] Reference to the double-buffer of keys whose “current” device-accessible buffer contains the unsorted input keys and, upon return, is updated to point to the sorted output keys
d_values – [inout] Double-buffer of values whose “current” device-accessible buffer contains the unsorted input values and, upon return, is updated to point to the sorted output values
num_items – [in] Number of items to sort
begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
sizeof(unsigned int) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename ValueT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortPairsDescending( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- DoubleBuffer<KeyT> &d_keys,
- DoubleBuffer<ValueT> &d_values,
- NumItemsT num_items,
- DecomposerT decomposer,
- cudaStream_t stream = 0
Sorts key-value pairs into descending order using \(\approx N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The sorting operation is given a pair of key buffers and a corresponding pair of associated value buffers. Each pair is managed by a DoubleBuffer structure that indicates which of the two buffers is “current” (and thus contains the input data to be sorted).
The contents of both buffers within each pair may be altered by the sorting operation.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys.Current(), d_keys.Current() + num_items)[d_keys.Alternate(), d_keys.Alternate() + num_items)[d_values.Current(), d_values.Current() + num_items)[d_values.Alternate(), d_values.Alternate() + num_items)
Upon completion, the sorting operation will update the “current” indicator within each DoubleBuffer wrapper to reference which of the two buffers now contains the sorted output sequence (a function of the number of key bits specified and the targeted device architecture).
This operation requires a relatively small allocation of temporary device storage that is
O(P), wherePis the number of streaming multiprocessors on the device (and is typically a small constant relative to the input sizeN).When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortPairsDescending:std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; constexpr int num_items = 6; c2h::device_vector<custom_t> keys_buf = { {+1.1f, 2}, // {+2.5f, 1}, // {-0.0f, 4}, // {+0.0f, 3}, // {-2.5f, 5}, // {+3.7f, 0} // }; c2h::device_vector<custom_t> keys_alt_buf(num_items); custom_t* d_keys_buf = thrust::raw_pointer_cast(keys_buf.data()); custom_t* d_keys_alt_buf = thrust::raw_pointer_cast(keys_alt_buf.data()); c2h::device_vector<int> vals_buf = {2, 1, 4, 3, 5, 0}; c2h::device_vector<int> vals_alt_buf(num_items); int* d_vals_buf = thrust::raw_pointer_cast(vals_buf.data()); int* d_vals_alt_buf = thrust::raw_pointer_cast(vals_alt_buf.data()); cub::DoubleBuffer<custom_t> d_keys(d_keys_buf, d_keys_alt_buf); cub::DoubleBuffer<int> d_vals(d_vals_buf, d_vals_alt_buf); cub::DeviceRadixSort::SortPairsDescending( d_temp_storage, temp_storage_bytes, d_keys, d_vals, num_items, decomposer_t{}); c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); cub::DeviceRadixSort::SortPairsDescending( d_temp_storage, temp_storage_bytes, d_keys, d_vals, num_items, decomposer_t{}); c2h::device_vector<custom_t>& current_keys = // d_keys.Current() == d_keys_buf ? keys_buf : keys_alt_buf; c2h::device_vector<int>& current_vals = // d_vals.Current() == d_vals_buf ? vals_buf : vals_alt_buf; c2h::device_vector<custom_t> expected_keys = { {+3.7f, 0}, // {+2.5f, 1}, // {+1.1f, 2}, // {-0.0f, 4}, // {+0.0f, 3}, // {-2.5f, 5} // }; c2h::device_vector<int> expected_vals = {0, 1, 2, 4, 3, 5};
- Template Parameters:
KeyT – [inferred] KeyT type
ValueT – [inferred] ValueT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys – [inout] Reference to the double-buffer of keys whose “current” device-accessible buffer contains the unsorted input keys and, upon return, is updated to point to the sorted output keys
d_values – [inout] Double-buffer of values whose “current” device-accessible buffer contains the unsorted input values and, upon return, is updated to point to the sorted output values
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename ValueT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortPairsDescending( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- DoubleBuffer<KeyT> &d_keys,
- DoubleBuffer<ValueT> &d_values,
- NumItemsT num_items,
- DecomposerT decomposer,
- int begin_bit,
- int end_bit,
- cudaStream_t stream = 0
Sorts key-value pairs into descending order using \(\approx N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The sorting operation is given a pair of key buffers and a corresponding pair of associated value buffers. Each pair is managed by a DoubleBuffer structure that indicates which of the two buffers is “current” (and thus contains the input data to be sorted).
