Multi-GPU Workflows¶
There are many backends available with CUDA-Q which enable seamless switching between GPUs, QPUs and CPUs and also allow for workflows involving multiple architectures working in tandem.
Available Targets¶
`qpp-cpu`: The QPP based CPU backend which is multithreaded to maximize the usage of available cores on your system.
`nvidia`: GPU-accelerated state-vector based backend which accelerates quantum circuit simulation on NVIDIA GPUs powered by cuQuantum.
`nvidia-mgpu`: Allows for scaling circuit simulation on multiple GPUs.
`nvidia-mqpu`: Enables users to program workflows utilizing multiple virtual quantum processors in parallel, where each QPU is simulated by the
nvidiabackend.`remote-mqpu`: Enables users to program workflows utilizing multiple virtual quantum processors in parallel, where the backend used to simulate each QPU is configurable.
Please see CUDA-Q Backends for a full list of all available backends. Below we explore how to effectively utilize multiple CUDA-Q targets with the same GHZ state preparation code
import cudaq
@cudaq.kernel
def ghz_state(qubit_count: int):
qubits = cudaq.qvector(qubit_count)
h(qubits[0])
for i in range(1, qubit_count):
cx(qubits[0], qubits[i])
mz(qubits)
def sample_ghz_state(qubit_count, target):
"""A function that will sample a variable sized GHZ state."""
cudaq.set_target(target)
result = cudaq.sample(ghz_state, qubit_count, shots_count=1000)
return result
You can execute the code by running a statevector simulator on your CPU:
cpu_result = sample_ghz_state(qubit_count=2, target="qpp-cpu")
cpu_result.dump()
{ 00:475 11:525 }
You will notice a speedup of up to 2500x in executing the circuit below on NVIDIA GPUs vs CPUs:
if cudaq.num_available_gpus() > 0:
gpu_result = sample_ghz_state(qubit_count=25, target="nvidia")
gpu_result.dump()
{ 0000000000000000000000000:510 1111111111111111111111111:490 }
If one incrementally increases the qubit count, we reach a limit where the memory required is beyond the capabilities of a single GPU: A \(n\) qubit quantum state has \(2^n\) complex amplitudes, each of which require 8 bytes of memory to store. Hence the total memory required to store a \(n\) qubit quantum state is \(8\) bytes \(\times 2^n\). For \(n = 30\) qubits, this is roughly \(8\) GB but for \(n = 40\), this exponentially increases to 8700 GB.
Parallelization across Multiple Processors¶
The nvidia-mgpu target allows for memory from additional
GPUs to be pooled enabling qubit counts to be scaled.
Execution on the nvidia-mgpu backend is enabled via mpirun. Users
need to create a .py file with their code and run the command below
in terminal:
mpirun -np 4 python3 test.py
where 4 is the number of GPUs one has access to and test is the file
name chosen.
The nvidia-mqpu target uses a statevector simulator to simulate execution
on each virtual QPU.
The remote-mqpu platform allows to freely configure what backend is used
for each platform QPU.
For more information about the different platform targets, please take a look at
Multi-Processor Platforms.
Batching Hamiltonian Terms¶
Expectation value computations of multi-term Hamiltonians can be
asynchronously processed via the mqpu platform.
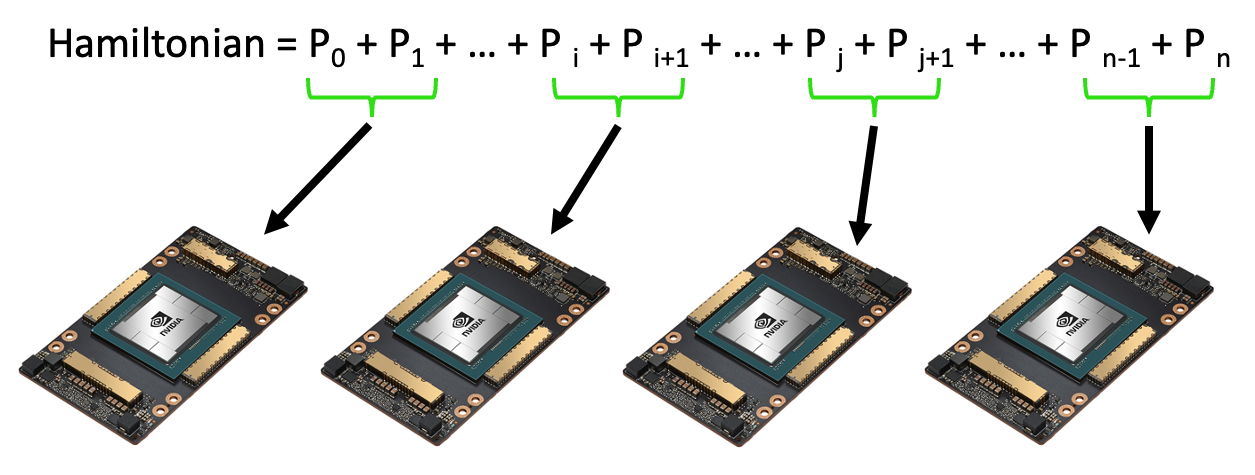
For workflows involving multiple GPUs, save the code below in a
filename.py file and execute via:
mpirun -np n python3 filename.py where n is an integer
specifying the number of GPUs you have access to.
