Developing Simple Examples
About the Purpose and Process
The purpose of the example is to show how to develop a RAG example. The example uses models from the NVIDIA API Catalog. Using models from the catalog simplifies the initial setup by avoiding the steps to download a model and run an inference server. The endpoints from the catalog serve as both an embedding and an inference server.
The following pages show the sample code for gradually implementing the methods of a chain server that use LlamaIndex utility functions.
Key Considerations for the Simple RAG
The simple example uses the build and configuration approach that NVIDIA provided examples use. Reusing the build and configuration enables the sample to focus on the basics of developing the RAG code.
The key consideration for the RAG code is to implement three required methods and one optional method:
- ingest_docs
The chain server run this method when you upload documents to use as a knowledge base.
- llm_chain
The chain server runs this method when a query does not rely on retrieval.
- rag_chain
The chain server runs this method when you request to use the knowledge base and use retrieval to answer a query.
- get_documents
The chain server runs this method when you access the
/documentsendpoint with a GET request.- delete_documents
The chain server runs this method when you access the
/documentsendpoint with a DELETE request.- document_search
This is an optional method that enables you to perform the same document search that the
rag_chainmethod runs.
Prerequisites
The following prerequisites are common for using models from the NVIDIA API Catalog. If you already performed these steps, you do not need to repeat them.
Clone the Generative AI examples Git repository using Git LFS:
$ sudo apt -y install git-lfs $ git clone git@github.com:NVIDIA/GenerativeAIExamples.git $ cd GenerativeAIExamples/ $ git lfs pull
Install Docker Engine and Docker Compose. Refer to the instructions for Ubuntu.
Login to Nvidia’s docker registry. Please refer to instructions to create account and generate NGC API key. This is needed for pulling in the secure base container used by all the examples.
$ docker login nvcr.io Username: $oauthtoken Password: <ngc-api-key>
Optional: Enable NVIDIA Riva automatic speech recognition (ASR) and text to speech (TTS).
To launch a Riva server locally, refer to the Riva Quick Start Guide.
In the provided
config.shscript, setservice_enabled_asr=trueandservice_enabled_tts=true, and select the desired ASR and TTS languages by adding the appropriate language codes toasr_language_codeandtts_language_code.After the server is running, assign its IP address (or hostname) and port (50051 by default) to
RIVA_API_URIindeploy/compose/compose.env.
Alternatively, you can use a hosted Riva API endpoint. You might need to obtain an API key and/or Function ID for access.
In
deploy/compose/compose.env, make the following assignments as necessary:export RIVA_API_URI="<riva-api-address/hostname>:<port>" export RIVA_API_KEY="<riva-api-key>" export RIVA_FUNCTION_ID="<riva-function-id>"
Get an NVIDIA API Key
The following steps describe how to get an NVIDIA API key for the Mixtral 8x7B Instruct API Endpoint. If you already performed these steps, you do not need to repeat them.
Perform the following steps if you do not already have an API key. You can use different model API endpoints with the same API key.
Navigate to https://build.nvidia.com/explore/discover.
Find the Llama 3 70B Instruct card and click the card.
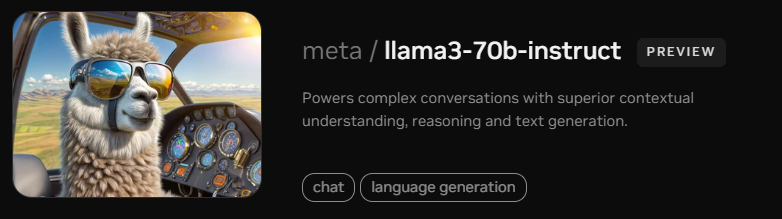
Click Get API Key.