The contents of both buffers within each pair may be altered by the sorting operation.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys.Current(), d_keys.Current() + num_items)[d_keys.Alternate(), d_keys.Alternate() + num_items)[d_values.Current(), d_values.Current() + num_items)[d_values.Alternate(), d_values.Alternate() + num_items)
Upon completion, the sorting operation will update the “current” indicator within each DoubleBuffer wrapper to reference which of the two buffers now contains the sorted output sequence (a function of the number of key bits specified and the targeted device architecture).
An optional bit subrange
[begin_bit, end_bit)of differentiating key bits can be specified. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires a relatively small allocation of temporary device storage that is
O(P), wherePis the number of streaming multiprocessors on the device (and is typically a small constant relative to the input sizeN).When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortPairsDescending:constexpr int num_items = 2; c2h::device_vector<custom_t> keys_buf = { {42.4f, 1ll << 60}, // {24.2f, 1ll << 61} // }; c2h::device_vector<int> vals_buf = {1, 0}; constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000010001010011001100110011010 00010000000000...0000 // decompose(in[1]) = 01000001110000011001100110011010 00100000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> c2h::device_vector<custom_t> keys_alt_buf(num_items); c2h::device_vector<int> vals_alt_buf(num_items); custom_t* d_keys_buf = thrust::raw_pointer_cast(keys_buf.data()); custom_t* d_keys_alt_buf = thrust::raw_pointer_cast(keys_alt_buf.data()); int* d_vals_buf = thrust::raw_pointer_cast(vals_buf.data()); int* d_vals_alt_buf = thrust::raw_pointer_cast(vals_alt_buf.data()); cub::DoubleBuffer<custom_t> d_keys(d_keys_buf, d_keys_alt_buf); cub::DoubleBuffer<int> d_vals(d_vals_buf, d_vals_alt_buf); // 1) Get temp storage size std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; cub::DeviceRadixSort::SortPairsDescending( d_temp_storage, temp_storage_bytes, d_keys, d_vals, num_items, decomposer_t{}, begin_bit, end_bit); // 2) Allocate temp storage c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); // 3) Sort keys cub::DeviceRadixSort::SortPairsDescending( d_temp_storage, temp_storage_bytes, d_keys, d_vals, num_items, decomposer_t{}, begin_bit, end_bit); c2h::device_vector<custom_t>& current_keys = // d_keys.Current() == d_keys_buf ? keys_buf : keys_alt_buf; c2h::device_vector<int>& current_vals = // d_vals.Current() == d_vals_buf ? vals_buf : vals_alt_buf; c2h::device_vector<custom_t> expected_keys = { {24.2f, 1ll << 61}, // {42.4f, 1ll << 60} // }; c2h::device_vector<int> expected_vals = {0, 1};
- Template Parameters:
KeyT – [inferred] KeyT type
ValueT – [inferred] ValueT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys – [inout] Reference to the double-buffer of keys whose “current” device-accessible buffer contains the unsorted input keys and, upon return, is updated to point to the sorted output keys
d_values – [inout] Double-buffer of values whose “current” device-accessible buffer contains the unsorted input values and, upon return, is updated to point to the sorted output values
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
Keys-only
-
template<typename KeyT, typename NumItemsT>
static inline cudaError_t SortKeys( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- const KeyT *d_keys_in,
- KeyT *d_keys_out,
- NumItemsT num_items,
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8,
- cudaStream_t stream = 0
Sorts keys into ascending order using \(\approx 2N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The contents of the input data are not altered by the sorting operation.
Pointers to contiguous memory must be used; iterators are not currently supported.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys_in, d_keys_in + num_items)[d_keys_out, d_keys_out + num_items)
An optional bit subrange
[begin_bit, end_bit)of differentiating key bits can be specified. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires an allocation of temporary device storage that is
O(N+P), whereNis the length of the input andPis the number of streaming multiprocessors on the device. For sorting using onlyO(P)temporary storage, see the sorting interface using DoubleBuffer wrappers below.When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
The code snippet below illustrates the sorting of a device vector of
intkeys.#include <cub/cub.cuh> // or equivalently <cub/device/device_radix_sort.cuh> // Declare, allocate, and initialize device-accessible pointers // for sorting data int num_items; // e.g., 7 int *d_keys_in; // e.g., [8, 6, 7, 5, 3, 0, 9] int *d_keys_out; // e.g., [ ... ] ... // Determine temporary device storage requirements void *d_temp_storage = nullptr; size_t temp_storage_bytes = 0; cub::DeviceRadixSort::SortKeys( d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, num_items); // Allocate temporary storage cudaMalloc(&d_temp_storage, temp_storage_bytes); // Run sorting operation cub::DeviceRadixSort::SortKeys( d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, num_items); // d_keys_out <-- [0, 3, 5, 6, 7, 8, 9]
- Template Parameters:
KeyT – [inferred] KeyT type
NumItemsT – [inferred] Type of num_items
NumItemsT – [inferred] Type of num_items
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys_in – [in] Pointer to the input data of key data to sort
d_keys_out – [out] Pointer to the sorted output sequence of key data
num_items – [in] Number of items to sort
begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
sizeof(unsigned int) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortKeys( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- const KeyT *d_keys_in,
- KeyT *d_keys_out,
- NumItemsT num_items,
- DecomposerT decomposer,
- int begin_bit,
- int end_bit,
- cudaStream_t stream = 0
Sorts keys into ascending order using \(\approx 2N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The contents of the input data are not altered by the sorting operation.
