cub::BlockRadixSort#
BlockRadixSort class provides collective methods for sorting items partitioned across a CUDA thread block using a radix sorting method.
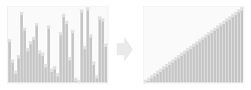
Overview#
The radix sorting method arranges items into ascending order. It relies upon a positional representation for keys, i.e., each key is comprised of an ordered sequence of symbols (e.g., digits, characters, etc.) specified from least-significant to most-significant. For a given input sequence of keys and a set of rules specifying a total ordering of the symbolic alphabet, the radix sorting method produces a lexicographic ordering of those keys.
For multi-dimensional blocks, threads are linearly ranked in row-major order.
Supported Types#
BlockRadixSort can sort all of the built-in C++ numeric primitive types (
unsigned char,int,double, etc.) as well as CUDA’s__halfhalf-precision floating-point type. User-defined types are supported as long as decomposer object is provided.Floating-Point Special Cases#
Positive and negative zeros are considered equivalent, and will be treated as such in the output.
No special handling is implemented for NaN values; these are sorted according to their bit representations after any transformations.
Bitwise Key Transformations#
Although the direct radix sorting method can only be applied to unsigned integral types, BlockRadixSort is able to sort signed and floating-point types via simple bit-wise transformations that ensure lexicographic key ordering.
These transformations must be considered when restricting the
[begin_bit, end_bit)range, as the bitwise transformations will occur before the bit-range truncation.Any transformations applied to the keys prior to sorting are reversed while writing to the final output buffer.
Type Specific Bitwise Transformations#
To convert the input values into a radix-sortable bitwise representation, the following transformations take place prior to sorting:
For unsigned integral values, the keys are used directly.
For signed integral values, the sign bit is inverted.
For positive floating point values, the sign bit is inverted.
For negative floating point values, the full key is inverted.
No Descending Sort Transformations#
Unlike
DeviceRadixSort,BlockRadixSortdoes not invert the input key bits when performing a descending sort. Instead, it has special logic to reverse the order of the keys while sorting.Stability#
BlockRadixSort is stable. For floating-point types -0.0 and +0.0 are considered equal and appear in the result in the same order as they appear in the input.
Performance Considerations#
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.
A Simple Example#
Every thread in the block uses the BlockRadixSort class by first specializing the BlockRadixSort type, then instantiating an instance with parameters for communication, and finally invoking one or more collective member functions.
The code snippet below illustrates a sort of 512 integer keys that are partitioned in a [<em>blocked arrangement</em>](../index.html#sec5sec3) across 128 threads where each thread owns 4 consecutive items.
#include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh> __global__ void kernel(...) { // Specialize BlockRadixSort for a 1D block of 128 threads owning 4 integer items each using BlockRadixSort = cub::BlockRadixSort<int, 128, 4>; // Allocate shared memory for BlockRadixSort __shared__ typename BlockRadixSort::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads int thread_keys[4]; ... // Collectively sort the keys BlockRadixSort(temp_storage).Sort(thread_keys); ...
from cuda import coop from pynvjitlink import patch patch.patch_numba_linker(lto=True) # Specialize radix sort for a 1D block of 128 threads owning 4 integer items each block_radix_sort = coop.block.radix_sort_keys(numba.int32, 128, 4) temp_storage_bytes = block_radix_sort.temp_storage_bytes @cuda.jit(link=block_radix_sort.files) def kernel(): Allocate shared memory for radix sort temp_storage = cuda.shared.array(shape=temp_storage_bytes, dtype='uint8') # Obtain a segment of consecutive items that are blocked across threads thread_keys = cuda.local.array(shape=items_per_thread, dtype=numba.int32) # ... // Collectively sort the keys block_radix_sort(temp_storage, thread_keys) # ...
Suppose the set of input
thread_keysacross the block of threads is{ [0,511,1,510], [2,509,3,508], [4,507,5,506], ..., [254,257,255,256] }. The corresponding outputthread_keysin those threads will be{ [0,1,2,3], [4,5,6,7], [8,9,10,11], ..., [508,509,510,511] }.- Template Parameters:
KeyT – KeyT type
BlockDimX – The thread block length in threads along the X dimension
ItemsPerThread – The number of items per thread
ValueT – [optional] ValueT type (default: cub::NullType, which indicates a keys-only sort)
RadixBits – [optional] The number of radix bits per digit place (default: 4 bits)
MemoizeOuterScan – [optional] Whether or not to buffer outer raking scan partials to incur fewer shared memory reads at the expense of higher register pressure (default: true for architectures SM35 and newer, false otherwise).
InnerScanAlgorithm – [optional] The cub::BlockScanAlgorithm algorithm to use (default: cub::BLOCK_SCAN_WARP_SCANS)
SMemConfig – **[optional]*8 Shared memory bank mode (default:
cudaSharedMemBankSizeFourByte)BlockDimY – [optional] The thread block length in threads along the Y dimension (default: 1)
BlockDimZ – [optional] The thread block length in threads along the Z dimension (default: 1)
Collective constructors
-
inline BlockRadixSort()#
Collective constructor using a private static allocation of shared memory as temporary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
-
inline BlockRadixSort(TempStorage &temp_storage)#
Collective constructor using the specified memory allocation as temporary storage.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
- Parameters:
temp_storage – [in] Reference to memory allocation having layout type TempStorage
Sorting (blocked arrangements)
- inline void Sort(
- KeyT (&keys)[ItemsPerThread],
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8
Performs an ascending block-wide radix sort over a blocked arrangement of keys.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
The code snippet below illustrates a sort of 512 integer keys that are partitioned in a blocked arrangement across 128 threads where each thread owns 4 consecutive keys.
