Overview#
Python plays a key role within the science, engineering, data analytics, and deep learning application ecosystem. NVIDIA has long been committed to helping the Python ecosystem leverage the accelerated massively parallel performance of GPUs to deliver standardized libraries, tools, and applications. Today, we’re introducing another step towards simplification of the developer experience with improved Python code portability and compatibility.
Our goal is to help unify the Python CUDA ecosystem with a single standard set of low-level interfaces, providing full coverage and access to the CUDA host APIs from Python. We want to provide an ecosystem foundation to allow interoperability among different accelerated libraries. Most importantly, it should be easy for Python developers to use NVIDIA GPUs.
cuda.bindings workflow#
Because Python is an interpreted language, you need a way to compile the device code into PTX and then extract the function to be called at a later point in the application. You construct your device code in the form of a string and compile it with NVRTC, a runtime compilation library for CUDA C++. Using the NVIDIA Driver API, manually create a CUDA context and all required resources on the GPU, then launch the compiled CUDA C++ code and retrieve the results from the GPU. Now that you have an overview, jump into a commonly used example for parallel programming: SAXPY. For more end-to-end samples, see the Examples page.
The first thing to do is import the Driver
API and
NVRTC modules from the cuda.bindings
package. Next, we consider how to store host data and pass it to the device. Different
approaches can be used to accomplish this and are described in
Preparing kernel arguments.
In this example, we will use NumPy to store host data and pass it to the device, so let’s
import this dependency as well.
from cuda.bindings import driver, nvrtc
import numpy as np
Error checking is a fundamental best practice when working with low-level interfaces. The following code snippet lets us validate each API call and raise exceptions in case of error:
def _cudaGetErrorEnum(error):
if isinstance(error, driver.CUresult):
err, name = driver.cuGetErrorName(error)
return name if err == driver.CUresult.CUDA_SUCCESS else "<unknown>"
elif isinstance(error, nvrtc.nvrtcResult):
return nvrtc.nvrtcGetErrorString(error)[1]
else:
raise RuntimeError('Unknown error type: {}'.format(error))
def checkCudaErrors(result):
if result[0].value:
raise RuntimeError("CUDA error code={}({})".format(result[0].value, _cudaGetErrorEnum(result[0])))
if len(result) == 1:
return None
elif len(result) == 2:
return result[1]
else:
return result[1:]
It’s common practice to write CUDA kernels near the top of a translation unit, so write it next. The entire kernel is wrapped in triple quotes to form a string. The string is compiled later using NVRTC. This is the only part of CUDA Python that requires some understanding of CUDA C++. For more information, see An Even Easier Introduction to CUDA.
saxpy = """\
extern "C" __global__
void saxpy(float a, float *x, float *y, float *out, size_t n)
{
size_t tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < n) {
out[tid] = a * x[tid] + y[tid];
}
}
"""
Go ahead and compile the kernel into PTX. Remember that this is executed at runtime using NVRTC. There are three basic steps to NVRTC:
Create a program from the string.
Compile the program.
Extract PTX from the compiled program.
In the following code example, the Driver API is initialized so that the NVIDIA driver and GPU are accessible. Next, the GPU is queried for their compute capability. Finally, the program is compiled to target our local compute capability architecture with FMAD disabled:
# Initialize CUDA Driver API
checkCudaErrors(driver.cuInit(0))
# Retrieve handle for device 0
cuDevice = checkCudaErrors(driver.cuDeviceGet(0))
# Derive target architecture for device 0
major = checkCudaErrors(driver.cuDeviceGetAttribute(driver.CUdevice_attribute.CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MAJOR, cuDevice))
minor = checkCudaErrors(driver.cuDeviceGetAttribute(driver.CUdevice_attribute.CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MINOR, cuDevice))
arch_arg = bytes(f'--gpu-architecture=compute_{major}{minor}', 'ascii')
# Create program
prog = checkCudaErrors(nvrtc.nvrtcCreateProgram(str.encode(saxpy), b"saxpy.cu", 0, [], []))
# Compile program
opts = [b"--fmad=false", arch_arg]
checkCudaErrors(nvrtc.nvrtcCompileProgram(prog, 2, opts))
# Get PTX from compilation
ptxSize = checkCudaErrors(nvrtc.nvrtcGetPTXSize(prog))
ptx = b" " * ptxSize
checkCudaErrors(nvrtc.nvrtcGetPTX(prog, ptx))
Before you can use the PTX or do any work on the GPU, you must create a CUDA
context. CUDA contexts are analogous to host processes for the device. In the
following code example, a handle for compute device 0 is passed to
cuCtxCreate to designate that GPU for context creation:
# Create context
context = checkCudaErrors(driver.cuCtxCreate(0, cuDevice))
With a CUDA context created on device 0, load the PTX generated earlier into a
module. A module is analogous to dynamically loaded libraries for the device.