Pointers to contiguous memory must be used; iterators are not currently supported.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys_in, d_keys_in + num_items)[d_keys_out, d_keys_out + num_items)
A bit subrange
[begin_bit, end_bit)is provided to specify differentiating key bits. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires an allocation of temporary device storage that is
O(N+P), whereNis the length of the input andPis the number of streaming multiprocessors on the device. For sorting using only \(O(P)\) temporary storage, see the sorting interface using DoubleBuffer wrappers below.When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortKeys:constexpr int num_items = 2; c2h::device_vector<custom_t> in = { {24.2f, 1ll << 61}, // {42.4f, 1ll << 60} // }; constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000001110000011001100110011010 00100000000000...0000 // decompose(in[1]) = 01000010001010011001100110011010 00010000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> c2h::device_vector<custom_t> out(num_items); const custom_t* d_in = thrust::raw_pointer_cast(in.data()); custom_t* d_out = thrust::raw_pointer_cast(out.data()); // 1) Get temp storage size std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; cub::DeviceRadixSort::SortKeys( d_temp_storage, temp_storage_bytes, d_in, d_out, num_items, decomposer_t{}, begin_bit, end_bit); // 2) Allocate temp storage c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); // 3) Sort keys cub::DeviceRadixSort::SortKeys( d_temp_storage, temp_storage_bytes, d_in, d_out, num_items, decomposer_t{}, begin_bit, end_bit); c2h::device_vector<custom_t> expected_output = { {42.4f, 1ll << 60}, // {24.2f, 1ll << 61} // };
- Template Parameters:
KeyT – [inferred] KeyT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys_in – [in] Pointer to the input data of key data to sort
d_keys_out – [out] Pointer to the sorted output sequence of key data
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortKeys( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- const KeyT *d_keys_in,
- KeyT *d_keys_out,
- NumItemsT num_items,
- DecomposerT decomposer,
- cudaStream_t stream = 0
Sorts keys into ascending order using \(\approx 2N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The contents of the input data are not altered by the sorting operation.
Pointers to contiguous memory must be used; iterators are not currently supported.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys_in, d_keys_in + num_items)[d_keys_out, d_keys_out + num_items)
An optional bit subrange
[begin_bit, end_bit)of differentiating key bits can be specified. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires an allocation of temporary device storage that is
O(N+P), whereNis the length of the input andPis the number of streaming multiprocessors on the device. For sorting using only \(O(P)\) temporary storage, see the sorting interface using DoubleBuffer wrappers below.When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortKeys:constexpr int num_items = 6; c2h::device_vector<custom_t> in = { {+2.5f, 4}, // {-2.5f, 0}, // {+1.1f, 3}, // {+0.0f, 1}, // {-0.0f, 2}, // {+3.7f, 5} // }; c2h::device_vector<custom_t> out(num_items); const custom_t* d_in = thrust::raw_pointer_cast(in.data()); custom_t* d_out = thrust::raw_pointer_cast(out.data()); // 1) Get temp storage size std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; cub::DeviceRadixSort::SortKeys(d_temp_storage, temp_storage_bytes, d_in, d_out, num_items, decomposer_t{}); // 2) Allocate temp storage c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); // 3) Sort keys cub::DeviceRadixSort::SortKeys(d_temp_storage, temp_storage_bytes, d_in, d_out, num_items, decomposer_t{}); c2h::device_vector<custom_t> expected_output = { {-2.5f, 0}, // {+0.0f, 1}, // {-0.0f, 2}, // {+1.1f, 3}, // {+2.5f, 4}, // {+3.7f, 5} // };
- Template Parameters:
KeyT – [inferred] KeyT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys_in – [in] Pointer to the input data of key data to sort
d_keys_out – [out] Pointer to the sorted output sequence of key data
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename NumItemsT>
static inline cudaError_t SortKeys( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- DoubleBuffer<KeyT> &d_keys,
- NumItemsT num_items,
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8,
- cudaStream_t stream = 0
Sorts keys into ascending order using \(\approx N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The sorting operation is given a pair of key buffers managed by a DoubleBuffer structure that indicates which of the two buffers is “current” (and thus contains the input data to be sorted).
