WaveNet¶
Model¶
This is an implementation of the WaveNet model (see paper) and is intended to be used as a vocoder for Tacotron2, replacing Griffin-Lim.
The WaveNet vocoder is an autoregressive network that takes a raw audio signal as input and tries to predict the next value in the signal. The input is locally conditioned on mel spectrograms (see paper) that are generated by Tacotron2 and are upsampled to match the audio length by repeating each value a number of times equal to the scale factor.
The main feature of the network is dilated causal convolutions. By stacking layers with an increasing amount of dilation, we can easily increase the receptive field with relatively fewer layers, which allows the network to learn dense audio signals. The architecture of our implementation matches the one described in the paper, consisting of a single preprocessing causal convolution layer, several blocks of dilated causal convolution layers that use both skip and residual connections followed by postprocessing.
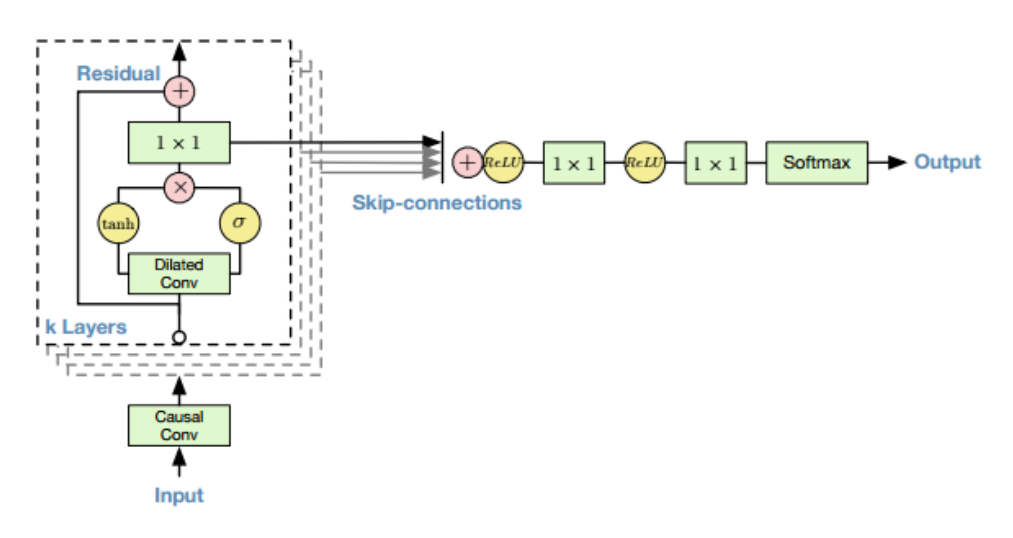
WaveNet architecture
Training¶
The model is trained on .wav audio files from the LJSpeech dataset. If the optional local_conditioning parameter is set to False, the model will train on only the raw audio signal, Otherwise, the data layer will extract spectrograms from the audio and use them to condition the inputs.
WaveNet is a highly memory intensive model, so only very small batch sizes are supported. Switching to mixed precision training will generally halve the memory requirements, allowing the batch size to be doubled.