After loading into the module, extract a specific kernel with
cuModuleGetFunction. It is not uncommon for multiple kernels to reside in PTX:
# Load PTX as module data and retrieve function
ptx = np.char.array(ptx)
# Note: Incompatible --gpu-architecture would be detected here
module = checkCudaErrors(driver.cuModuleLoadData(ptx.ctypes.data))
kernel = checkCudaErrors(driver.cuModuleGetFunction(module, b"saxpy"))
Next, get all your data prepared and transferred to the GPU. For increased application performance, you can input data on the device to eliminate data transfers. For completeness, this example shows how you would transfer data to and from the device:
NUM_THREADS = 512 # Threads per block
NUM_BLOCKS = 32768 # Blocks per grid
a = np.array([2.0], dtype=np.float32)
n = np.array(NUM_THREADS * NUM_BLOCKS, dtype=np.uint32)
bufferSize = n * a.itemsize
hX = np.random.rand(n).astype(dtype=np.float32)
hY = np.random.rand(n).astype(dtype=np.float32)
hOut = np.zeros(n).astype(dtype=np.float32)
With the input data a, x, and y created for the SAXPY transform device,
resources must be allocated to store the data using cuMemAlloc. To allow for
more overlap between compute and data movement, use the asynchronous function
cuMemcpyHtoDAsync. It returns control to the CPU immediately following command
execution.
Python doesn’t have a natural concept of pointers, yet cuMemcpyHtoDAsync expects
void*. This is where we leverage NumPy’s data types to retrieve each host data pointer
by calling XX.ctypes.data for the associated XX:
dXclass = checkCudaErrors(driver.cuMemAlloc(bufferSize))
dYclass = checkCudaErrors(driver.cuMemAlloc(bufferSize))
dOutclass = checkCudaErrors(driver.cuMemAlloc(bufferSize))
stream = checkCudaErrors(driver.cuStreamCreate(0))
checkCudaErrors(driver.cuMemcpyHtoDAsync(
dXclass, hX.ctypes.data, bufferSize, stream
))
checkCudaErrors(driver.cuMemcpyHtoDAsync(
dYclass, hY.ctypes.data, bufferSize, stream
))
With data prep and resources allocation finished, the kernel is ready to be
launched. To pass the location of the data on the device to the kernel execution
configuration, you must retrieve the device pointer. In the following code
example, we call int(XXclass) to retrieve the device pointer value for the
associated XXclass as a Python int and wrap it in a np.array type:
dX = np.array([int(dXclass)], dtype=np.uint64)
dY = np.array([int(dYclass)], dtype=np.uint64)
dOut = np.array([int(dOutclass)], dtype=np.uint64)
The launch API cuLaunchKernel also expects a pointer input for the argument list
but this time it’s of type void**. What this means is that our argument list needs to
be a contiguous array of void* elements, where each element is the pointer to a kernel
argument on either host or device. Since we already prepared each of our arguments into a np.array type, the
construction of our final contiguous array is done by retrieving the XX.ctypes.data
of each kernel argument:
args = [a, dX, dY, dOut, n]
args = np.array([arg.ctypes.data for arg in args], dtype=np.uint64)
Now the kernel can be launched:
checkCudaErrors(driver.cuLaunchKernel(
kernel,
NUM_BLOCKS, # grid x dim
1, # grid y dim
1, # grid z dim
NUM_THREADS, # block x dim
1, # block y dim
1, # block z dim
0, # dynamic shared memory
stream, # stream
args.ctypes.data, # kernel arguments
0, # extra (ignore)
))
checkCudaErrors(driver.cuMemcpyDtoHAsync(
hOut.ctypes.data, dOutclass, bufferSize, stream
))
checkCudaErrors(driver.cuStreamSynchronize(stream))
The cuLaunchKernel function takes the compiled module kernel and execution
configuration parameters. The device code is launched in the same stream as the
data transfers. That ensures that the kernel’s compute is performed only after
the data has finished transfer, as all API calls and kernel launches within a
stream are serialized. After the call to transfer data back to the host is
executed, cuStreamSynchronize is used to halt CPU execution until all operations
in the designated stream are finished:
# Assert values are same after running kernel
hZ = a * hX + hY
if not np.allclose(hOut, hZ):
raise ValueError("Error outside tolerance for host-device vectors")
Perform verification of the data to ensure correctness and finish the code with memory clean up:
checkCudaErrors(driver.cuStreamDestroy(stream))
checkCudaErrors(driver.cuMemFree(dXclass))
checkCudaErrors(driver.cuMemFree(dYclass))
checkCudaErrors(driver.cuMemFree(dOutclass))
checkCudaErrors(driver.cuModuleUnload(module))
checkCudaErrors(driver.cuCtxDestroy(context))
Performance#
Performance is a primary driver in targeting GPUs in your application. So, how does the above code compare to its C++ version? Table 1 shows that the results are nearly identical. NVIDIA NSight Systems was used to retrieve kernel performance and CUDA Events was used for application performance.