#include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh> __global__ void ExampleKernel(...) { // Specialize BlockRadixSort for a 1D block of 128 threads owning 4 integer keys each using BlockRadixSort = cub::BlockRadixSort<int, 128, 4>; // Allocate shared memory for BlockRadixSort __shared__ typename BlockRadixSort::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads int thread_keys[4]; ... // Collectively sort the keys BlockRadixSort(temp_storage).Sort(thread_keys);
Suppose the set of input
thread_keysacross the block of threads is{ [0,511,1,510], [2,509,3,508], [4,507,5,506], ..., [254,257,255,256] }. The corresponding outputthread_keysin those threads will be{ [0,1,2,3], [4,5,6,7], [8,9,10,11], ..., [508,509,510,511] }.- Parameters:
keys – [inout] Keys to sort
begin_bit – [in] [optional] The beginning (least-significant) bit index needed for key comparison
end_bit – [in] [optional] The past-the-end (most-significant) bit index needed for key comparison
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> Sort( - KeyT (&keys)[ItemsPerThread],
- DecomposerT decomposer,
- int begin_bit,
- int end_bit
Performs an ascending block-wide radix sort over a blocked arrangement of keys.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 2 keys that are partitioned in a blocked arrangement across 2 threads where each thread owns 1 key.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 1 key each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 1>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][1] = // {{ {24.2, 1ll << 61} // thread 0 keys }, { {42.4, 1ll << 60} // thread 1 keys }}; constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000001110000011001100110011010 00100000000000...0000 // decompose(in[1]) = 01000010001010011001100110011010 00010000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> // Collectively sort the keys block_radix_sort_t(temp_storage).Sort(thread_keys[threadIdx.x], decomposer_t{}, begin_bit, end_bit); custom_t expected_output[2][3] = // {{ {42.4, 1ll << 60}, // thread 0 expected keys }, { {24.2, 1ll << 61} // thread 1 expected keys }};
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> Sort( - KeyT (&keys)[ItemsPerThread],
- DecomposerT decomposer
Performs an ascending block-wide radix sort over a blocked arrangement of keys.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 6 keys that are partitioned in a blocked arrangement across 2 threads where each thread owns 3 consecutive keys.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 3 keys each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 3>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][3] = // {{ // thread 0 keys {+2.5, 4}, // {-2.5, 0}, // {+1.1, 3}, // }, { // thread 1 keys {+0.0, 1}, // {-0.0, 2}, // {+3.7, 5} // }}; // Collectively sort the keys block_radix_sort_t(temp_storage).Sort(thread_keys[threadIdx.x], decomposer_t{}); custom_t expected_output[2][3] = // {{ // thread 0 expected keys {-2.5, 0}, // {+0.0, 1}, // {-0.0, 2} // }, { // thread 1 expected keys {+1.1, 3}, // {+2.5, 4}, // {+3.7, 5} // }};
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- inline void Sort(
- KeyT (&keys)[ItemsPerThread],
- ValueT (&values)[ItemsPerThread],
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8
Performs an ascending block-wide radix sort across a blocked arrangement of keys and values.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
BlockRadixSort can only accommodate one associated tile of values. To “truck along” more than one tile of values, simply perform a key-value sort of the keys paired with a temporary value array that enumerates the key indices. The reordered indices can then be used as a gather-vector for exchanging other associated tile data through shared memory.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
The code snippet below illustrates a sort of 512 integer keys and values that are partitioned in a blocked arrangement across 128 threads where each thread owns 4 consecutive pairs.
