How to add a new processor?#
We will describe how to make your own processor classes by referring to SDP’s existing classes.
To understand this section better, it might be useful to skim through the description of the SDP’s base classes.
Creating an initial manifest#
One of the child classes of sdp.processors.base_processor.BaseParallelProcessor provided in SDP is
sdp.processors.CreateInitialManifestMLS.
- class sdp.processors.CreateInitialManifestMLS(raw_data_dir: str, language: str, data_split: str, resampled_audio_dir: str | None, target_samplerate: int = 16000, target_nchannels: int = 1, use_opus_archive: bool = False, **kwargs)[source]#
Bases:
BaseParallelProcessorProcessor to create initial manifest for the Multilingual LibriSpeech (MLS) dataset.
Dataset link: https://www.openslr.org/94/
Downloads and unzips raw MLS data for the specified language, and creates an initial manifest using the transcripts provided in the raw data.
- Parameters:
raw_data_dir (str) – the directory where the downloaded data will be/is saved. This is also where the extracted and processed data will be.
language (str) – the language of the data you wish to be downloaded. This will be used to format the URL from which we attempt to download the data. E.g., “english”, “italian”, “spanish”, etc.
data_split (str) – “train”, “dev” or “test”.
resampled_audio_dir (str or None) – if specified, the directory where the resampled wav files will be stored. If not specified, the audio will not be resampled and the parameters
target_samplerateandtarget_nchannelswill be ignored.target_samplerate (int) – sample rate (Hz) to use for resampling. This parameter will be ignored if
resampled_audio_dirisNone. Defaults to 16000.target_nchannels (int) – number of channels to create during resampling process. This parameter will be ignored if
resampled_audio_dirisNone. Defaults to 1.use_opus_archive (bool) – if
True, will use the version of the archive file which contains audio files saved in the OPUS format, instead of FLAC. The OPUS files take up less memory than the FLAC files, at the cost of the OPUS files being lower quality than the FLAC files. IfTrue, the parameterresampled_audio_dirmust beNone, as resampling OPUS audio files is currently not supported. Defaults to False.
- Returns:
This processor generates an initial manifest file with the following fields:
{ "audio_filepath": <path to the audio file>, "duration": <duration of the audio in seconds>, "text": <transcription>, }
It downloads raw MLS data for a specified language, and creates an initial manifest (in the format expected by NeMo) which can be cleaned by subsequent processors.
The sdp.processors.CreateInitialManifestMLS.prepare() method downloads and extracts the raw data.
The sdp.processors.CreateInitialManifestMLS.read_manifest() method reads the lines in the raw MLS transcript file.
The sdp.processors.CreateInitialManifestMLS.process_dataset_entry() method takes in the lines from the raw MLS
transcript file, and outputs DataEntry objects containing entries that will be saved into the
manifest (i.e. audio_filepath, duration, text) for each utterance.
Cleaning the reference text#
One of the classes provided in SDP is sdp.processors.SubRegex.
- class sdp.processors.SubRegex(regex_params_list: List[Dict] = None, regex_params_yaml: str = None, text_key: str = 'text', **kwargs)[source]#
Bases:
BaseParallelProcessorApplies a sequence of regex substitutions to the specified text field in each data entry.
This processor performs regex-based substitutions as defined in either a provided list of regex parameter dictionaries or a YAML configuration file. Each substitution is applied in the order specified.
Before substitutions are applied, a space is temporarily added to the beginning and end of the text to improve regex match consistency. After all substitutions, leading/trailing spaces and repeated spaces are removed.
- Parameters:
regex_params_list (List[Dict], optional) –
A list of dictionaries specifying the regex substitutions. Each dictionary must include:
- "pattern": A regex pattern to match. - "repl": A replacement string. - "count" (optional): Maximum number of replacements to make. Defaults to 0 (replace all).
regex_params_yaml (str, optional) – Path to a YAML file that defines the same list of dictionaries as regex_params_list. Either regex_params_list or regex_params_yaml must be provided. If both are provided, regex_params_yaml takes precedence.
text_key (str) – The key in each data entry whose value will be modified. Defaults to “text”.
**kwargs – Additional arguments passed to the BaseParallelProcessor.
- Example YAML format for regex_params_yaml:
` # regex_params.yaml - {"pattern": "♩", "repl": " "} - {"pattern": "♭", "repl": " "} - {"pattern": "\|", "repl": " "} - {"pattern": ":", "repl": " "} - {"pattern": "-", "repl": " "} - {"pattern": "[^ €₽₴$£%?!',.0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЬЮЯабвгдежзийклмнопрстуфхцчшщъьюя]", "repl": ""} - {"pattern": "\s+\.", "repl": "."} - {"pattern": "\?+", "repl": "?"} - {"pattern": "\.+", "repl": "."} `
- Returns:
The same data as in the input manifest with
<text_key>field changed.
At initialization, it takes in regex_params_list, a list of dictionaries which must contain the
keys pattern, repl, and, optionally, count.
These keys will be used to apply regex substitutions using these parameters fed into
re.sub. The substitutions will be applied to the data at text_key
(i.e. data_entry.data[self.text_key]). By default, text_key="text", i.e. the substitutions
will be applied to the "text" attribute of the manifest.