The contents of both buffers may be altered by the sorting operation.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys.Current(), d_keys.Current() + num_items)[d_keys.Alternate(), d_keys.Alternate() + num_items)
Upon completion, the sorting operation will update the “current” indicator within the DoubleBuffer wrapper to reference which of the two buffers now contains the sorted output sequence (a function of the number of key bits specified and the targeted device architecture).
An optional bit subrange
[begin_bit, end_bit)of differentiating key bits can be specified. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires a relatively small allocation of temporary device storage that is
O(P), wherePis the number of streaming multiprocessors on the device (and is typically a small constant relative to the input sizeN).When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
The code snippet below illustrates the sorting of a device vector of
intkeys.#include <cub/cub.cuh> // or equivalently <cub/device/device_radix_sort.cuh> // Declare, allocate, and initialize device-accessible pointers // for sorting data int num_items; // e.g., 7 int *d_key_buf; // e.g., [8, 6, 7, 5, 3, 0, 9] int *d_key_alt_buf; // e.g., [ ... ] ... // Create a DoubleBuffer to wrap the pair of device pointers cub::DoubleBuffer<int> d_keys(d_key_buf, d_key_alt_buf); // Determine temporary device storage requirements void *d_temp_storage = nullptr; size_t temp_storage_bytes = 0; cub::DeviceRadixSort::SortKeys( d_temp_storage, temp_storage_bytes, d_keys, num_items); // Allocate temporary storage cudaMalloc(&d_temp_storage, temp_storage_bytes); // Run sorting operation cub::DeviceRadixSort::SortKeys( d_temp_storage, temp_storage_bytes, d_keys, num_items); // d_keys.Current() <-- [0, 3, 5, 6, 7, 8, 9]
- Template Parameters:
KeyT – [inferred] KeyT type
NumItemsT – [inferred] Type of num_items
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys – [inout] Reference to the double-buffer of keys whose “current” device-accessible buffer contains the unsorted input keys and, upon return, is updated to point to the sorted output keys
num_items – [in] Number of items to sort
begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
sizeof(unsigned int) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortKeys( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- DoubleBuffer<KeyT> &d_keys,
- NumItemsT num_items,
- DecomposerT decomposer,
- cudaStream_t stream = 0
Sorts keys into ascending order using \(\approx N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The sorting operation is given a pair of key buffers managed by a DoubleBuffer structure that indicates which of the two buffers is “current” (and thus contains the input data to be sorted).
The contents of both buffers may be altered by the sorting operation.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys.Current(), d_keys.Current() + num_items)[d_keys.Alternate(), d_keys.Alternate() + num_items)
Upon completion, the sorting operation will update the “current” indicator within the DoubleBuffer wrapper to reference which of the two buffers now contains the sorted output sequence (a function of the number of key bits specified and the targeted device architecture).
This operation requires a relatively small allocation of temporary device storage that is
O(P), wherePis the number of streaming multiprocessors on the device (and is typically a small constant relative to the input sizeN).When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortKeys:std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; constexpr int num_items = 6; c2h::device_vector<custom_t> keys_buf = { {+2.5f, 4}, // {-2.5f, 0}, // {+1.1f, 3}, // {+0.0f, 1}, // {-0.0f, 2}, // {+3.7f, 5} // }; c2h::device_vector<custom_t> keys_alt_buf(num_items); custom_t* d_keys_buf = thrust::raw_pointer_cast(keys_buf.data()); custom_t* d_keys_alt_buf = thrust::raw_pointer_cast(keys_alt_buf.data()); cub::DoubleBuffer<custom_t> d_keys(d_keys_buf, d_keys_alt_buf); cub::DeviceRadixSort::SortKeys(d_temp_storage, temp_storage_bytes, d_keys, num_items, decomposer_t{}); c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); cub::DeviceRadixSort::SortKeys(d_temp_storage, temp_storage_bytes, d_keys, num_items, decomposer_t{}); c2h::device_vector<custom_t>& current = // d_keys.Current() == d_keys_buf ? keys_buf : keys_alt_buf; c2h::device_vector<custom_t> expected_output = { {-2.5f, 0}, // {+0.0f, 1}, // {-0.0f, 2}, // {+1.1f, 3}, // {+2.5f, 4}, // {+3.7f, 5} // };
- Template Parameters:
KeyT – [inferred] KeyT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys – [inout] Reference to the double-buffer of keys whose “current” device-accessible buffer contains the unsorted input keys and, upon return, is updated to point to the sorted output keys
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortKeys( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- DoubleBuffer<KeyT> &d_keys,
- NumItemsT num_items,
- DecomposerT decomposer,
- int begin_bit,
- int end_bit,
- cudaStream_t stream = 0
Sorts keys into ascending order using \(\approx N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The sorting operation is given a pair of key buffers managed by a DoubleBuffer structure that indicates which of the two buffers is “current” (and thus contains the input data to be sorted).