The following command was used to profile the applications:
nsys profile -s none -t cuda --stats=true <executable>
C++ |
Python |
|
|---|---|---|
Kernel execution |
352µs |
352µs |
Application execution |
1076ms |
1080ms |
cuda.bindings is also compatible with NVIDIA Nsight
Compute, which is an
interactive kernel profiler for CUDA applications. It allows you to have
detailed insights into kernel performance. This is useful when you’re trying to
maximize performance ({numref}``Figure 1``).
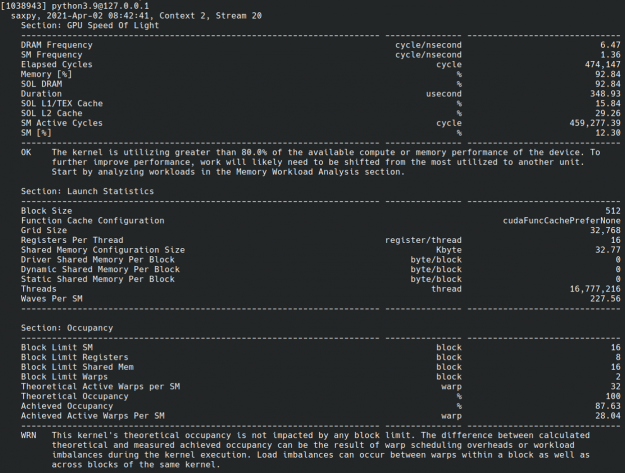
Fig. 1 Screenshot of Nsight Compute CLI output of cuda.bindings example.#
Preparing kernel arguments#
The cuLaunchKernel API bindings retain low-level CUDA argument preparation requirements:
Each kernel argument is a
void*(i.e. pointer to the argument)kernelParamsis avoid**(i.e. pointer to a list of kernel arguments)kernelParamsarguments are in contiguous memory
These requirements can be met with two different approaches, using either NumPy or ctypes.
Using NumPy#
NumPy Array objects can be used to fulfill each of these conditions directly.
Let’s use the following kernel definition as an example:
kernel_string = """
typedef struct {
int value;
} testStruct;
extern "C" __global__
void testkernel(int i, int *pi,
float f, float *pf,
testStruct s, testStruct *ps)
{
*pi = i;
*pf = f;
ps->value = s.value;
}
"""
The first step is to create array objects with types corresponding to your kernel arguments. Primitive NumPy types have the following corresponding kernel types:
NumPy type |
Corresponding kernel types |
itemsize (bytes) |
|---|---|---|
bool |
bool |
1 |
int8 |
char, signed char, int8_t |
1 |
int16 |
short, signed short, int16_t |
2 |
int32 |
int, signed int, int32_t |
4 |
int64 |
long long, signed long long, int64_t |
8 |
uint8 |
unsigned char, uint8_t |
1 |
uint16 |
unsigned short, uint16_t |
2 |
uint32 |
unsigned int, uint32_t |
4 |
uint64 |
unsigned long long, uint64_t |
8 |
float16 |
half |
2 |
float32 |
float |
4 |
float64 |
double |
8 |
complex64 |
float2, cuFloatComplex, complex<float> |
8 |
complex128 |
double2, cuDoubleComplex, complex<double> |
16 |
Furthermore, custom NumPy types can be used to support both platform-dependent types and user-defined structures as kernel arguments.
This example uses the following types:
* int is np.uint32
* float is np.float32
* int*, float* and testStruct* are np.intp
* testStruct is a custom user type np.dtype([("value", np.int32)], align=True)
Note how all three pointers are np.intp since the pointer values are always a representation of an address space.