In its sdp.processors.SubRegex.process_dataset_entry() method, the
processor does the string to string conversion upon the data_entry that is input.
Its output is a data_entry with the changes applied to data, and the the metrics of
which regex patterns caused a substitution to be made.
These metrics will be aggregated over all utterances by the
sdp.processors.base_processor.BaseParallelProcessor class.
sdp.processors.SubRegex also has a sdp.processors.SubRegex.finalize() method which will log
information about the aggregated metrics after all of the utterances in the manifest have been processed.
Filtering incorrect transcriptions#
One of the classes provided in SDP is sdp.processors.DropHighLowCharrate.
- class sdp.processors.DropHighLowCharrate(high_charrate_threshold: float, low_charrate_threshold: float, text_key: str = 'text', **kwargs)[source]#
Bases:
BaseParallelProcessorDrops utterances if their character rate is too low or too high.
Character rate =
(num of characters in self.text_key) / (duration of audio). A too-low or too-high character rate often implies that the ground truth transcription might be inaccurate.- Parameters:
high_charrate_threshold (float) – upper character rate threshold. If the character rate of an utterance is higher than this number, the utterance will be dropped.
low_charrate_threshold (float) – lower character rate threshold. If the character rate of an utterance is lower than this number, the utterance will be dropped.
text_key (str) – a string indicating which key of the data entries should be used to find the utterance transcript. Defaults to “text”.
- Returns:
The same data as in the input manifest with some entries dropped.
At initialization, it takes in high_charrate_threshold and low_charrate_threshold,
for which the utterance will be dropped if it is above or below each value respectively.
This is helpful for automatically filtering out incorrectly transcribed utterances.
In its sdp.processors.DropHighLowCharrate.process_dataset_entry() method it evaluates the character rate of
the utterance(by dividing the length of data_entry.data[self.text_key] by the value of
data_entry.data["duration"]). If the character rate is within bounds, it will return the
same data_entry that was input. If the character rate is out of bounds, it will return
a data_entry with data=None and metrics which reflect the applied changes.
Similar to the sdp.processors.SubRegex class, it has a sdp.processors.DropHighLowCharrate.finalize()
method which will log information about the aggregated metrics after all of the utterances
in the manifest have been processed.
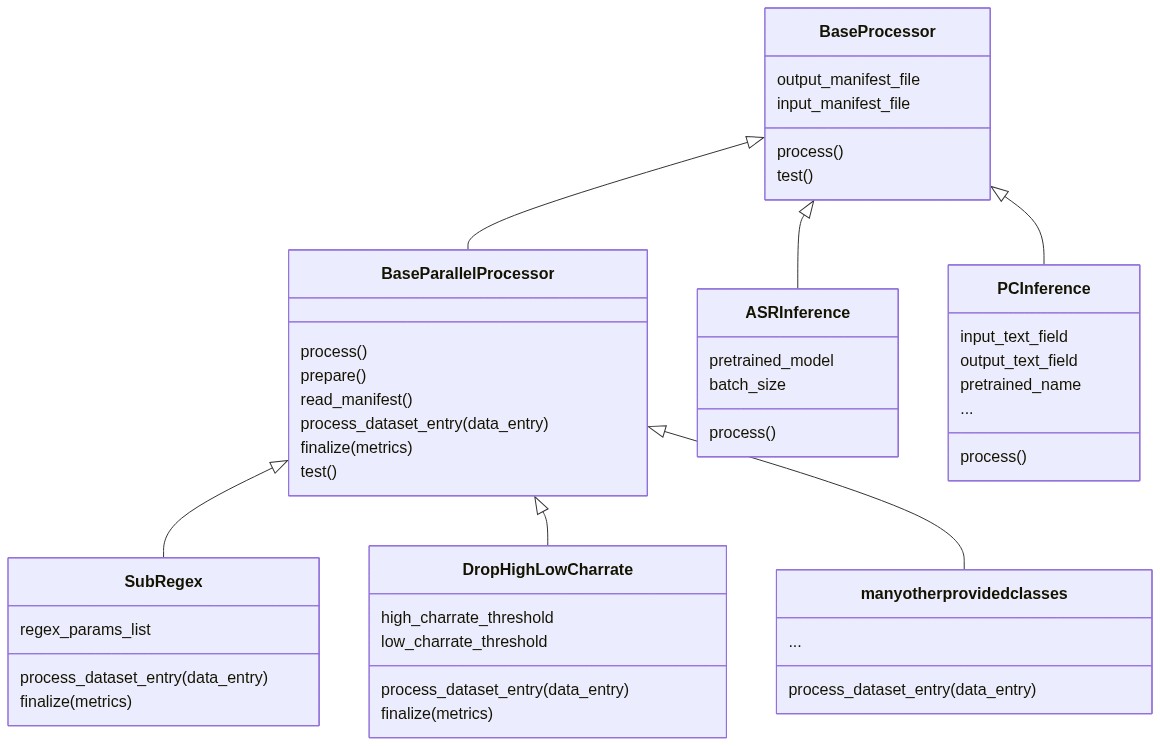
Class diagram#
A diagram of the classes mentioned above is included here. Arrows represent inheritance.