#include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh> __global__ void ExampleKernel(...) { // Specialize BlockRadixSort for a 1D block of 128 threads owning 4 integer keys and values each using BlockRadixSort = cub::BlockRadixSort<int, 128, 4, int>; // Allocate shared memory for BlockRadixSort __shared__ typename BlockRadixSort::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads int thread_keys[4]; int thread_values[4]; ... // Collectively sort the keys and values among block threads BlockRadixSort(temp_storage).Sort(thread_keys, thread_values);
@endcode @par Suppose the set of input
thread_keysacross the block of threads is{ [0,511,1,510], [2,509,3,508], [4,507,5,506], ..., [254,257,255,256] }. The corresponding outputthread_keysin those threads will be{ [0,1,2,3], [4,5,6,7], [8,9,10,11], ..., [508,509,510,511] }.- Parameters:
keys – [inout] Keys to sort
values – [inout] Values to sort
begin_bit – [in] [optional] The beginning (least-significant) bit index needed for key comparison
end_bit – [in] [optional] The past-the-end (most-significant) bit index needed for key comparison
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> Sort( - KeyT (&keys)[ItemsPerThread],
- ValueT (&values)[ItemsPerThread],
- DecomposerT decomposer,
- int begin_bit,
- int end_bit
Performs an ascending block-wide radix sort over a blocked arrangement of keys and values.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
BlockRadixSort can only accommodate one associated tile of values. To “truck along” more than one tile of values, simply perform a key-value sort of the keys paired with a temporary value array that enumerates the key indices. The reordered indices can then be used as a gather-vector for exchanging other associated tile data through shared memory.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 2 keys and values that are partitioned in a blocked arrangement across 2 threads where each thread owns 1 pair.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 3 keys and values each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 1, int>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][1] = // {{ {24.2, 1ll << 61} // thread 0 keys }, { {42.4, 1ll << 60} // thread 1 keys }}; int thread_values[2][1] = // {{1}, // thread 0 values {0}}; // thread 1 values constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000001110000011001100110011010 00100000000000...0000 // decompose(in[1]) = 01000010001010011001100110011010 00010000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> // Collectively sort the keys block_radix_sort_t(temp_storage) .Sort(thread_keys[threadIdx.x], thread_values[threadIdx.x], decomposer_t{}, begin_bit, end_bit); custom_t expected_keys[2][3] = // {{ {42.4, 1ll << 60}, // thread 0 expected keys }, { {24.2, 1ll << 61} // thread 1 expected keys }}; int expected_values[2][1] = // {{0}, // thread 0 values {1}}; // thread 1 values
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
values – [inout] Values to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> Sort( - KeyT (&keys)[ItemsPerThread],
- ValueT (&values)[ItemsPerThread],
- DecomposerT decomposer
Performs an ascending block-wide radix sort over a blocked arrangement of keys and values.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
BlockRadixSort can only accommodate one associated tile of values. To “truck along” more than one tile of values, simply perform a key-value sort of the keys paired with a temporary value array that enumerates the key indices. The reordered indices can then be used as a gather-vector for exchanging other associated tile data through shared memory.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 6 keys and values that are partitioned in a blocked arrangement across 2 threads where each thread owns 3 consecutive pairs.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 3 keys and values each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 3, int>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][3] = // {{ // thread 0 keys {+2.5, 4}, // {-2.5, 0}, // {+1.1, 3}, // }, { // thread 1 keys {+0.0, 1}, // {-0.0, 2}, // {+3.7, 5} // }}; int thread_values[2][3] = // {{4, 0, 3}, // thread 0 values {1, 2, 5}}; // thread 1 values // Collectively sort the keys block_radix_sort_t(temp_storage).Sort(thread_keys[threadIdx.x], thread_values[threadIdx.x], decomposer_t{}); custom_t expected_keys[2][3] = // {{ // thread 0 expected keys {-2.5, 0}, // {+0.0, 1}, // {-0.0, 2} // }, { // thread 1 expected keys {+1.1, 3}, // {+2.5, 4}, // {+3.7, 5} // }}; int expected_values[2][3] = // {{0, 1, 2}, // thread 0 expected values {3, 4, 5}}; // thread 1 expected values
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
values – [inout] Values to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- inline void SortDescending(
- KeyT (&keys)[ItemsPerThread],
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8
Performs a descending block-wide radix sort over a blocked arrangement of keys.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
The code snippet below illustrates a sort of 512 integer keys that are partitioned in a [<em>blocked arrangement</em>](../index.html#sec5sec3) across 128 threads where each thread owns 4 consecutive keys.
#include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh> __global__ void ExampleKernel(...) { // Specialize BlockRadixSort for a 1D block of 128 threads owning 4 integer keys each using BlockRadixSort = cub::BlockRadixSort<int, 128, 4>; // Allocate shared memory for BlockRadixSort __shared__ typename BlockRadixSort::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads int thread_keys[4]; ... // Collectively sort the keys BlockRadixSort(temp_storage).Sort(thread_keys);
Suppose the set of input
thread_keysacross the block of threads is{ [0,511,1,510], [2,509,3,508], [4,507,5,506], ..., [254,257,255,256] }. The corresponding outputthread_keysin those threads will be{ [511,510,509,508], [11,10,9,8], [7,6,5,4], ..., [3,2,1,0] }.- Parameters:
keys – [inout] Keys to sort
begin_bit – [in] [optional] The beginning (least-significant) bit index needed for key comparison
end_bit – [in] [optional] The past-the-end (most-significant) bit index needed for key comparison
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> SortDescending( - KeyT (&keys)[ItemsPerThread],
- DecomposerT decomposer,
- int begin_bit,
- int end_bit
Performs a descending block-wide radix sort over a blocked arrangement of keys.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 2 keys that are partitioned in a blocked arrangement across 2 threads where each thread owns 1 key.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 1 key each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 1>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][1] = // {{ {42.4, 1ll << 60} // thread 0 keys }, { {24.2, 1ll << 61} // thread 1 keys }}; constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000010001010011001100110011010 00010000000000...0000 // decompose(in[1]) = 01000001110000011001100110011010 00100000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> // Collectively sort the keys block_radix_sort_t(temp_storage).SortDescending(thread_keys[threadIdx.x], decomposer_t{}, begin_bit, end_bit); custom_t expected_output[2][3] = // {{ {24.2, 1ll << 61}, // thread 0 expected keys }, { {42.4, 1ll << 60} // thread 1 expected keys }};
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> SortDescending( - KeyT (&keys)[ItemsPerThread],
- DecomposerT decomposer
Performs a descending block-wide radix sort over a blocked arrangement of keys.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 6 keys that are partitioned in a blocked arrangement across 2 threads where each thread owns 3 consecutive keys.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 3 keys each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 3>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][3] = // {{ // thread 0 keys {+1.1, 2}, // {+2.5, 1}, // {-0.0, 4}, // }, { // thread 1 keys {+0.0, 3}, // {-2.5, 5}, // {+3.7, 0} // }}; // Collectively sort the keys block_radix_sort_t(temp_storage).SortDescending(thread_keys[threadIdx.x], decomposer_t{}); custom_t expected_output[2][3] = // {{ // thread 0 expected keys {+3.7, 0}, // {+2.5, 1}, // {+1.1, 2}, // }, { // thread 1 expected keys {-0.0, 4}, // {+0.0, 3}, // {-2.5, 5} // }};
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- inline void SortDescending(
- KeyT (&keys)[ItemsPerThread],
- ValueT (&values)[ItemsPerThread],
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8
Performs a descending block-wide radix sort across a blocked arrangement of keys and values.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
BlockRadixSort can only accommodate one associated tile of values. To “truck along” more than one tile of values, simply perform a key-value sort of the keys paired with a temporary value array that enumerates the key indices. The reordered indices can then be used as a gather-vector for exchanging other associated tile data through shared memory.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
The code snippet below illustrates a sort of 512 integer keys and values that are partitioned in a blocked arrangement across 128 threads where each thread owns 4 consecutive pairs.
