

Self-Forcing#
Self-Forcing is a text-to-video (T2V) model based on Wan2.1. It uses a training paradigm for autoregressive video diffusion that simulates inference-time rollout during training with KV caching, reducing the train-test gap and enabling efficient streaming generation quality.
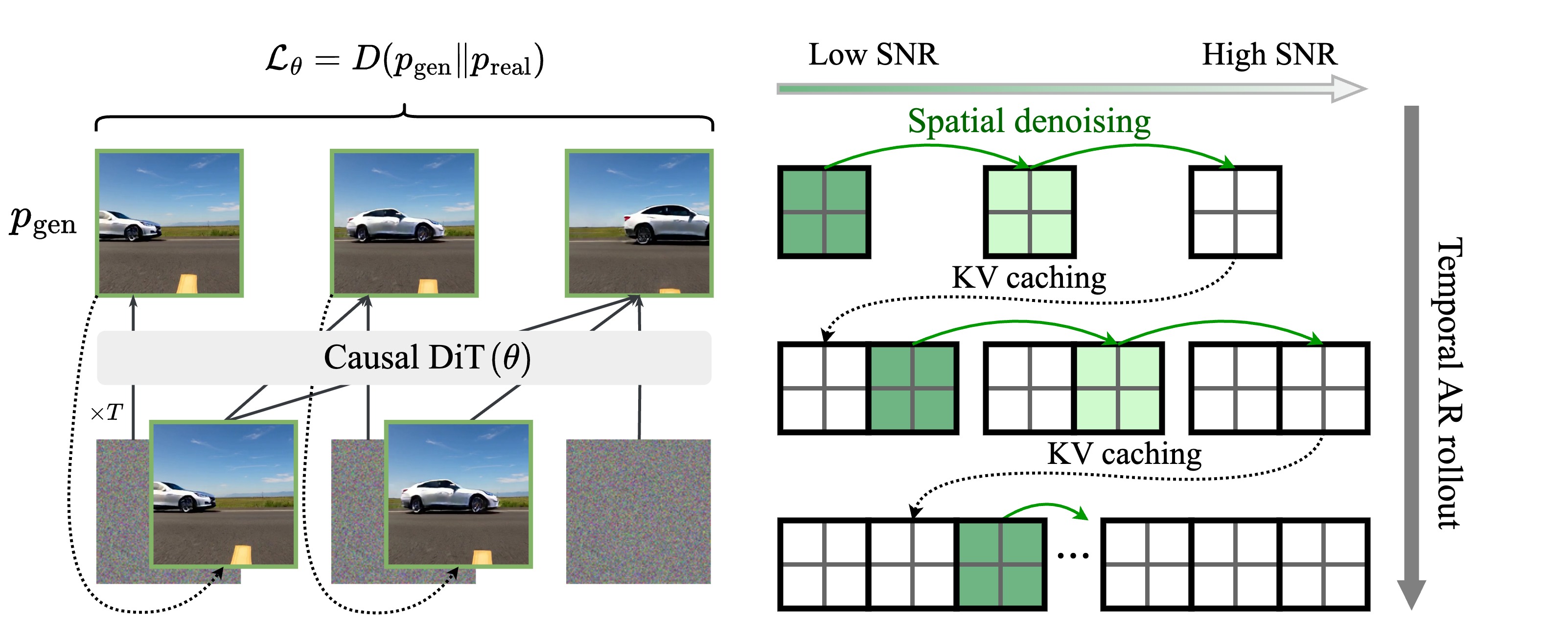
Teaser image source: Self-Forcing project page.
Requirements#
Minimum VRAM: ~24 GB.
PyTorch: >= 2.9.