The contents of both buffers may be altered by the sorting operation.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys.Current(), d_keys.Current() + num_items)[d_keys.Alternate(), d_keys.Alternate() + num_items)
A bit subrange
[begin_bit, end_bit)is provided to specify differentiating key bits. This can reduce overall sorting overhead and yield a corresponding performance improvement.Upon completion, the sorting operation will update the “current” indicator within the DoubleBuffer wrapper to reference which of the two buffers now contains the sorted output sequence (a function of the number of key bits specified and the targeted device architecture).
This operation requires a relatively small allocation of temporary device storage that is
O(P), wherePis the number of streaming multiprocessors on the device (and is typically a small constant relative to the input sizeN).When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortKeys:constexpr int num_items = 2; c2h::device_vector<custom_t> keys_buf = { {24.2f, 1ll << 61}, // {42.4f, 1ll << 60} // }; constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000001110000011001100110011010 00100000000000...0000 // decompose(in[1]) = 01000010001010011001100110011010 00010000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> c2h::device_vector<custom_t> keys_alt_buf(num_items); custom_t* d_keys_buf = thrust::raw_pointer_cast(keys_buf.data()); custom_t* d_keys_alt_buf = thrust::raw_pointer_cast(keys_alt_buf.data()); cub::DoubleBuffer<custom_t> d_keys(d_keys_buf, d_keys_alt_buf); // 1) Get temp storage size std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; cub::DeviceRadixSort::SortKeys( d_temp_storage, temp_storage_bytes, d_keys, num_items, decomposer_t{}, begin_bit, end_bit); // 2) Allocate temp storage c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); // 3) Sort keys cub::DeviceRadixSort::SortKeys( d_temp_storage, temp_storage_bytes, d_keys, num_items, decomposer_t{}, begin_bit, end_bit); c2h::device_vector<custom_t>& current_keys = // d_keys.Current() == d_keys_buf ? keys_buf : keys_alt_buf; c2h::device_vector<custom_t> expected_output = { {42.4f, 1ll << 60}, // {24.2f, 1ll << 61} // };
- Template Parameters:
KeyT – [inferred] KeyT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys – [inout] Reference to the double-buffer of keys whose “current” device-accessible buffer contains the unsorted input keys and, upon return, is updated to point to the sorted output keys
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename NumItemsT>
static inline cudaError_t SortKeysDescending( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- const KeyT *d_keys_in,
- KeyT *d_keys_out,
- NumItemsT num_items,
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8,
- cudaStream_t stream = 0
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The contents of the input data are not altered by the sorting operation.
Pointers to contiguous memory must be used; iterators are not currently supported.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys_in, d_keys_in + num_items)[d_keys_out, d_keys_out + num_items)
An optional bit subrange
[begin_bit, end_bit)of differentiating key bits can be specified. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires an allocation of temporary device storage that is
O(N+P), whereNis the length of the input andPis the number of streaming multiprocessors on the device. For sorting using onlyO(P)temporary storage, see the sorting interface using DoubleBuffer wrappers below.When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
The code snippet below illustrates the sorting of a device vector of
intkeys.#include <cub/cub.cuh> // or equivalently <cub/device/device_radix_sort.cuh> // Declare, allocate, and initialize device-accessible pointers // for sorting data int num_items; // e.g., 7 int *d_keys_in; // e.g., [8, 6, 7, 5, 3, 0, 9] int *d_keys_out; // e.g., [ ... ] ... // Create a DoubleBuffer to wrap the pair of device pointers cub::DoubleBuffer<int> d_keys(d_key_buf, d_key_alt_buf); // Determine temporary device storage requirements void *d_temp_storage = nullptr; size_t temp_storage_bytes = 0; cub::DeviceRadixSort::SortKeysDescending( d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, num_items); // Allocate temporary storage cudaMalloc(&d_temp_storage, temp_storage_bytes); // Run sorting operation cub::DeviceRadixSort::SortKeysDescending( d_temp_storage, temp_storage_bytes, d_keys_in, d_keys_out, num_items); // d_keys_out <-- [9, 8, 7, 6, 5, 3, 0]s
- Template Parameters:
KeyT – [inferred] KeyT type
NumItemsT – [inferred] Type of num_items
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys_in – [in] Pointer to the input data of key data to sort
d_keys_out – [out] Pointer to the sorted output sequence of key data
num_items – [in] Number of items to sort
begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
sizeof(unsigned int) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortKeysDescending( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- const KeyT *d_keys_in,
- KeyT *d_keys_out,
- NumItemsT num_items,
- DecomposerT decomposer,
- int begin_bit,
- int end_bit,
- cudaStream_t stream = 0
Sorts keys into descending order using \(\approx 2N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The contents of the input data are not altered by the sorting operation.