#include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh> __global__ void ExampleKernel(...) { // Specialize BlockRadixSort for a 1D block of 128 threads owning 4 integer keys and values each using BlockRadixSort = cub::BlockRadixSort<int, 128, 4, int>; // Allocate shared memory for BlockRadixSort __shared__ typename BlockRadixSort::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads int thread_keys[4]; int thread_values[4]; ... // Collectively sort the keys and values among block threads BlockRadixSort(temp_storage).Sort(thread_keys, thread_values);
Suppose the set of input
thread_keysacross the block of threads is{ [0,511,1,510], [2,509,3,508], [4,507,5,506], ..., [254,257,255,256] }. The corresponding outputthread_keysin those threads will be{ [511,510,509,508], [11,10,9,8], [7,6,5,4], ..., [3,2,1,0] }.- Parameters:
keys – [inout] Keys to sort
values – [inout] Values to sort
begin_bit – [in] [optional] The beginning (least-significant) bit index needed for key comparison
end_bit – [in] [optional] The past-the-end (most-significant) bit index needed for key comparison
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> SortDescending( - KeyT (&keys)[ItemsPerThread],
- ValueT (&values)[ItemsPerThread],
- DecomposerT decomposer,
- int begin_bit,
- int end_bit
Performs a descending block-wide radix sort over a blocked arrangement of keys and values.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
BlockRadixSort can only accommodate one associated tile of values. To “truck along” more than one tile of values, simply perform a key-value sort of the keys paired with a temporary value array that enumerates the key indices. The reordered indices can then be used as a gather-vector for exchanging other associated tile data through shared memory.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 2 pairs that are partitioned in a blocked arrangement across 2 threads where each thread owns 1 pair.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 3 keys and values each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 1, int>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][1] = // {{ {42.4, 1ll << 60} // thread 0 keys }, { {24.2, 1ll << 61} // thread 1 keys }}; int thread_values[2][1] = // {{1}, // thread 0 values {0}}; // thread 1 values constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000010001010011001100110011010 00010000000000...0000 // decompose(in[1]) = 01000001110000011001100110011010 00100000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> // Collectively sort the keys block_radix_sort_t(temp_storage) .SortDescending(thread_keys[threadIdx.x], thread_values[threadIdx.x], decomposer_t{}, begin_bit, end_bit); custom_t expected_output[2][3] = // {{ {24.2, 1ll << 61}, // thread 0 expected keys }, { {42.4, 1ll << 60} // thread 1 expected keys }}; int expected_values[2][1] = // {{0}, // thread 0 expected values {1}}; // thread 1 expected values
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
values – [inout] Values to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> SortDescending( - KeyT (&keys)[ItemsPerThread],
- ValueT (&values)[ItemsPerThread],
- DecomposerT decomposer
Performs a descending block-wide radix sort over a blocked arrangement of keys and values.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
BlockRadixSort can only accommodate one associated tile of values. To “truck along” more than one tile of values, simply perform a key-value sort of the keys paired with a temporary value array that enumerates the key indices. The reordered indices can then be used as a gather-vector for exchanging other associated tile data through shared memory.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 6 keys and values that are partitioned in a blocked arrangement across 2 threads where each thread owns 3 consecutive pairs.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 3 keys and values each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 3, int>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][3] = // {{ // thread 0 keys {+1.1, 2}, // {+2.5, 1}, // {-0.0, 4}, // }, { // thread 1 keys {+0.0, 3}, // {-2.5, 5}, // {+3.7, 0} // }}; int thread_values[2][3] = // {{2, 1, 4}, // thread 0 values {3, 5, 0}}; // thread 1 values // Collectively sort the keys block_radix_sort_t(temp_storage).SortDescending(thread_keys[threadIdx.x], thread_values[threadIdx.x], decomposer_t{}); custom_t expected_keys[2][3] = // {{ // thread 0 expected keys {+3.7, 0}, // {+2.5, 1}, // {+1.1, 2}, // }, { // thread 1 expected keys {-0.0, 4}, // {+0.0, 3}, // {-2.5, 5} // }}; int expected_values[2][3] = // {{0, 1, 2}, // thread 0 expected values {4, 3, 5}}; // thread 1 expected values
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
values – [inout] Values to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
Sorting (blocked arrangement -> striped arrangement)
- inline void SortBlockedToStriped(
- KeyT (&keys)[ItemsPerThread],
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8
Performs an ascending radix sort across a blocked arrangement of keys, leaving them in a striped arrangement.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
The code snippet below illustrates a sort of 512 integer keys that are initially partitioned in a blocked arrangement across 128 threads where each thread owns 4 consecutive keys. The final partitioning is striped.
