Audio and video ingestion
Use this page for speech and audio extraction with Parakeet ASR and for video workflows that combine audio with OCR on frames or derived images.
For air-gapped or disconnected deployments, refer to Air-gapped and disconnected deployment.
Sections: Speech and audio (Parakeet) · Run Parakeet on the cluster (Helm) · Parakeet with hosted inference (build.nvidia.com) · Video and frame OCR
Speech and audio extraction
This documentation describes two ways to run NeMo Retriever Library with the parakeet-1-1b-ctc-en-us ASR NIM microservice (nvcr.io/nim/nvidia/parakeet-1-1b-ctc-en-us) to extract speech from audio files:
- Run the NIM locally on your cluster with the NeMo Retriever Helm chart
- Use NVIDIA Cloud Functions (NVCF) endpoints for cloud-based inference
Supported file types for speech extraction today:
mp3,wavmp4,mov,mkv,avi— common video containers; the audio track is transcribed (same extensions as in What is NeMo Retriever Library?)
NeMo Retriever Library supports extracting speech from audio for Retrieval Augmented Generation (RAG). Similar to how the multimodal document pipeline uses detection and OCR microservices, NeMo Retriever Library uses the parakeet-1-1b-ctc-en-us ASR NIM to transcribe speech to text, then embeddings through the NeMo Retriever embedding path.
Before running audio extraction from Python with either self-hosted or hosted Parakeet, install the multimedia extra so the Parakeet ASR client can decode and resample audio:
pip install "nemo-retriever[multimedia]"
# For local GPU inference, include both extras:
pip install "nemo-retriever[local,multimedia]"
The Python package includes the ffmpeg-python wrapper, and the multimedia
extra adds Python libraries for audio decoding and resampling. These Python
dependencies do not install the ffmpeg or ffprobe command-line binaries.
For audio and video workflows, install system FFmpeg so both binaries are on
PATH:
sudo apt-get update && sudo apt-get install -y --no-install-recommends ffmpeg
Containers use the FFmpeg package from the base Ubuntu image, rather than a source-built FFmpeg release. If your workflow depends on exact FFmpeg version or codec behavior, verify the package inside the image against those requirements.
For Kubernetes deployments with network access to package repositories, set
service.installFfmpeg=true in the
Helm chart
to install ffmpeg/ffprobe at service startup. This runtime path requires
package-repository network egress, a writable root filesystem, and a security
policy that allows the image's scoped sudo use. For air-gapped clusters, refer to
Air-gapped and disconnected deployment.
Important
Due to limitations in available VRAM controls in the current release, the parakeet-1-1b-ctc-en-us ASR NIM must run on a dedicated additional GPU. For the full list of requirements, refer to the Pre-Requisites & Support Matrix.
This pipeline enables retrieval at the speech segment level when you enable segmenting (refer to the examples below).
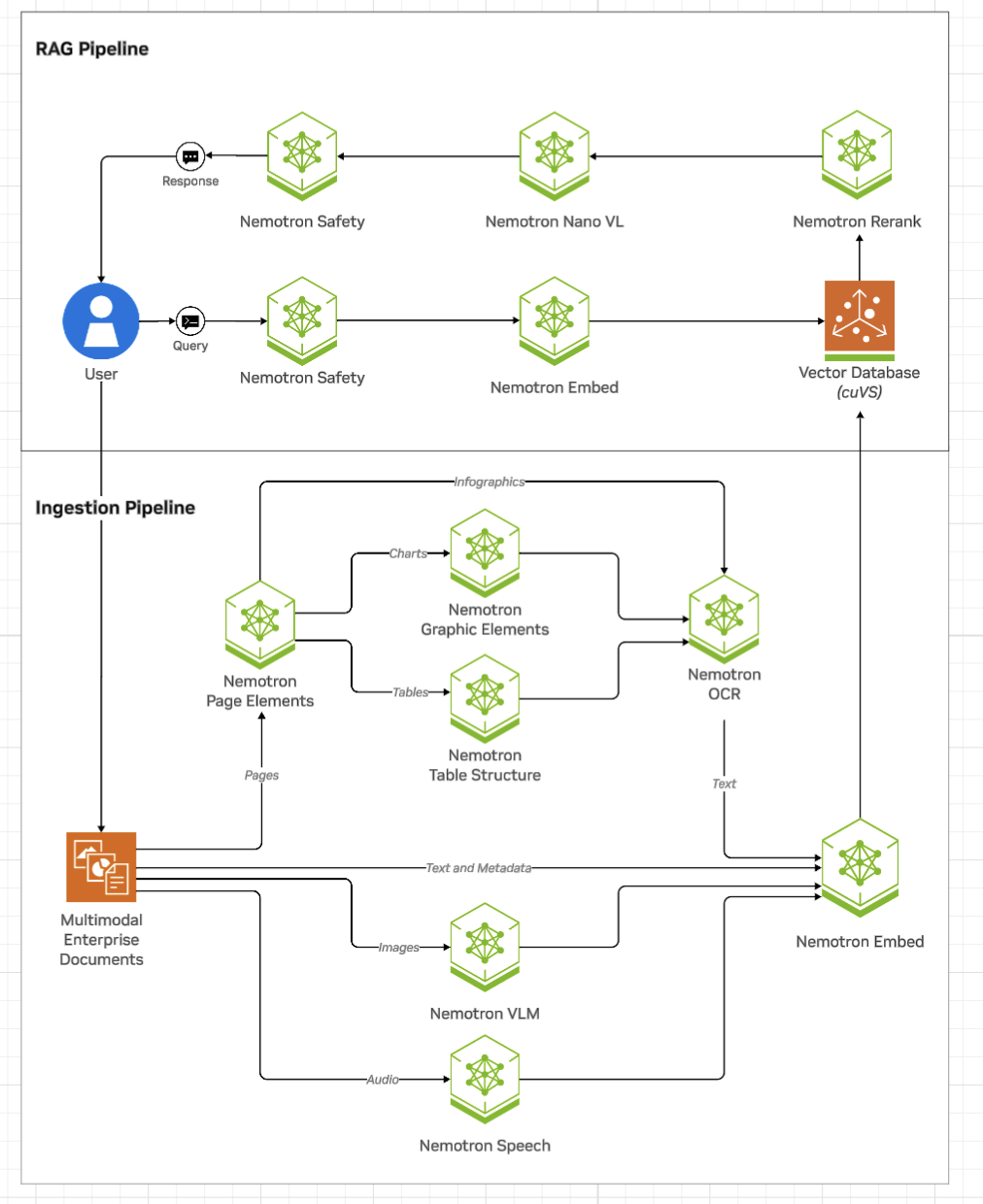
Run Parakeet on the cluster (Helm)
Use the following procedure to run the NIM on your own infrastructure. Self-hosted Parakeet runs on Kubernetes through the NeMo Retriever Helm chart. Enable the ASR NIM per Optional Helm NIMs. GPU pinning and endpoint wiring are documented in Parakeet ASR.
-
Deploy or upgrade with the NeMo Retriever Helm chart and enable Parakeet for your release (refer to Optional Helm NIMs). Follow Deployment options.