Putting it all together:
# Define a custom type
testStruct = np.dtype([("value", np.int32)], align=True)
# Allocate device memory
pInt = checkCudaErrors(cudart.cudaMalloc(np.dtype(np.int32).itemsize))
pFloat = checkCudaErrors(cudart.cudaMalloc(np.dtype(np.float32).itemsize))
pStruct = checkCudaErrors(cudart.cudaMalloc(testStruct.itemsize))
# Collect all input kernel arguments into a single tuple for further processing
kernelValues = (
np.array(1, dtype=np.uint32),
np.array([pInt], dtype=np.intp),
np.array(123.456, dtype=np.float32),
np.array([pFloat], dtype=np.intp),
np.array([5], testStruct),
np.array([pStruct], dtype=np.intp),
)
The final step is to construct a kernelParams argument that fulfills all of the launch API conditions. This is made easy because each array object comes
with NumPy’s ctypes data attribute that returns the underlying void* pointer value.
By having the final array object contain all pointers, we fulfill the contiguous array requirement:
kernelParams = np.array([arg.ctypes.data for arg in kernelValues], dtype=np.intp)
The launch API supports Buffer Protocol objects, therefore we can pass the array object directly:
checkCudaErrors(cuda.cuLaunchKernel(
kernel,
1, 1, 1, # grid dim
1, 1, 1, # block dim
0, stream, # shared mem and stream
kernelParams=kernelParams,
extra=0,
))
Using ctypes#
The ctypes approach relaxes the parameter preparation requirement by delegating the contiguous memory requirement to the API launch call.
Let’s use the same kernel definition as the previous section for the example.
The ctypes approach treats the kernelParams argument as a pair of two tuples: kernel_values and kernel_types.
kernel_valuescontain Python values to be used as an input to your kernelkernel_typescontain the data types that your kernel_values should be converted into
The ctypes fundamental data types documentation describes the compatibility between different Python types and C types. Furthermore, custom data types can be used to support kernels with custom types.
For this example the result becomes:
# Define a custom type
class testStruct(ctypes.Structure):
_fields_ = [("value", ctypes.c_int)]
# Allocate device memory
pInt = checkCudaErrors(cudart.cudaMalloc(ctypes.sizeof(ctypes.c_int)))
pFloat = checkCudaErrors(cudart.cudaMalloc(ctypes.sizeof(ctypes.c_float)))
pStruct = checkCudaErrors(cudart.cudaMalloc(ctypes.sizeof(testStruct)))
# Collect all input kernel arguments into a single tuple for further processing
kernelValues = (
1,
pInt,
123.456,
pFloat,
testStruct(5),
pStruct,
)
kernelTypes = (
ctypes.c_int,
ctypes.c_void_p,
ctypes.c_float,
ctypes.c_void_p,
None,
ctypes.c_void_p,
)
Values that are set to None have a special meaning:
The value supports a callable
getPtrthat returns the pointer address of the underlining C object address (e.g. all CUDA C types that are exposed to Python as Python classes)The value is an instance of
ctypes.StructureThe value is an
Enum
In all three cases, the API call will fetch the underlying pointer value and construct a contiguous array with other kernel parameters.
With the setup complete, the kernel can be launched:
checkCudaErrors(cuda.cuLaunchKernel(
kernel,
1, 1, 1, # grid dim
1, 1, 1, # block dim
0, stream, # shared mem and stream
kernelParams=(kernelValues, kernelTypes),
extra=0,
))
CUDA objects#
Certain CUDA kernels use native CUDA types as their parameters such as cudaTextureObject_t. These types require special handling since they’re neither a primitive ctype nor a custom user type. Since cuda.bindings exposes each of them as Python classes, they each implement getPtr() and __int__(). These two callables used to support the NumPy and ctypes approach. The difference between each call is further described under Tips and Tricks.
For this example, lets use the transformKernel from
simple_cubemap_texture.py.
The Examples page links to more samples covering textures, graphs,
memory mapping, and multi-GPU workflows.
simpleCubemapTexture = """\
extern "C"
__global__ void transformKernel(float *g_odata, int width, cudaTextureObject_t tex)
{
...
}
"""
def main():
...
d_data = checkCudaErrors(cudart.cudaMalloc(size))
width = 64
tex = checkCudaErrors(cudart.cudaCreateTextureObject(texRes, texDescr, None))
...
For NumPy, we can convert these CUDA types by leveraging the __int__() call to fetch the address of the underlying cudaTextureObject_t C object and wrapping it in a NumPy object array of type np.intp:
kernelValues = (
np.array([d_data], dtype=np.intp),
np.array(width, dtype=np.uint32),
np.array([int(tex)], dtype=np.intp),
)
kernelArgs = np.array([arg.ctypes.data for arg in kernelValues], dtype=np.intp)
For ctypes, we leverage the special handling of None type since each Python class already implements getPtr():
kernelValues = (
d_data,
width,
tex,
)
kernelTypes = (
ctypes.c_void_p,
ctypes.c_int,
None,
)
kernelArgs = (kernelValues, kernelTypes)