#include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh> __global__ void ExampleKernel(...) { // Specialize BlockRadixSort for a 1D block of 128 threads owning 4 integer keys each using BlockRadixSort = cub::BlockRadixSort<int, 128, 4>; // Allocate shared memory for BlockRadixSort __shared__ typename BlockRadixSort::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads int thread_keys[4]; ... // Collectively sort the keys BlockRadixSort(temp_storage).SortBlockedToStriped(thread_keys);
Suppose the set of input
thread_keysacross the block of threads is{ [0,511,1,510], [2,509,3,508], [4,507,5,506], ..., [254,257,255,256] }. The corresponding outputthread_keysin those threads will be{ [0,128,256,384], [1,129,257,385], [2,130,258,386], ..., [127,255,383,511] }.- Parameters:
keys – [inout] Keys to sort
begin_bit – [in] [optional] The beginning (least-significant) bit index needed for key comparison
end_bit – [in] [optional] The past-the-end (most-significant) bit index needed for key comparison
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> SortBlockedToStriped( - KeyT (&keys)[ItemsPerThread],
- DecomposerT decomposer,
- int begin_bit,
- int end_bit
Performs an ascending block-wide radix sort over a blocked arrangement of keys, leaving them in a striped arrangement.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 4 keys that are partitioned in a blocked arrangement across 2 threads where each thread owns 2 consecutive keys. The final partitioning is striped.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 2 keys each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 2>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][2] = // {{// thread 0 keys {24.2, 1ll << 62}, {42.4, 1ll << 61}}, {// thread 1 keys {42.4, 1ll << 60}, {24.2, 1ll << 59}}}; constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000001110000011001100110011010 01000000000000...0000 // decompose(in[1]) = 01000010001010011001100110011010 00100000000000...0000 // decompose(in[2]) = 01000001110000011001100110011010 00010000000000...0000 // decompose(in[3]) = 01000010001010011001100110011010 00001000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0100xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // decompose(in[2]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // decompose(in[3]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0000xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> // Collectively sort the keys block_radix_sort_t(temp_storage).SortBlockedToStriped(thread_keys[threadIdx.x], decomposer_t{}, begin_bit, end_bit); custom_t expected_output[2][3] = // {{// thread 0 expected keys {24.2, 1ll << 59}, {42.4, 1ll << 61}}, {// thread 1 expected keys {42.4, 1ll << 60}, {24.2, 1ll << 62}}};
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> SortBlockedToStriped( - KeyT (&keys)[ItemsPerThread],
- DecomposerT decomposer
Performs an ascending block-wide radix sort over a blocked arrangement of keys, leaving them in a striped arrangement.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 6 keys that are partitioned in a blocked arrangement across 2 threads where each thread owns 3 consecutive keys. The final partitioning is striped.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 3 keys each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 3>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][3] = // {{ // thread 0 keys {+2.5, 4}, // {-2.5, 0}, // {+1.1, 3}, // }, { // thread 1 keys {+0.0, 1}, // {-0.0, 2}, // {+3.7, 5} // }}; // Collectively sort the keys block_radix_sort_t(temp_storage).SortBlockedToStriped(thread_keys[threadIdx.x], decomposer_t{}); custom_t expected_output[2][3] = // {{ // thread 0 expected keys {-2.5, 0}, // {-0.0, 2}, // {+2.5, 4} // }, { // thread 1 expected keys {+0.0, 1}, // {+1.1, 3}, // {+3.7, 5} // }};
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- inline void SortBlockedToStriped(
- KeyT (&keys)[ItemsPerThread],
- ValueT (&values)[ItemsPerThread],
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8
Performs an ascending radix sort across a blocked arrangement of keys and values, leaving them in a striped arrangement.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
BlockRadixSort can only accommodate one associated tile of values. To “truck along” more than one tile of values, simply perform a key-value sort of the keys paired with a temporary value array that enumerates the key indices. The reordered indices can then be used as a gather-vector for exchanging other associated tile data through shared memory.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
The code snippet below illustrates a sort of 512 integer keys and values that are initially partitioned in a [<em>blocked arrangement</em>](../index.html#sec5sec3) across 128 threads where each thread owns 4 consecutive pairs. The final partitioning is striped.
