

FlashDreams#
FlashDreams
FlashDreams is an inference and serving runtime for turning autoregressive video and world models into live, controllable simulations. It runs the model in a continuous loop, carrying state forward and streaming frames while new actions or sensor inputs change what happens next, whether the application is a game world, an autonomous-vehicle simulator, robotic policy testing, or a virtual training environment.

Why FlashDreams?#
A world model learns to generate and evolve an environment over time. In practice that usually means video, but the same idea extends to actions, state, audio, sensor input, and control signals. Serving one means keeping a session alive while input, model state, GPU inference, and output advance together, rather than producing a single static clip, which is what makes interactive simulation, robotics, autonomy, and game-like experiences possible.
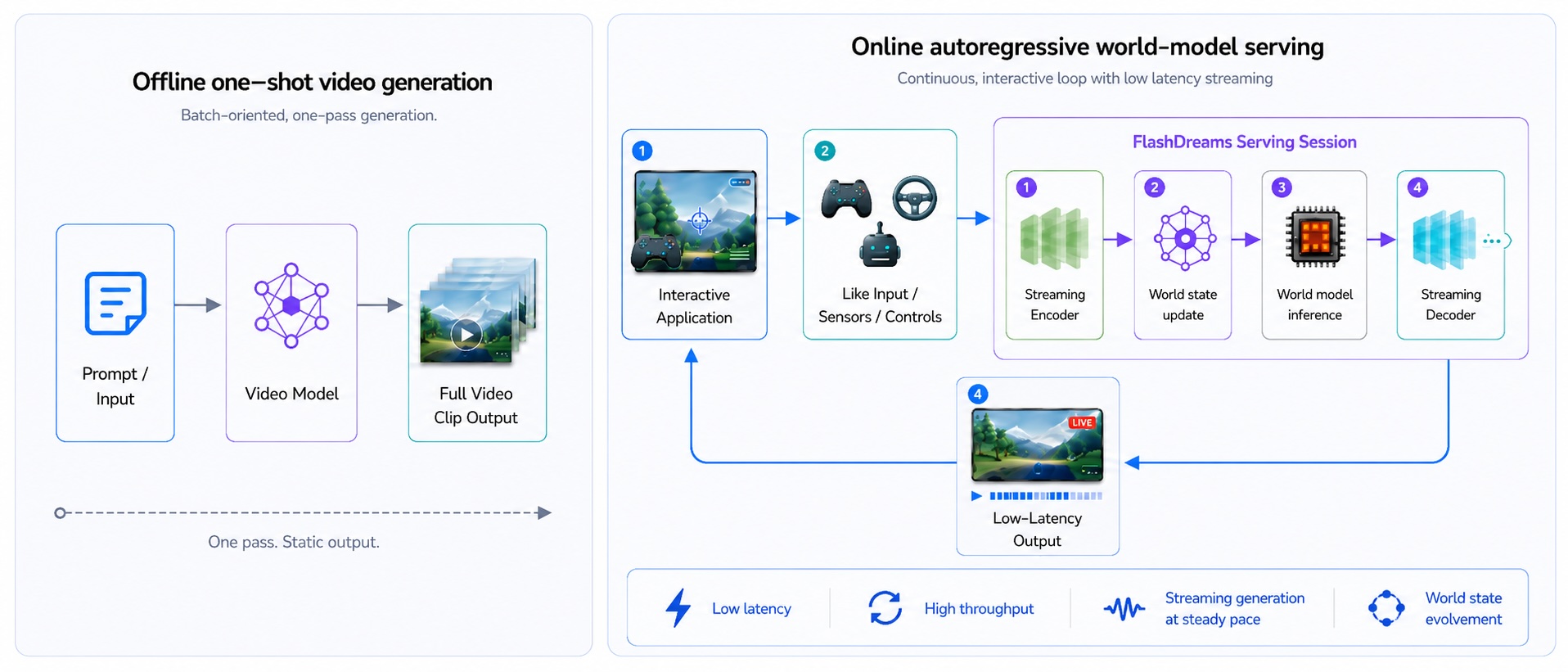
FlashDreams is built for that real-time case: a closed-loop world-model demo, a driving simulator, an interactive scene rollout. Generating high-quality video is not enough on its own. The runtime has to keep an interactive session responsive while the model continues to advance the world. That comes down to four things:
Keep the interaction responsive when controls, sensors, or user input change.
Keep the GPU busy across autoregressive steps and multi-GPU execution.
Stream frames or chunks at a steady pace while the session continues.
Carry rolling state forward so the generated world evolves across steps.
Performance#
Each tile shows the speedup over a separate existing implementation of the same model. Both runs use the same weights on the same GPU, so the gain comes from FlashDreams’ runtime alone. Each tile links to the profiling chart on its model page.
2.12×
Self-Forcing speedup
3.10×
LingBot-World speedup
1.40×
Wan2.1 speedup
1.42×
FlashVSR speedup
Try FlashDreams!#
FlashDreams brings best-in-class per-step latency to interactive autoregressive video and world models: multiple integrated models across streaming and bidirectional methods, multi-GPU execution, and one CLI to drive them all.
The Get Started guide walks from a fresh checkout to running OmniDreams, an interactive driving world-model demo built on FlashDreams.
Supported Models#
Streaming and autoregressive model implementations emit per-step output with sub-second latency once warm; bidirectional model implementations are kept as full-block parity references. Each model page carries the canonical invocation, the checkpoint source, and the per-implementation knobs.
Interactive world simulator for autonomous vehicles.
Autoregressive text-to-video based on Wan 2.1.
Autoregressive text/image-to-video based on Wan 2.1.
Autoregressive text-to-video based on Wan 2.2 from FastVideo.
Camera-controllable image-to-video world model.
Streaming video super-resolution.
Bidirectional video generation model that supports both text-to-video and image-to-video.
Bidirectional Cosmos-Predict2 reference implementations (T2V / I2V, 2B).