-
If the service will process audio or video files, set
service.installFfmpeg=truein the Helm chart when your cluster allows runtime package installation; for air-gapped clusters, refer to Air-gapped and disconnected deployment and the Helm chart README forservice.imageoverrides. -
After the services are running, interact with the pipeline from Python (refer to the Python API guide for parameter details).
- In
batchmode, pass the in-cluster Parakeet gRPC endpoint throughASRParams.audio_endpoints(for exampleaudio:50051from your Helm release). The retriever service auto-wires this endpoint; graph ingest does not.
from nemo_retriever import create_ingestor from nemo_retriever.common.params.models import ASRParams ingestor = ( create_ingestor(run_mode="batch") .files("./data/*.wav") .extract_audio( asr_params=ASRParams( audio_endpoints=("audio:50051", None), # (grpc_endpoint, http_endpoint) segment_audio=True, ), ) ) results = ingestor.ingest()To generate one extracted element for each sentence-like ASR segment, pass
asr_params=ASRParams(segment_audio=True)to.extract_audio(...). This option applies when audio extraction runs with a self-hosted Parakeet NIM or using build.nvidia.com hosted inference, but has no effect when using the local Hugging Face Parakeet model.For more runnable examples, refer to Workflow: Ingest documents.
- In
Parakeet with hosted inference (build.nvidia.com)
Instead of running the pipeline locally, you can call Parakeet through build.nvidia.com hosted inference.
-
On the Parakeet model page on build.nvidia.com, create or copy an API key and note the function ID for hosted access. You need both before making API calls.
-
Run inference from Python with the hosted gRPC endpoint and credentials from that page (the example below uses the default hosted gRPC hostname; confirm values in the Get API Key flow for your deployment). Pass hosted endpoint, function ID, and API key through
ASRParams(audio_endpoints,function_id,auth_token).For parameter details, refer to the Python API guide.
from nemo_retriever import create_ingestor from nemo_retriever.common.params.models import ASRParams ingestor = ( create_ingestor(run_mode="batch") .files("./data/*.mp3") .extract_audio( asr_params=ASRParams( audio_endpoints=("grpc.nvcf.nvidia.com:443", None), # (grpc_endpoint, http_endpoint) function_id="<function ID>", auth_token="<API key>", segment_audio=True, ), ) ) results = ingestor.ingest()Tip
For more runnable examples, refer to Workflow: Ingest documents.
Video and frame OCR
For video assets, NeMo Retriever Library can combine audio or speech processing (refer to Speech and audio extraction above) with visual text extraction when OCR applies to frames or derived images.
For OCR-oriented extract methods on scanned or image-heavy content, refer to OCR and scanned documents, text and layout extraction, and Nemotron Parse for advanced visual parsing.
Container formats and early-access video types are listed under supported file types and formats (refer to What is NeMo Retriever Library? for the full list).
For end-to-end RAG stacks that include multimodal ingestion, refer to the NVIDIA AI Blueprints catalog and related solution pages on NVIDIA Build.
Related topics
- Pre-Requisites & Support Matrix
- Troubleshoot NeMo Retriever extraction
- Use the Python API
- Chunking (includes audio and video segmenting defaults)