#include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh> __global__ void ExampleKernel(...) { // Specialize BlockRadixSort for a 1D block of 128 threads owning 4 integer keys and values each using BlockRadixSort = cub::BlockRadixSort<int, 128, 4, int>; // Allocate shared memory for BlockRadixSort __shared__ typename BlockRadixSort::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads int thread_keys[4]; int thread_values[4]; ... // Collectively sort the keys and values among block threads BlockRadixSort(temp_storage).SortBlockedToStriped(thread_keys, thread_values);
Suppose the set of input
thread_keysacross the block of threads is{ [0,511,1,510], [2,509,3,508], [4,507,5,506], ..., [254,257,255,256] }. The corresponding outputthread_keysin those threads will be{ [0,128,256,384], [1,129,257,385], [2,130,258,386], ..., [127,255,383,511] }.- Parameters:
keys – [inout] Keys to sort
values – [inout] Values to sort
begin_bit – [in] [optional] The beginning (least-significant) bit index needed for key comparison
end_bit – [in] [optional] The past-the-end (most-significant) bit index needed for key comparison
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> SortBlockedToStriped( - KeyT (&keys)[ItemsPerThread],
- ValueT (&values)[ItemsPerThread],
- DecomposerT decomposer,
- int begin_bit,
- int end_bit
Performs an ascending block-wide radix sort over a blocked arrangement of keys and values, leaving them in a striped arrangement.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 4 pairs that are partitioned in a blocked arrangement across 2 threads where each thread owns 2 consecutive pairs. The final partitioning is striped.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 2 keys and values each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 2, int>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][2] = // {{// thread 0 keys {24.2, 1ll << 62}, {42.4, 1ll << 61}}, {// thread 1 keys {42.4, 1ll << 60}, {24.2, 1ll << 59}}}; int thread_values[2][2] = // {{3, 2}, // thread 0 values {1, 0}}; // thread 1 values constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000001110000011001100110011010 01000000000000...0000 // decompose(in[1]) = 01000010001010011001100110011010 00100000000000...0000 // decompose(in[2]) = 01000001110000011001100110011010 00010000000000...0000 // decompose(in[3]) = 01000010001010011001100110011010 00001000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0100xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // decompose(in[2]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // decompose(in[3]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0000xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> // Collectively sort the keys block_radix_sort_t(temp_storage) .SortBlockedToStriped(thread_keys[threadIdx.x], thread_values[threadIdx.x], decomposer_t{}, begin_bit, end_bit); custom_t expected_output[2][3] = // {{// thread 0 expected keys {24.2, 1ll << 59}, {42.4, 1ll << 61}}, {// thread 1 expected keys {42.4, 1ll << 60}, {24.2, 1ll << 62}}}; int expected_values[2][2] = // {{0, 2}, // thread 0 values {1, 3}}; // thread 1 values
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
values – [inout] Values to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> SortBlockedToStriped( - KeyT (&keys)[ItemsPerThread],
- ValueT (&values)[ItemsPerThread],
- DecomposerT decomposer
Performs an ascending block-wide radix sort over a blocked arrangement of keys and values, leaving them in a striped arrangement.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 6 pairs that are partitioned in a blocked arrangement across 2 threads where each thread owns 3 consecutive pairs. The final partitioning is striped.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 3 keys and values each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 3, int>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][3] = // {{ // thread 0 keys {+2.5, 4}, // {-2.5, 0}, // {+1.1, 3}, // }, { // thread 1 keys {+0.0, 1}, // {-0.0, 2}, // {+3.7, 5} // }}; int thread_values[2][3] = // {{4, 0, 3}, // thread 0 values {1, 2, 5}}; // thread 1 values // Collectively sort the keys block_radix_sort_t(temp_storage) .SortBlockedToStriped(thread_keys[threadIdx.x], thread_values[threadIdx.x], decomposer_t{}); custom_t expected_output[2][3] = // {{ // thread 0 expected keys {-2.5, 0}, // {-0.0, 2}, // {+2.5, 4} // }, { // thread 1 expected keys {+0.0, 1}, // {+1.1, 3}, // {+3.7, 5} // }}; int expected_values[2][3] = // {{0, 2, 4}, // thread 0 values {1, 3, 5}}; // thread 1 values
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
values – [inout] Values to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- inline void SortDescendingBlockedToStriped(
- KeyT (&keys)[ItemsPerThread],
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8
Performs a descending radix sort across a blocked arrangement of keys, leaving them in a striped arrangement.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
The code snippet below illustrates a sort of 512 integer keys that are initially partitioned in a blocked arrangement across 128 threads where each thread owns 4 consecutive keys. The final partitioning is striped.