Installation#
# from the repo root
uv sync --project integrations/self_forcing
Running the method#
To run Self-Forcing, launch one of the registered runner slugs. For example:
uv run --project integrations/self_forcing \
flashdreams-run \
self-forcing-wan2.1-t2v-1.3b \
--prompt "A stylish woman strolls down a bustling Tokyo street, the warm glow of neon lights and animated city signs casting vibrant reflections. She wears a sleek black leather jacket paired with a flowing red dress and black boots, her black purse slung over her shoulder. Sunglasses perched on her nose and a bold red lipstick add to her confident, casual demeanor. The street is damp and reflective, creating a mirror-like effect that enhances the colorful lights and shadows. Pedestrians move about, adding to the lively atmosphere. The scene is captured in a dynamic medium shot with the woman walking slightly to one side, highlighting her graceful strides." \
--pixel-height 480 --pixel-width 832 \
--total-blocks 7
We provide the following variants:
Method |
Description |
|---|---|
|
Official checkpoint. |
|
Official checkpoint. Swap Wan VAE decoder with the faster TAEHV decoder. |
|
Steady long-rollout preset: static sink=5 + rolling window=7, with KVCache-relative RoPE. |
For multi-GPU inference, use:
uv run --project integrations/self_forcing \
torchrun --nproc_per_node=4 --no-python flashdreams-run \
self-forcing-wan2.1-t2v-1.3b \
--prompt "A stylish woman strolls down a bustling Tokyo street, the warm glow of neon lights and animated city signs casting vibrant reflections. She wears a sleek black leather jacket paired with a flowing red dress and black boots, her black purse slung over her shoulder. Sunglasses perched on her nose and a bold red lipstick add to her confident, casual demeanor. The street is damp and reflective, creating a mirror-like effect that enhances the colorful lights and shadows. Pedestrians move about, adding to the lively atmosphere. The scene is captured in a dynamic medium shot with the woman walking slightly to one side, highlighting her graceful strides." \
--pixel-height 480 --pixel-width 832 \
--total-blocks 7
To inspect all supported CLI arguments and their default values, run:
uv run --project integrations/self_forcing \
flashdreams-run \
self-forcing-wan2.1-t2v-1.3b \
--help
What to expect#
Default prompt: omitting
--promptuses a Tokyo street-scene default. Override with an inline string or a path to a.txtfile.Total blocks:
--total-blocks NrunsNautoregressive chunks. Commands here use7for a fast demo; the config default is60for full rollouts. See Inference pipeline overview for what one chunk does end-to-end.Outputs:
outputs/<runner-slug>.mp4(16 FPS, 480×832 by default) andoutputs/stats_<runner-slug>.json. Override with--output-dir/--pixel-height/--pixel-width/--fps.
Measured runtimes on H100 80GB with --total-blocks 7:
Setup |
First run (cold) |
Subsequent runs |
|---|---|---|
1× H100 PCIe |
~6.9 min |
~42 s |
4× H100 HBM3 ( |
~8.6 min |
~73 s |
Cold runs are dominated by the first two AR blocks (Triton autotuning + CUDA-graph warmup); steady-state blocks are sub-second.
Per-block steady-state on 4 GPUs is ~2× faster (~251 ms vs ~500 ms),
but per-rank autotune + NCCL overhead makes 4 GPUs end-to-end slower
than 1 GPU at --total-blocks 7. Multi-GPU pays off once steady-state
dominates warmup — use it for --total-blocks 60+.
Some generated samples from the above commands:
Profiling benchmark#
Here is the profiling benchmark on total DiT runtime for FlashDreams Self-Forcing compared to the official Self-Forcing implementation and the FastVideo implementation under matched settings.
This chart shows the DiT total runtime (4 denoising steps in milliseconds) at the 6th autoregressive rollout on a single GPU.
For an apples-to-apples comparison, all implementations are forced to use cuDNN attention backend and torch.compile for DiT network.
For profiling the official implementation, see
this instruction.
For profiling the FastVideo implementation, see
this instruction.
Citation#
If you use Self-Forcing, please cite the original work:
@article{huang2026self,
title={Self forcing: Bridging the train-test gap in autoregressive video diffusion},
author={Huang, Xun and Li, Zhengqi and He, Guande and Zhou, Mingyuan and Shechtman, Eli},
journal={Advances in Neural Information Processing Systems},
volume={38},
pages={167283--167308},
year={2026}
}