Wave2Letter+¶
Model¶
This is a fully convolutional model, based on Facebook’s Wave2Letter and Wave2LetterV2 papers. The model consists of 17 1D-Convolutional Layers and 2 Fully Connected Layers:
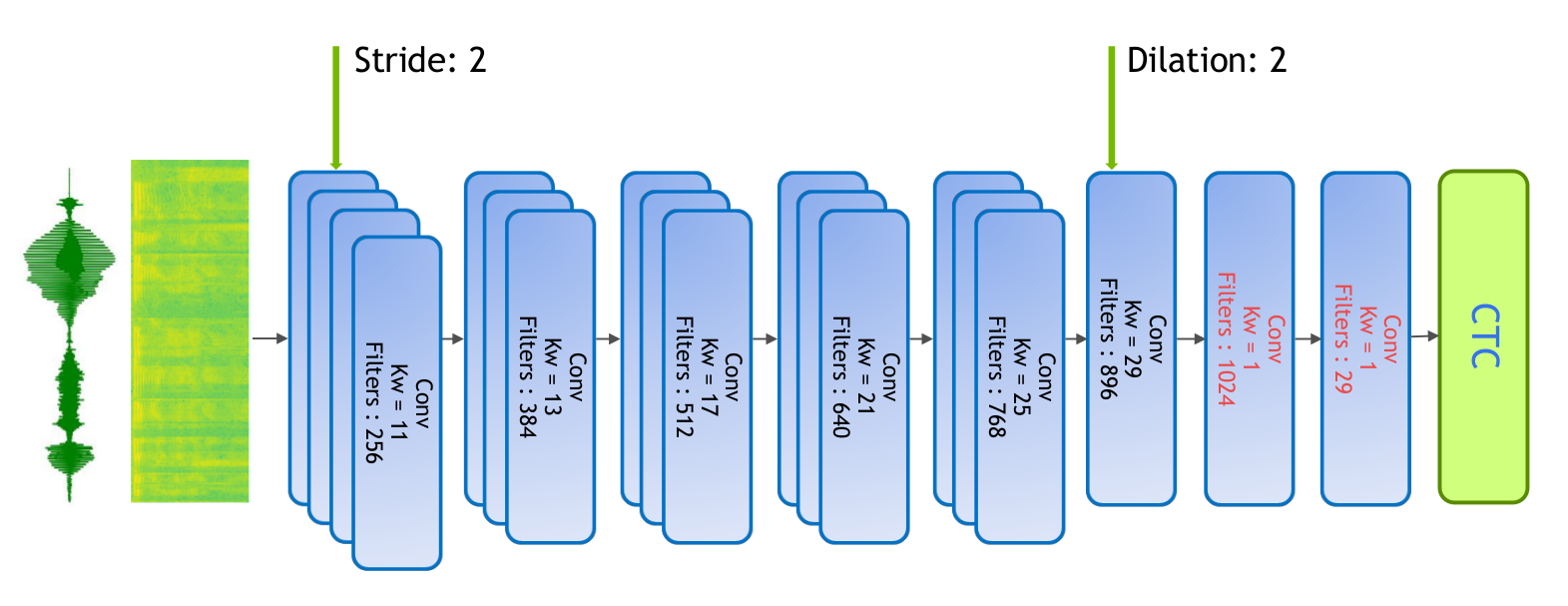
We preprocess the speech signal by sampling the raw audio waveform of the signal using a sliding window of 20ms with stride 10ms. We then extract log-mel filterbank energies of size 64 from these frames as input features to the model.
We use Connectionist Temporal Classification (CTC) loss to train the model. The output of the model is a sequence of letters corresponding to the speech input. The vocabulary consists of all alphabets (a-z), space, and the apostrophe symbol, a total of 29 symbols including the blank symbol used by the CTC loss.
We made the following changes to the original Wave2letter model:
- Clipped ReLU instead of Gated Linear Unit (GLU): ReLU allowed to almost half the number of model parameters, without decreasing the Word Error Rate (WER).
- Batch normalization(BN) instead of weight normalization (WN): we found that BN is more stable than WN, and the model is less sensitive to the weight intialziation.
- The CTC loss instead of the Auto SeGmentation (ASG).
- LARC instead of gradient clipping.
In addition to this, we use stride 2 in the first convolutional layer. This decreased the time (T) dimension of the sequence, which reduced the model footprint and improved the training time by ~1.6x. We have also observed a slight improvement after adding a dilation 2 for the last convolutional layer to increase the receptive-field of the model. Both striding and dilation improved the WER from 7.17% to 6.67%.
Training¶
We achieved a WER of 6.58 (the WER in the paper is 6.7) on the librispeech test-clean dataset using greedy decoding:
| LibriSpeech Dataset | WER %, Greedy Decoding | WER %, Beam Search: 2048 |
|---|---|---|
| dev-clean | 6.67% | 4.75% |
| test-clean | 6.58% | 4.94% |
| dev-other | 18.67% | 13.87% |
| test-other | 19.61% | 15.06% |
We used Open SLR language model while decoding with beam search using a beam width of 2048, alpha of 2.5, beta of 0.
The checkpoint for the model trained using the configuration w2l_plus_large_mp can be found at Checkpoint.
Our best model was trained for 200 epochs on 8 GPUs. We use:
- SGD with momentum = 0.9
- a learning rate with polynomial decay using an initial learning rate of 0.05
- Layer-wise Adative Rate Control (LARC) with eta = 0.001
- weight-decay = 0.001
- dropout (varible per layer: 0.2-0.4)
- batch size of 32 per GPU for float32 and 64 for mixed-precision.
Mixed Precision¶
To use mixed precision (float16) during training we made a few minor changes to the model. Tensorflow by default calls Keras Batch Normalization on 3D input (BxTxC) and cuDNN on 4D input (BxHxWxC). In order to use cuDNN’s BN we added an extra dimension to the 3D input to make it a 4D tensor (BxTx1xC).
The mixed precison model reached the same WER for the same number of steps as float32. The training time decreased by ~1.5x on 8-GPU DGX1 system, and by ~3x on 1-GPU and 4-GPUs when using Horovod.