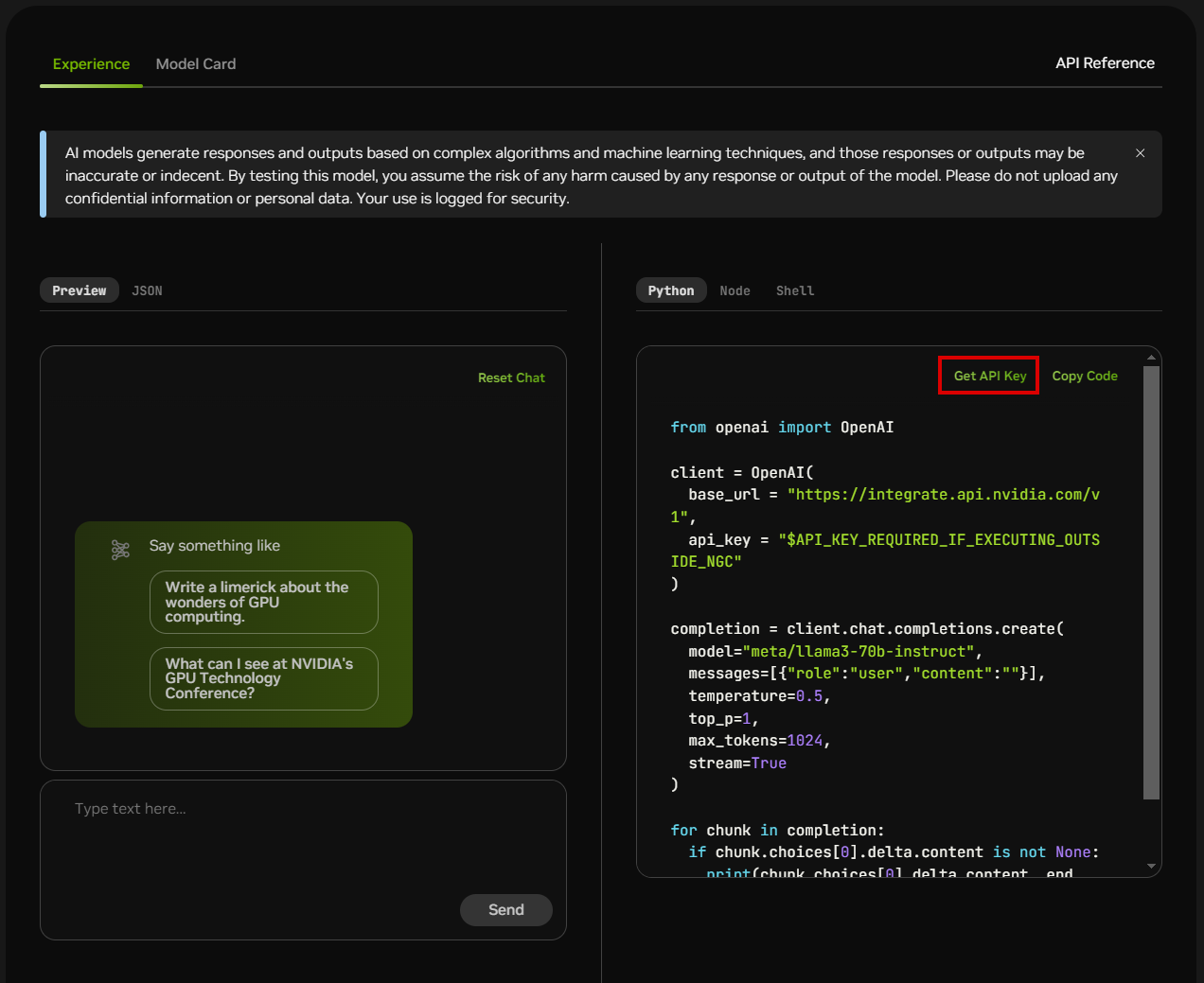
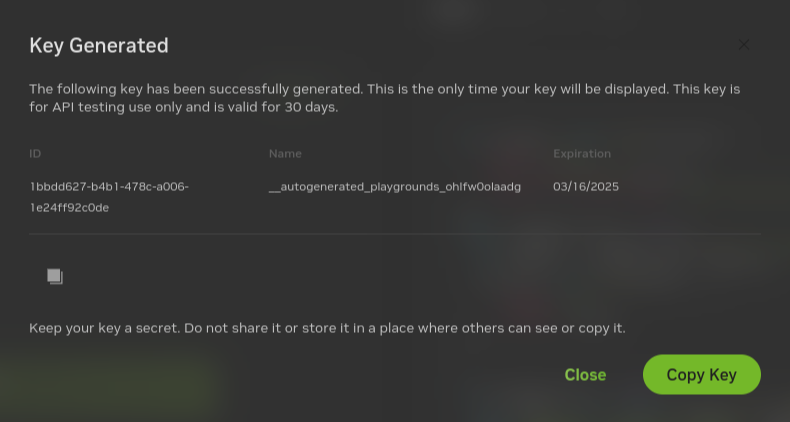
Click Generate Key.

Click Copy Key and then save the API key. The key begins with the letters nvapi-.
Custom Requirements
The sample code for implementing the Chain Server is basic.
As you experiment and implement custom requirements, you might need to use additional Python packages.
You can install your Python dependencies by creating a requirements.txt file in your example directory.
When you build the Docker image, the build process automatically installs the packages from the requirements file.
You might find conflicts in the dependencies from the requirements file and the common dependencies used by the Chain Server. In these cases, the custom requirements file is given a higher priority when Python resolves dependencies. Your packages and versions can break some of the functionality of the utility methods in the chain server.
If your example uses any utility methods, check the chain server logs to troubleshoot dependency conflicts. If any of the packages required by the utility methods causes an error, the error is logged by the chain server during initialization. These errors do not stop the execution of the chain server. However, if your example attempts to use a utility method that depends on a broken package, the chain server can produce unexpected behavior or crashes. You must use dependencies that do not conflict with the chain server requirements, or do not rely on utility methods that are affected by the dependency conflict.