import cudaq
from cudaq import spin
if cudaq.num_available_gpus() == 0:
print("This example requires a GPU to run. No GPU detected.")
exit(0)
cudaq.set_target("nvidia", option="mqpu")
cudaq.mpi.initialize()
qubit_count = 15
term_count = 100000
kernel = cudaq.make_kernel()
qubits = kernel.qalloc(qubit_count)
kernel.h(qubits[0])
for i in range(1, qubit_count):
kernel.cx(qubits[0], qubits[i])
# We create a random Hamiltonian
hamiltonian = cudaq.SpinOperator.random(qubit_count, term_count)
# The observe calls allows us to calculate the expectation value of the Hamiltonian with respect to a specified kernel.
# Single node, single GPU.
result = cudaq.observe(kernel, hamiltonian)
result.expectation()
# If we have multiple GPUs/ QPUs available, we can parallelize the workflow with the addition of an argument in the observe call.
# Single node, multi-GPU.
result = cudaq.observe(kernel, hamiltonian, execution=cudaq.parallel.thread)
result.expectation()
# Multi-node, multi-GPU.
result = cudaq.observe(kernel, hamiltonian, execution=cudaq.parallel.mpi)
result.expectation()
cudaq.mpi.finalize()
mpi is initialized? True
rank 0 num_ranks 1
Circuit Batching¶
Execution of parameterized circuits with different parameters can be
executed asynchronously via the mqpu platform.
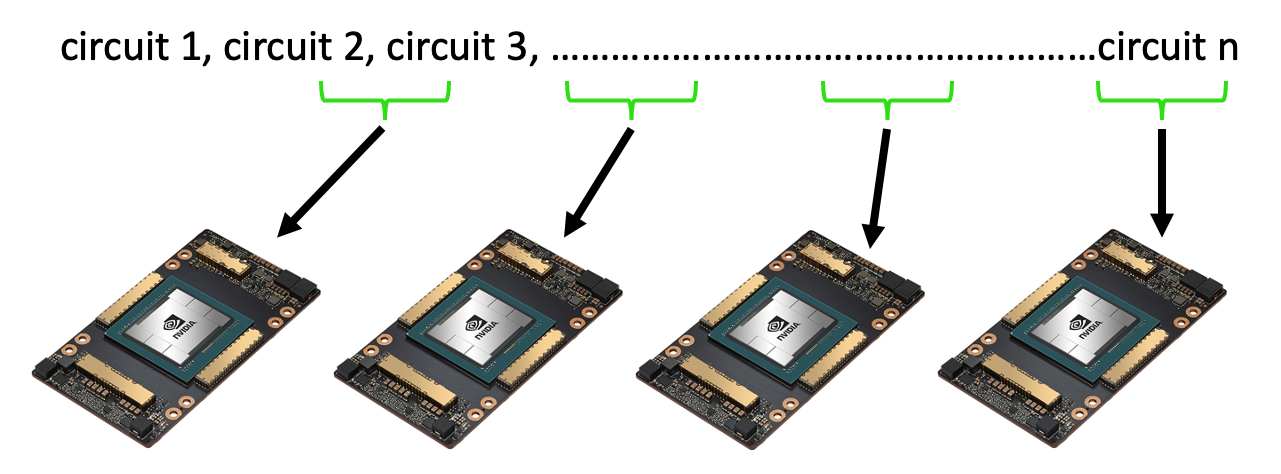
import cudaq
from cudaq import spin
import numpy as np
if cudaq.num_available_gpus() == 0:
print("This example requires a GPU to run. No GPU detected.")
exit(0)
np.random.seed(1)
cudaq.set_target("nvidia", option="mqpu")
qubit_count = 5
sample_count = 10000
h = spin.z(0)
parameter_count = qubit_count
# Below we run a circuit for 10000 different input parameters.
parameters = np.random.default_rng(13).uniform(low=0,
high=1,
size=(sample_count,
parameter_count))
kernel, params = cudaq.make_kernel(list)
qubits = kernel.qalloc(qubit_count)
qubits_list = list(range(qubit_count))
for i in range(qubit_count):
kernel.rx(params[i], qubits[i])
Let’s time the execution on single GPU.
import timeit
timeit.timeit(lambda: cudaq.observe(kernel, h, parameters),
number=1) # Single GPU result.
31.7 s ± 990 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Now let’s try to time multi GPU run.
print('We have', parameters.shape[0],
'parameters which we would like to execute')
xi = np.split(
parameters,
4) # We split our parameters into 4 arrays since we have 4 GPUs available.
print('We split this into', len(xi), 'batches of', xi[0].shape[0], ',',
xi[1].shape[0], ',', xi[2].shape[0], ',', xi[3].shape[0])
We have 10000 parameters which we would like to execute
We split this into 4 batches of 2500 , 2500 , 2500 , 2500
# Timing the execution on a single GPU vs 4 GPUs,
# one will see a 4x performance improvement if 4 GPUs are available.
asyncresults = []
num_gpus = cudaq.num_available_gpus()
for i in range(len(xi)):
for j in range(xi[i].shape[0]):
qpu_id = i * num_gpus // len(xi)
asyncresults.append(
cudaq.observe_async(kernel, h, xi[i][j, :], qpu_id=qpu_id))
result = [res.get() for res in asyncresults]
85.3 ms ± 2.36 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)