#include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh> __global__ void ExampleKernel(...) { // Specialize BlockRadixSort for a 1D block of 128 threads owning 4 integer keys each using BlockRadixSort = cub::BlockRadixSort<int, 128, 4>; // Allocate shared memory for BlockRadixSort __shared__ typename BlockRadixSort::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads int thread_keys[4]; ... // Collectively sort the keys BlockRadixSort(temp_storage).SortBlockedToStriped(thread_keys);
Suppose the set of input
thread_keysacross the block of threads is{ [0,511,1,510], [2,509,3,508], [4,507,5,506], ..., [254,257,255,256] }. The corresponding outputthread_keysin those threads will be{ [511,383,255,127], [386,258,130,2], [385,257,128,1], ..., [384,256,128,0] }.- Parameters:
keys – [inout] Keys to sort
begin_bit – [in] [optional] The beginning (least-significant) bit index needed for key comparison
end_bit – [in] [optional] The past-the-end (most-significant) bit index needed for key comparison
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> SortDescendingBlockedToStriped( - KeyT (&keys)[ItemsPerThread],
- DecomposerT decomposer,
- int begin_bit,
- int end_bit
Performs a descending block-wide radix sort over a blocked arrangement of keys, leaving them in a striped arrangement.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 4 keys that are partitioned in a blocked arrangement across 2 threads where each thread owns 2 consecutive keys. The final partitioning is striped.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 2 keys each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 2>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][2] = // {{// thread 0 keys {24.2, 1ll << 62}, {42.4, 1ll << 61}}, {// thread 1 keys {42.4, 1ll << 60}, {24.2, 1ll << 59}}}; constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000001110000011001100110011010 01000000000000...0000 // decompose(in[1]) = 01000010001010011001100110011010 00100000000000...0000 // decompose(in[2]) = 01000001110000011001100110011010 00010000000000...0000 // decompose(in[3]) = 01000010001010011001100110011010 00001000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0100xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // decompose(in[2]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // decompose(in[3]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0000xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> // Collectively sort the keys block_radix_sort_t(temp_storage) .SortDescendingBlockedToStriped(thread_keys[threadIdx.x], decomposer_t{}, begin_bit, end_bit); custom_t expected_output[2][2] = // {{ // thread 0 expected keys {24.2, 1ll << 62}, // {42.4, 1ll << 60} // }, { // thread 1 expected keys {42.4, 1ll << 61}, // {24.2, 1ll << 59} // }};
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> SortDescendingBlockedToStriped( - KeyT (&keys)[ItemsPerThread],
- DecomposerT decomposer
Performs a descending block-wide radix sort over a blocked arrangement of keys, leaving them in a striped arrangement.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 6 keys that are partitioned in a blocked arrangement across 2 threads where each thread owns 3 consecutive keys. The final partitioning is striped.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 3 keys each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 3>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][3] = // {{ // thread 0 keys {+1.1, 2}, // {+2.5, 1}, // {-0.0, 4}, // }, { // thread 1 keys {+0.0, 3}, // {-2.5, 5}, // {+3.7, 0} // }}; // Collectively sort the keys block_radix_sort_t(temp_storage).SortDescendingBlockedToStriped(thread_keys[threadIdx.x], decomposer_t{}); custom_t expected_output[2][3] = // {{ // thread 0 expected keys {+3.7, 0}, // {+1.1, 2}, // {+0.0, 3} // }, { // thread 1 expected keys {+2.5, 1}, // {-0.0, 4}, // {-2.5, 5} // }};
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
- inline void SortDescendingBlockedToStriped(
- KeyT (&keys)[ItemsPerThread],
- ValueT (&values)[ItemsPerThread],
- int begin_bit = 0,
- int end_bit = sizeof(KeyT) * 8
Performs a descending radix sort across a blocked arrangement of keys and values, leaving them in a striped arrangement
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
BlockRadixSort can only accommodate one associated tile of values. To “truck along” more than one tile of values, simply perform a key-value sort of the keys paired with a temporary value array that enumerates the key indices. The reordered indices can then be used as a gather-vector for exchanging other associated tile data through shared memory.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
The code snippet below illustrates a sort of 512 integer keys and values that are initially partitioned in a blocked arrangement across 128 threads where each thread owns 4 consecutive pairs. The final partitioning is striped.
#include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh> __global__ void ExampleKernel(...) { // Specialize BlockRadixSort for a 1D block of 128 threads owning 4 integer keys and values each using BlockRadixSort = cub::BlockRadixSort<int, 128, 4, int>; // Allocate shared memory for BlockRadixSort __shared__ typename BlockRadixSort::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads int thread_keys[4]; int thread_values[4]; ... // Collectively sort the keys and values among block threads BlockRadixSort(temp_storage).SortBlockedToStriped(thread_keys, thread_values);
Suppose the set of input
thread_keysacross the block of threads is{ [0,511,1,510], [2,509,3,508], [4,507,5,506], ..., [254,257,255,256] }. The corresponding outputthread_keysin those threads will be{ [511,383,255,127], [386,258,130,2], [385,257,128,1], ..., [384,256,128,0] }.- Parameters:
keys – [inout] Keys to sort
values – [inout] Values to sort
begin_bit – [in] [optional] The beginning (least-significant) bit index needed for key comparison
end_bit – [in] [optional] The past-the-end (most-significant) bit index needed for key comparison
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> SortDescendingBlockedToStriped( - KeyT (&keys)[ItemsPerThread],
- ValueT (&values)[ItemsPerThread],
- DecomposerT decomposer,
- int begin_bit,
- int end_bit
