More Quantum Data for Less: Million-Fold Data Collection Speedups with PTSBE
There is a fundamental challenge in developing useful quantum computers. The quantum behavior that makes them so desirable to build also makes them difficult to simulate and design.
This becomes especially challenging when trying to model the noise in quantum computing hardware. The exact simulation of \(n\) ideal qubits requires tracking a number of parameters that grows like \( 2^n \), since an increasingly large vector must be tracked for larger quantum systems. But simulating noisy qubits requires not just tracking a Hilbert space vector, but a density matrix, described by \( 2^{2n} \) values - adding yet another quadratic overhead. Including noise is key when simulating new quantum processor designs, but this extra computational cost can be severe.
Thankfully, there is a solution. Quantum trajectory methods approximate noisy systems with an ensemble of stochastically sampled \( 2^n \)-entry statevectors rather than exact density matrices - removing the additional quadratic overhead.
Pre-Trajectory Sampling with Batched Execution (PTSBE) has dramatically improved the data collection rate of these methods. Among other advantages, PTSBE optimizes noisy quantum simulation by pre-sampling unique error operators and computing their trajectories before executing the quantum state. Pre-calculating these values allows batch-processing, which avoids having to carry out error operator calculations redundantly later on.
The most dramatic speedups from PTSBE come from non-proportional sampling1. In these modes, simulations are performed where the sampling deliberately deviates from the underlying quantum error probabilities in order to harvest as much data as possible from the evaluated states. While the datasets involved in these cases don't adhere to quantum error statistics, and so are not necessarily useful simulations for investigating quantum systems directly, they provide massive sets of data of huge value when raining AI models for quantum computing use-cases. A key example being the training of AI-based Quantum Error Correction (QEC) decoders.
Conversely, for applications that require exact physical modeling, PTSBE can perform proportional sampling1. Even when maintaining the underlying quantum statistics, PTSBE still achieves more modest, yet still highly impactful speedups by employing a redesigned simulation architecture, refactored to avoid degenerate work.
This blog will explore two distinct but closely related milestones in the evolution of this technique. First, we will examine how the original statevector PTSBE algorithm can be accessed in the NVIDIA CUDA-Q 0.14.0 release, achieving speedups upwards of \( 10^7\times \) for (proportional quantum, non-proportional error) data collection. Then, we will dive into new research that extends these principles to tensor networks, pushing non-proportional tensor network PTSBE performance into the \( 10^8\times \) data collection speedup regime, while still giving a \( 10^3\times \) speedup for the statistically accurate proportional version.
Statevector PTSBE Lands in CUDA-Q 0.14.0
The original statevector PTSBE paper demonstrated data collection speedups of many orders of magnitude, and these capabilities are available in the latest CUDA-Q 0.14.0 release through the new cudaq.ptsbe module in Python and cudaq::ptsbe namespace in C++. Developers can now use PTSBE to efficiently generate massive synthetic datasets of noisy quantum measurements.
Performance and Data Uniqueness
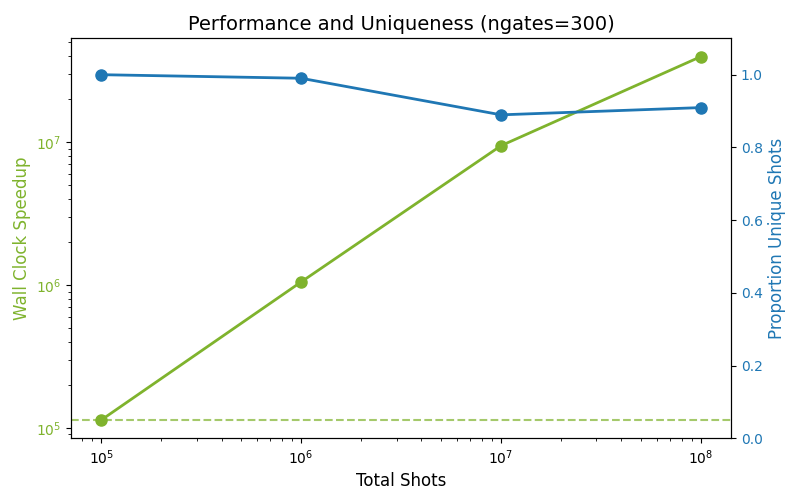
Fig 1: Performance and Uniqueness (ngates=300)
The true power of this implementation can be seen when analyzing statevector performance data for non-proportional error, proportional population sampling of a 300-gate circuit. As the total number of shots scales up by several orders of magnitude, the wall clock speedup increases linearly with the number of shots sampled, reaching up to tens of millions of times faster. Crucially, despite reusing pre-sampled trajectories, the percentage of unique shots remains incredibly high, hovering near 100% across all scales, showing the vast amount of training data that PTSBE can harvest from a subset of the system error sampling.
The Next Frontier: Tensor Network PTSBE
While statevector PTSBE has enjoyed massive success and production integration, tensor network implementations initially struggled due to poor path caching/reutilization strategies and inefficient sampling techniques. Unoptimized tensor network PTSBE only achieved a comparatively modest ~15x speedup against traditional trajectory simulations.
In recent work, we resolved the primary bottlenecks, pushing PTSBE's non-proportional tensor network data collection rate to more than \( 10^8\times \) that of traditional trajectory methods.
This was made possible through three key innovations:
- Unified Path Variations (UPV): An error-independent framework that merges error operands into deterministic gates, preserving network topology, so expensive path-finding subroutines are executed only once.
- Non-Degenerate Batched Sampling (NBS): A suite of methods designed to eliminate repeated, degenerate operations during tensor network partial sampling. A key insight is that PTSBE's computational cost scales with the number of unique measurement prefixes, not the total shot count. This means more shots cost proportionally less compute which provides a great efficiency boost over per-shot trajectory methods that grow with scale.
- Interface Flexibility: A dynamic interface exposing bespoke batch sizes, allowing fine-tuned hardware utilization to drastically increase the rate of contracted qubits per second.
The Power of Proportional Tensor Network Sampling
While the \( 10^8\times \) speedup for non-proportional sampling is ideal for AI workloads, our new tensor network optimizations also deliver massive gains for standard simulation tasks.
By utilizing UPV and optimized batch sizing, our proportional (both error and population) PTSBE implementation achieves a data collection speedup of \( 10^3\times \). Because this sampling is completely proportional, it adheres to traditional quantum statistics, this represents a massive, extremely general acceleration for tensor network trajectory simulations, achieved completely through algorithmic innovations without introducing any new approximations or restrictions.
With PTSBE fully integrated into CUDA-Q for statevectors and our newly optimized tensor network methodologies hitting unprecedented speeds, the generation of robust, large-scale noisy quantum data corpuses for training AI models is faster and more accessible than ever before.
Get Started
To start generating noisy quantum data with PTSBE, install CUDA-Q 0.14 and try the PTSBE examples.
Share on Share on Share on LinkedIn
-
Sampling algorithms can be proportional or non-proportional with respect to two unique sampling processes: 1) error sampling (i.e. whether the number of shots per state preparation is proportional to the probability of the corresponding error set) and 2) population sampling (whether the shots harvested from a state preparation are proportional to that state's populations). Proportional quantum error sampling is much easier to achieve in statevector simulations, as the entire population is, by definition, available. ↩↩