Setting up the Simple Example
Creating Directories and Boilerplate Code
Make a directory for the example:
$ mkdir RetrievalAugmentedGeneration/examples/simple_rag_api_catalog
Create an empty
__init__.pyfile to indicate it is a Python module:$ touch RetrievalAugmentedGeneration/examples/simple_rag_api_catalog/__init__.py
Create a
RetrievalAugmentedGeneration/examples/simple_rag_api_catalog/chains.pyfile with the following boilerplate code:from typing import Generator, List, Dict, Any import logging from llama_index.core.base.response.schema import StreamingResponse from RetrievalAugmentedGeneration.common.base import BaseExample logger = logging.getLogger(__name__) class SimpleExample(BaseExample): def ingest_docs(self, file_name: str, filename: str): """Code to ingest documents.""" logger.info(f"Ingesting the documents") def llm_chain(self, query: str, chat_history: List["Message"], **kwargs) -> Generator[str, None, None]: """Code to form an answer using LLM when context is already supplied.""" logger.info(f"Forming response from provided context") return StreamingResponse(iter(["TODO: Implement LLM call"])).response_gen def rag_chain(self, query: str, chat_history: List["Message"], **kwargs) -> Generator[str, None, None]: """Code to fetch context and form an answer using LLM.""" logger.info(f"Forming response from document store") return StreamingResponse(iter(["TODO: Implement RAG chain call"])).response_gen def get_documents(self) -> List[str]: """Retrieve file names from the vector store.""" logger.info("Getting document file names from the vector store") return [] def delete_documents(self, filenames: List[str]) -> None: """Delete documents from the vector index.""" logger.info("Deleting documents from the vector index") def document_search(self, content: str, num_docs: int) -> List[Dict[str, Any]]: ## Optional method """Search for the most relevant documents for the given search parameters.""" logger.info("Searching for documents based on the query") return []
Building and Running with Docker Compose
Like the examples provided by NVIDIA, the simple example uses Docker Compose to build and run the example.
Create a
deploy/compose/simple-rag-api-catalog.yamlfile with the following content.The
EXAMPLE_NAMEfield identifies the directory, relative toRetrievalAugmentedGeneration/examplesto build for the chain server.services: chain-server: container_name: chain-server image: chain-server:latest build: context: ../../ dockerfile: ./RetrievalAugmentedGeneration/Dockerfile args: EXAMPLE_NAME: simple_rag_api_catalog command: --port 8081 --host 0.0.0.0 environment: APP_LLM_MODELNAME: ai-mixtral-8x7b-instruct APP_LLM_MODELENGINE: nvidia-ai-endpoints APP_EMBEDDINGS_MODELNAME: snowflake/arctic-embed-l APP_EMBEDDINGS_MODELENGINE: nvidia-ai-endpoints APP_TEXTSPLITTER_CHUNKSIZE: 1200 APP_TEXTSPLITTER_CHUNKOVERLAP: 200 NVIDIA_API_KEY: ${NVIDIA_API_KEY} APP_PROMPTS_CHATTEMPLATE: "You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Please ensure that your responses are positive in nature." APP_PROMPTS_RAGTEMPLATE: "You are a helpful AI assistant named Envie. You will reply to questions only based on the context that you are provided. If something is out of context, you will refrain from replying and politely decline to respond to the user." APP_RETRIEVER_TOPK: 4 APP_RETRIEVER_SCORETHRESHOLD: 0.25 ports: - "8081:8081" expose: - "8081" shm_size: 5gb deploy: resources: reservations: devices: - driver: nvidia count: 1 capabilities: [gpu] rag-playground: container_name: rag-playground image: rag-playground:latest build: context: ../.././RetrievalAugmentedGeneration/frontend/ dockerfile: Dockerfile command: --port 8090 environment: APP_SERVERURL: http://chain-server APP_SERVERPORT: 8081 APP_MODELNAME: ai-mixtral-8x7b-instruct RIVA_API_URI: ${RIVA_API_URI:-} RIVA_API_KEY: ${RIVA_API_KEY:-} RIVA_FUNCTION_ID: ${RIVA_FUNCTION_ID:-} TTS_SAMPLE_RATE: ${TTS_SAMPLE_RATE:-48000} ports: - "8090:8090" expose: - "8090" depends_on: - chain-server networks: default: name: nvidia-rag
Build the containers for the simple example:
$ docker compose --env-file deploy/compose/compose.env -f deploy/compose/simple-rag-api-catalog.yaml build
Building the containers requires several minutes.