Performs a descending block-wide radix sort over a blocked arrangement of keys and values, leaving them in a striped arrangement.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 4 keys and values that are partitioned in a blocked arrangement across 2 threads where each thread owns 2 consecutive pairs. The final partitioning is striped.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 2 keys and values each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 2, int>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][2] = // {{// thread 0 keys {24.2, 1ll << 62}, {42.4, 1ll << 61}}, {// thread 1 keys {42.4, 1ll << 60}, {24.2, 1ll << 59}}}; int thread_values[2][2] = // {{3, 2}, // thread 0 values {1, 0}}; // thread 1 values constexpr int begin_bit = sizeof(long long int) * 8 - 4; // 60 constexpr int end_bit = sizeof(long long int) * 8 + 4; // 68 // Decomposition orders the bits as follows: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = 01000001110000011001100110011010 01000000000000...0000 // decompose(in[1]) = 01000010001010011001100110011010 00100000000000...0000 // decompose(in[2]) = 01000001110000011001100110011010 00010000000000...0000 // decompose(in[3]) = 01000010001010011001100110011010 00001000000000...0000 // <----------- higher bits / lower bits -----------> // // The bit subrange [60, 68) specifies differentiating key bits: // // <------------- fp32 -----------> <------ int64 ------> // decompose(in[0]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0100xxxxxxxxxx...xxxx // decompose(in[1]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0010xxxxxxxxxx...xxxx // decompose(in[2]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0001xxxxxxxxxx...xxxx // decompose(in[3]) = xxxxxxxxxxxxxxxxxxxxxxxxxxxx1010 0000xxxxxxxxxx...xxxx // <----------- higher bits / lower bits -----------> // Collectively sort the keys block_radix_sort_t(temp_storage) .SortDescendingBlockedToStriped( thread_keys[threadIdx.x], thread_values[threadIdx.x], decomposer_t{}, begin_bit, end_bit); custom_t expected_output[2][2] = // {{ // thread 0 expected keys {24.2, 1ll << 62}, // {42.4, 1ll << 60} // }, { // thread 1 expected keys {42.4, 1ll << 61}, // {24.2, 1ll << 59} // }}; int expected_values[2][2] = // {{3, 1}, // thread 0 values {2, 0}}; // thread 1 values
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
values – [inout] Values to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.begin_bit – [in] The least-significant bit index (inclusive) needed for key comparison
end_bit – [in] The most-significant bit index (exclusive) needed for key comparison (e.g.,
(sizeof(float) + sizeof(long long int)) * 8)
-
template<class DecomposerT>
inline ::cuda::std::enable_if_t<!::cuda::std::is_convertible_v<DecomposerT, int>> SortDescendingBlockedToStriped( - KeyT (&keys)[ItemsPerThread],
- ValueT (&values)[ItemsPerThread],
- DecomposerT decomposer
Performs a descending block-wide radix sort over a blocked arrangement of keys and values, leaving them in a striped arrangement.
Added in version 2.2.0: First appears in CUDA Toolkit 12.3.
Efficiency is increased with increased granularity
ITEMS_PER_THREAD. Performance is also typically increased until the additional register pressure or shared memory allocation size causes SM occupancy to fall too low. Consider variants ofcub::BlockLoadfor efficiently gathering a blocked arrangement of elements across threads.A subsequent
__syncthreads()threadblock barrier should be invoked after calling this method if the collective’s temporary storage (e.g.,temp_storage) is to be reused or repurposed.
Snippet#
Let’s consider a user-defined
custom_ttype below. To sort an array ofcustom_tobjects, we have to tell CUB about relevant members of thecustom_ttype. We do this by providing a decomposer that returns a tuple of references to relevant members of the key.struct custom_t { float f; int unused; long long int lli; custom_t() = default; __device__ custom_t(float f, long long int lli) : f(f) , unused(42) , lli(lli) {} }; static __device__ bool operator==(const custom_t& lhs, const custom_t& rhs) { return lhs.f == rhs.f && lhs.lli == rhs.lli; } struct decomposer_t { __device__ cuda::std::tuple<float&, long long int&> // operator()(custom_t& key) const { return {key.f, key.lli}; } };
The code snippet below illustrates a sort of 6 keys and values that are partitioned in a blocked arrangement across 2 threads where each thread owns 3 consecutive pairs. The final partitioning is striped.
// Specialize `cub::BlockRadixSort` for a 1D block of 2 threads owning 3 keys and values each using block_radix_sort_t = cub::BlockRadixSort<custom_t, 2, 3, int>; // Allocate shared memory for `cub::BlockRadixSort` __shared__ block_radix_sort_t::TempStorage temp_storage; // Obtain a segment of consecutive items that are blocked across threads custom_t thread_keys[2][3] = // {{ // thread 0 keys {+1.1, 2}, // {+2.5, 1}, // {-0.0, 4}, // }, { // thread 1 keys {+0.0, 3}, // {-2.5, 5}, // {+3.7, 0} // }}; int thread_values[2][3] = // {{2, 1, 4}, // thread 0 values {3, 5, 0}}; // thread 1 values // Collectively sort the keys block_radix_sort_t(temp_storage) .SortDescendingBlockedToStriped(thread_keys[threadIdx.x], thread_values[threadIdx.x], decomposer_t{}); custom_t expected_output[2][3] = // {{ // thread 0 expected keys {+3.7, 0}, // {+1.1, 2}, // {+0.0, 3} // }, { // thread 1 expected keys {+2.5, 1}, // {-0.0, 4}, // {-2.5, 5} // }}; int expected_values[2][3] = // {{0, 2, 3}, // thread 0 values {1, 4, 5}}; // thread 1 values
- Template Parameters:
DecomposerT – [inferred] Type of a callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types:::cuda::std::tuple<ArithmeticTs&...> operator()(KeyT &key). The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.- Parameters:
keys – [inout] Keys to sort
values – [inout] Values to sort
decomposer – Callable object responsible for decomposing a
KeyTinto a tuple of references to its constituent arithmetic types. The leftmost element of the tuple is considered the most significant. The call operator must not modify members of the key.
-
struct TempStorage : public Uninitialized<_TempStorage>#
The operations exposed by BlockRadixSort require a temporary memory allocation of this nested type for thread communication. This opaque storage can be allocated directly using the
__shared__keyword. Alternatively, it can be aliased to externally allocated memory (shared or global) orunion’d with other storage allocation types to facilitate memory reuse.