Pointers to contiguous memory must be used; iterators are not currently supported.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys_in, d_keys_in + num_items)[d_keys_out, d_keys_out + num_items)
An optional bit subrange
[begin_bit, end_bit)of differentiating key bits can be specified. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires an allocation of temporary device storage that is
O(N+P), whereNis the length of the input andPis the number of streaming multiprocessors on the device. For sorting using only \(O(P)\) temporary storage, see the sorting interface using DoubleBuffer wrappers below.When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortKeysDescending:constexpr int num_items = 2; c2h::device_vector<custom_t> in = {{42.4f, 1ll << 60}, {24.2f, 1ll << 61}}; constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000010001010011001100110011010 00010000000000...0000 // decompose(in[1]) = 01000001110000011001100110011010 00100000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> c2h::device_vector<custom_t> out(num_items); const custom_t* d_in = thrust::raw_pointer_cast(in.data()); custom_t* d_out = thrust::raw_pointer_cast(out.data()); // 1) Get temp storage size std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; cub::DeviceRadixSort::SortKeysDescending( d_temp_storage, temp_storage_bytes, d_in, d_out, num_items, decomposer_t{}, begin_bit, end_bit); // 2) Allocate temp storage c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); // 3) Sort keys cub::DeviceRadixSort::SortKeysDescending( d_temp_storage, temp_storage_bytes, d_in, d_out, num_items, decomposer_t{}, begin_bit, end_bit); c2h::device_vector<custom_t> expected_output = { {24.2f, 1ll << 61}, // {42.4f, 1ll << 60} // };
- Template Parameters:
KeyT – [inferred] KeyT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys_in – [in] Pointer to the input data of key data to sort
d_keys_out – [out] Pointer to the sorted output sequence of key data
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortKeysDescending( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- const KeyT *d_keys_in,
- KeyT *d_keys_out,
- NumItemsT num_items,
- DecomposerT decomposer,
- cudaStream_t stream = 0
Sorts keys into descending order using \(\approx 2N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The contents of the input data are not altered by the sorting operation.
Pointers to contiguous memory must be used; iterators are not currently supported.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys_in, d_keys_in + num_items)[d_keys_out, d_keys_out + num_items)
This operation requires an allocation of temporary device storage that is
O(N+P), whereNis the length of the input andPis the number of streaming multiprocessors on the device. For sorting using only \(O(P)\) temporary storage, see the sorting interface using DoubleBuffer wrappers below.When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortKeysDescending:std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; constexpr int num_items = 6; c2h::device_vector<custom_t> in = { {+1.1f, 2}, // {+2.5f, 1}, // {-0.0f, 4}, // {+0.0f, 3}, // {-2.5f, 5}, // {+3.7f, 0} // }; c2h::device_vector<custom_t> out(num_items); const custom_t* d_in = thrust::raw_pointer_cast(in.data()); custom_t* d_out = thrust::raw_pointer_cast(out.data()); cub::DeviceRadixSort::SortKeysDescending(d_temp_storage, temp_storage_bytes, d_in, d_out, num_items, decomposer_t{}); c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); cub::DeviceRadixSort::SortKeysDescending(d_temp_storage, temp_storage_bytes, d_in, d_out, num_items, decomposer_t{}); c2h::device_vector<custom_t> expected_output = { {+3.7f, 0}, // {+2.5f, 1}, // {+1.1f, 2}, // {-0.0f, 4}, // {+0.0f, 3}, // {-2.5f, 5} // };
- Template Parameters:
KeyT – [inferred] KeyT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys_in – [in] Pointer to the input data of key data to sort
d_keys_out – [out] Pointer to the sorted output sequence of key data
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename NumItemsT>
static inline cudaError_t SortKeysDescending( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- DoubleBuffer<KeyT> &d_keys,
- NumItemsT num_items,
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8,
- cudaStream_t stream = 0
Sorts keys into descending order using \(\approx N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The sorting operation is given a pair of key buffers managed by a DoubleBuffer structure that indicates which of the two buffers is “current” (and thus contains the input data to be sorted).