Run the containers:
$ docker compose --env-file deploy/compose/compose.env -f deploy/compose/simple-rag-api-catalog.yaml up -d
Verify the Chain Server Methods Using Curl
You can access the Chain Server with a URL like http://localhost:8081.
Confirm the
llm_chainmethod runs and returns the TODO response by running a command like the following:$ curl -H "Content-Type: application/json" http://localhost:8081/generate \ -d '{"messages":[{"role":"user", "content":"What should I see in Paris?"}], "use_knowledge_base": false}'
The response shows the TODO message:
data: {"id":"57d16654-6cc0-474a-832b-7563bf4eb1ce","choices":[{"index":0,"message":{"role":"assistant","content":"TODO: Implement LLM call"},"finish_reason":""}]} data: {"id":"57d16654-6cc0-474a-832b-7563bf4eb1ce","choices":[{"index":0,"message":{"role":"assistant","content":""},"finish_reason":"[DONE]"}]}
Confirm the
rag_chainmethod runs by settinguse_knowledge_basetotrue:$ curl -H "Content-Type: application/json" http://localhost:8081/generate \ -d '{"messages":[{"role":"user", "content":"What should I see in Paris?"}], "use_knowledge_base": true}'
The response also shows the TODO message:
data: {"id":"dc99aaf0-b6ab-4332-bbf2-4b53fc72f963","choices":[{"index":0,"message":{"role":"assistant","content":"TODO: Implement RAG chain call"},"finish_reason":""}]} data: {"id":"dc99aaf0-b6ab-4332-bbf2-4b53fc72f963","choices":[{"index":0,"message":{"role":"assistant","content":""},"finish_reason":"[DONE]"}]}
Confirm the
ingest_docsmethod runs by uploading a sample document, such as the README from the repository:$ curl http://localhost:8081/documents -F "file=@README.md"
Example Output
{"message":"File uploaded successfully"}
View the logs for the Chain Server to see the logged message from the method:
$ docker logs chain-server
The logs show the message from the code, but no ingest process:
INFO:example:Ingesting the documentsConfirm the
get_documentsanddelete_documentsmethods run:$ curl -X GET http://localhost:8081/documents
$ curl -X DELETE http://localhost:8081/documents\?filename\=README.md
View the logs for the Chain Server to see the logged messages from the methods:
$ docker logs chain-server
The logs show the message from the code:
INFO:example:Getting document file names from the vector store INFO:example:Deleting documents from the vector index
Confirm the
document_searchmethod runs:$ curl -H "Content-Type: application/json" http://localhost:8081/search \ -d '{"query":"What should I see in Paris?", "top_k":4}'
The response is empty because the
ingest_docsanddocument_searchmethods are not implemented:{"chunks":[]}
View the logs for the Chain Server to see the logged message from the method:
$ docker logs chain-server
Example Output
INFO:example:Searching for documents based on the query
Verify the Chain Server Methods Using the RAG Playground
You can access the RAG Playground web interface with a URL like http://localhost:8090.
Confirm the
llm_chainmethod runs by accessing http://localhost:8090/converse and entering a query such asWhat should I see in Paris?.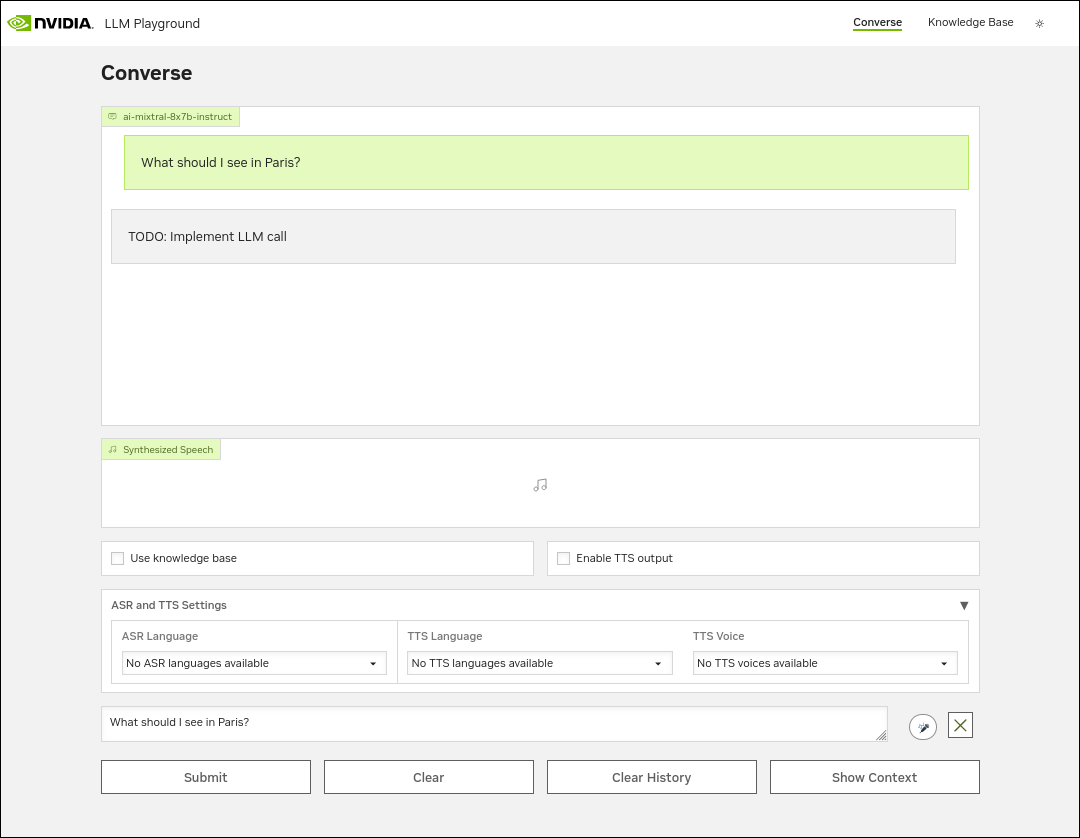
Confirm the
rag_chainmethod runs by enabling the Use knowledge base checkbox and entering a query.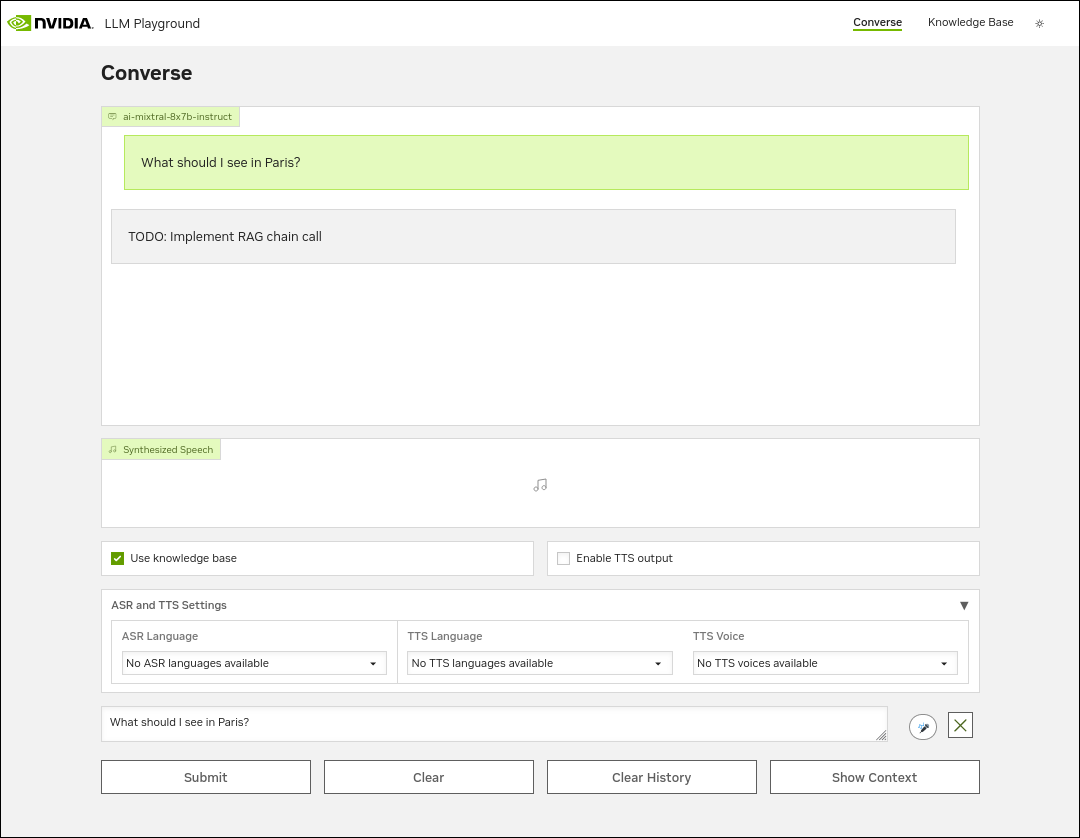
Confirm the
ingest_docsmethod runs by accessing http://localhost:8090/kb, clicking Add File, and uploading a file.After the upload, view the Chain Server logs by running
docker logs chain-server.Example Output
INFO:example:Ingesting the documents