The contents of both buffers may be altered by the sorting operation.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys.Current(), d_keys.Current() + num_items)[d_keys.Alternate(), d_keys.Alternate() + num_items)
Upon completion, the sorting operation will update the “current” indicator within the DoubleBuffer wrapper to reference which of the two buffers now contains the sorted output sequence (a function of the number of key bits specified and the targeted device architecture).
An optional bit subrange
[begin_bit, end_bit)of differentiating key bits can be specified. This can reduce overall sorting overhead and yield a corresponding performance improvement.This operation requires a relatively small allocation of temporary device storage that is
O(P), wherePis the number of streaming multiprocessors on the device (and is typically a small constant relative to the input sizeN).When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
The code snippet below illustrates the sorting of a device vector of
intkeys.#include <cub/cub.cuh> // or equivalently <cub/device/device_radix_sort.cuh> // Declare, allocate, and initialize device-accessible pointers // for sorting data int num_items; // e.g., 7 int *d_key_buf; // e.g., [8, 6, 7, 5, 3, 0, 9] int *d_key_alt_buf; // e.g., [ ... ] ... // Create a DoubleBuffer to wrap the pair of device pointers cub::DoubleBuffer<int> d_keys(d_key_buf, d_key_alt_buf); // Determine temporary device storage requirements void *d_temp_storage = nullptr; size_t temp_storage_bytes = 0; cub::DeviceRadixSort::SortKeysDescending( d_temp_storage, temp_storage_bytes, d_keys, num_items); // Allocate temporary storage cudaMalloc(&d_temp_storage, temp_storage_bytes); // Run sorting operation cub::DeviceRadixSort::SortKeysDescending( d_temp_storage, temp_storage_bytes, d_keys, num_items); // d_keys.Current() <-- [9, 8, 7, 6, 5, 3, 0]
- Template Parameters:
KeyT – [inferred] KeyT type
NumItemsT – [inferred] Type of num_items
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys – [inout] Reference to the double-buffer of keys whose “current” device-accessible buffer contains the unsorted input keys and, upon return, is updated to point to the sorted output keys
num_items – [in] Number of items to sort
begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
sizeof(unsigned int) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortKeysDescending( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- DoubleBuffer<KeyT> &d_keys,
- NumItemsT num_items,
- DecomposerT decomposer,
- cudaStream_t stream = 0
Sorts keys into descending order using \(\approx N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The sorting operation is given a pair of key buffers managed by a DoubleBuffer structure that indicates which of the two buffers is “current” (and thus contains the input data to be sorted).
The contents of both buffers may be altered by the sorting operation.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys.Current(), d_keys.Current() + num_items)[d_keys.Alternate(), d_keys.Alternate() + num_items)
Upon completion, the sorting operation will update the “current” indicator within the DoubleBuffer wrapper to reference which of the two buffers now contains the sorted output sequence (a function of the number of key bits specified and the targeted device architecture).
This operation requires a relatively small allocation of temporary device storage that is
O(P), wherePis the number of streaming multiprocessors on the device (and is typically a small constant relative to the input sizeN).When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortKeysDescending:std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; constexpr int num_items = 6; c2h::device_vector<custom_t> keys_buf = { {+1.1f, 2}, // {+2.5f, 1}, // {-0.0f, 4}, // {+0.0f, 3}, // {-2.5f, 5}, // {+3.7f, 0} // }; c2h::device_vector<custom_t> keys_alt_buf(num_items); custom_t* d_keys_buf = thrust::raw_pointer_cast(keys_buf.data()); custom_t* d_keys_alt_buf = thrust::raw_pointer_cast(keys_alt_buf.data()); cub::DoubleBuffer<custom_t> d_keys(d_keys_buf, d_keys_alt_buf); cub::DeviceRadixSort::SortKeysDescending(d_temp_storage, temp_storage_bytes, d_keys, num_items, decomposer_t{}); c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); cub::DeviceRadixSort::SortKeysDescending(d_temp_storage, temp_storage_bytes, d_keys, num_items, decomposer_t{}); c2h::device_vector<custom_t>& current = // d_keys.Current() == d_keys_buf ? keys_buf : keys_alt_buf; c2h::device_vector<custom_t> expected_output = { {+3.7f, 0}, // {+2.5f, 1}, // {+1.1f, 2}, // {-0.0f, 4}, // {+0.0f, 3}, // {-2.5f, 5} // };
- Template Parameters:
KeyT – [inferred] KeyT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys – [inout] Reference to the double-buffer of keys whose “current” device-accessible buffer contains the unsorted input keys and, upon return, is updated to point to the sorted output keys
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.
-
template<typename KeyT, typename NumItemsT, typename DecomposerT>
static inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>, cudaError_t> SortKeysDescending( - void *d_temp_storage,
- size_t &temp_storage_bytes,
- DoubleBuffer<KeyT> &d_keys,
- NumItemsT num_items,
- DecomposerT decomposer,
- int begin_bit,
- int end_bit,
- cudaStream_t stream = 0
Sorts keys into descending order using \(\approx N\) auxiliary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
The sorting operation is given a pair of key buffers managed by a DoubleBuffer structure that indicates which of the two buffers is “current” (and thus contains the input data to be sorted).
The contents of both buffers may be altered by the sorting operation.
In-place operations are not supported. There must be no overlap between any of the provided ranges:
[d_keys.Current(), d_keys.Current() + num_items)[d_keys.Alternate(), d_keys.Alternate() + num_items)
A bit subrange
[begin_bit, end_bit)is provided to specify differentiating key bits. This can reduce overall sorting overhead and yield a corresponding performance improvement.Upon completion, the sorting operation will update the “current” indicator within the DoubleBuffer wrapper to reference which of the two buffers now contains the sorted output sequence (a function of the number of key bits specified and the targeted device architecture).
This operation requires a relatively small allocation of temporary device storage that is
O(P), wherePis the number of streaming multiprocessors on the device (and is typically a small constant relative to the input sizeN).When
d_temp_storageisnullptr, no work is done and the required allocation size is returned intemp_storage_bytes. See Determining Temporary Storage Requirements for usage guidance.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; struct decomposer_t { __host__ __device__ cuda::std::tuple<float&, long long int&> operator()(custom_t& key) const { return {key.f, key.lli}; } };
The following snippet shows how to sort an array of
custom_tobjects usingcub::DeviceRadixSort::SortKeysDescending:constexpr int num_items = 2; c2h::device_vector<custom_t> keys_buf = { // {42.4f, 1ll << 60}, // {24.2f, 1ll << 61} // }; constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000010001010011001100110011010 00010000000000...0000 // decompose(in[1]) = 01000001110000011001100110011010 00100000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> c2h::device_vector<custom_t> keys_alt_buf(num_items); custom_t* d_keys_buf = thrust::raw_pointer_cast(keys_buf.data()); custom_t* d_keys_alt_buf = thrust::raw_pointer_cast(keys_alt_buf.data()); cub::DoubleBuffer<custom_t> d_keys(d_keys_buf, d_keys_alt_buf); // 1) Get temp storage size std::uint8_t* d_temp_storage{}; std::size_t temp_storage_bytes{}; cub::DeviceRadixSort::SortKeysDescending( d_temp_storage, temp_storage_bytes, d_keys, num_items, decomposer_t{}, begin_bit, end_bit); // 2) Allocate temp storage c2h::device_vector<std::uint8_t> temp_storage(temp_storage_bytes); d_temp_storage = thrust::raw_pointer_cast(temp_storage.data()); // 3) Sort keys cub::DeviceRadixSort::SortKeysDescending( d_temp_storage, temp_storage_bytes, d_keys, num_items, decomposer_t{}, begin_bit, end_bit); c2h::device_vector<custom_t>& current_keys = // d_keys.Current() == d_keys_buf ? keys_buf : keys_alt_buf; c2h::device_vector<custom_t> expected_output = { {24.2f, 1ll << 61}, // {42.4f, 1ll << 60} // };
- Template Parameters:
KeyT – [inferred] KeyT type
NumItemsT – [inferred] Type of num_items
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- Parameters:
d_temp_storage – [in] Device-accessible allocation of temporary storage. When
nullptr, the required allocation size is written totemp_storage_bytesand no work is done.temp_storage_bytes – [inout] Reference to size in bytes of
d_temp_storageallocationd_keys – [inout] Reference to the double-buffer of keys whose “current” device-accessible buffer contains the unsorted input keys and, upon return, is updated to point to the sorted output keys
num_items – [in] Number of items to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] [optional] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] [optional] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)stream – [in] [optional] CUDA stream to launch kernels within. Default is stream0.