:bangbang: :new: NVIDIA H200 has been announced & is optimized on TensorRT LLM. Learn more about H200, & H100 comparison, here: H200 achieves nearly 12,000 tokens/sec on Llama2-13B with TensorRT LLM
H100 has 4.6x A100 Performance in TensorRT LLM, achieving 10,000 tok/s at 100ms to first token#
TensorRT LLM evaluated on both Hopper and Ampere shows H100 FP8 is up to 4.6x max throughput and 4.4x faster 1st token latency than A100. H100 FP8 is able to achieve over 10,000 output tok/s at peak throughput for 64 concurrent requests, while maintaining a 1st token latency of 100ms. For min-latency applications, TRT-LLM H100 can achieve less than 10ms to 1st token latency.
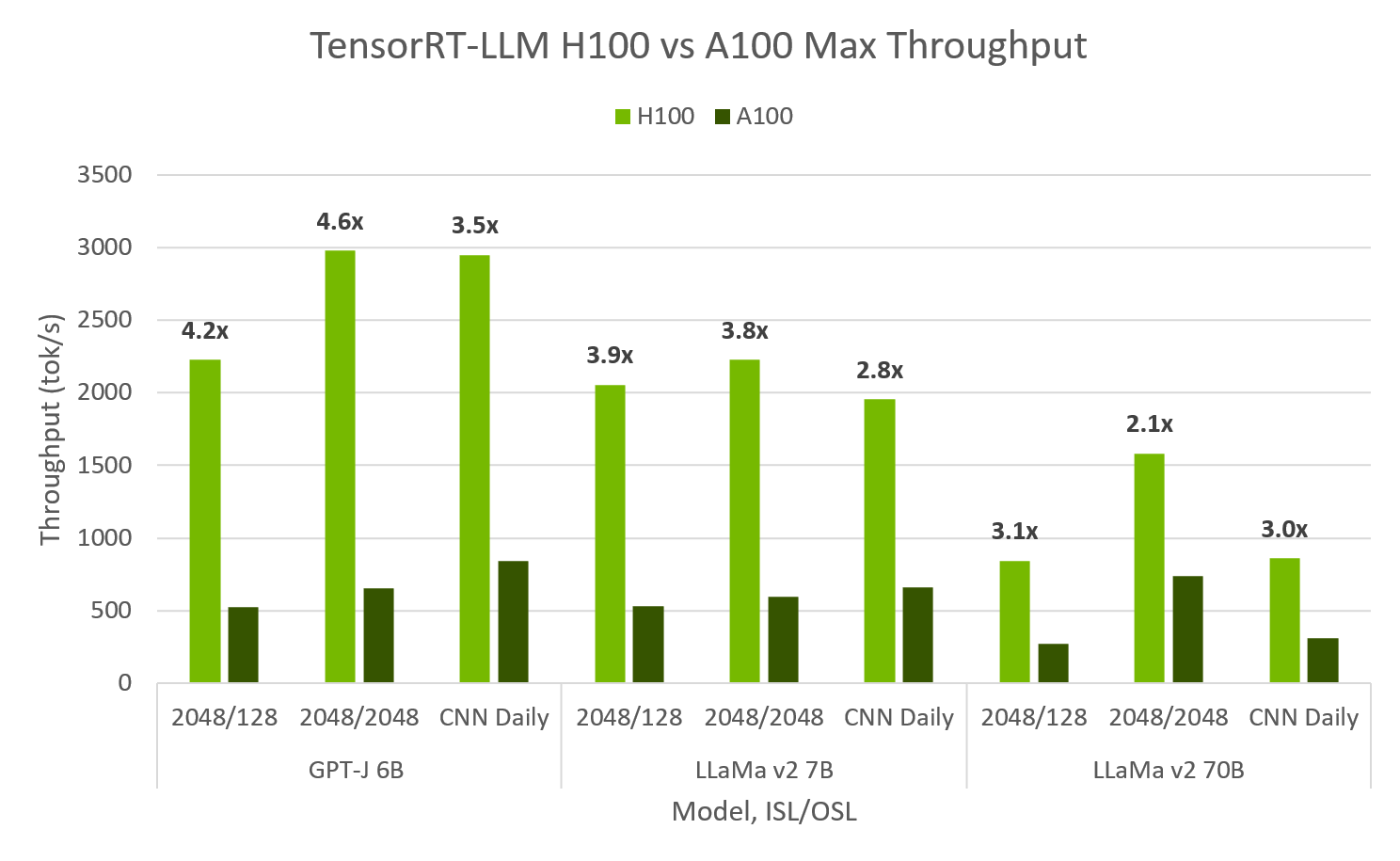
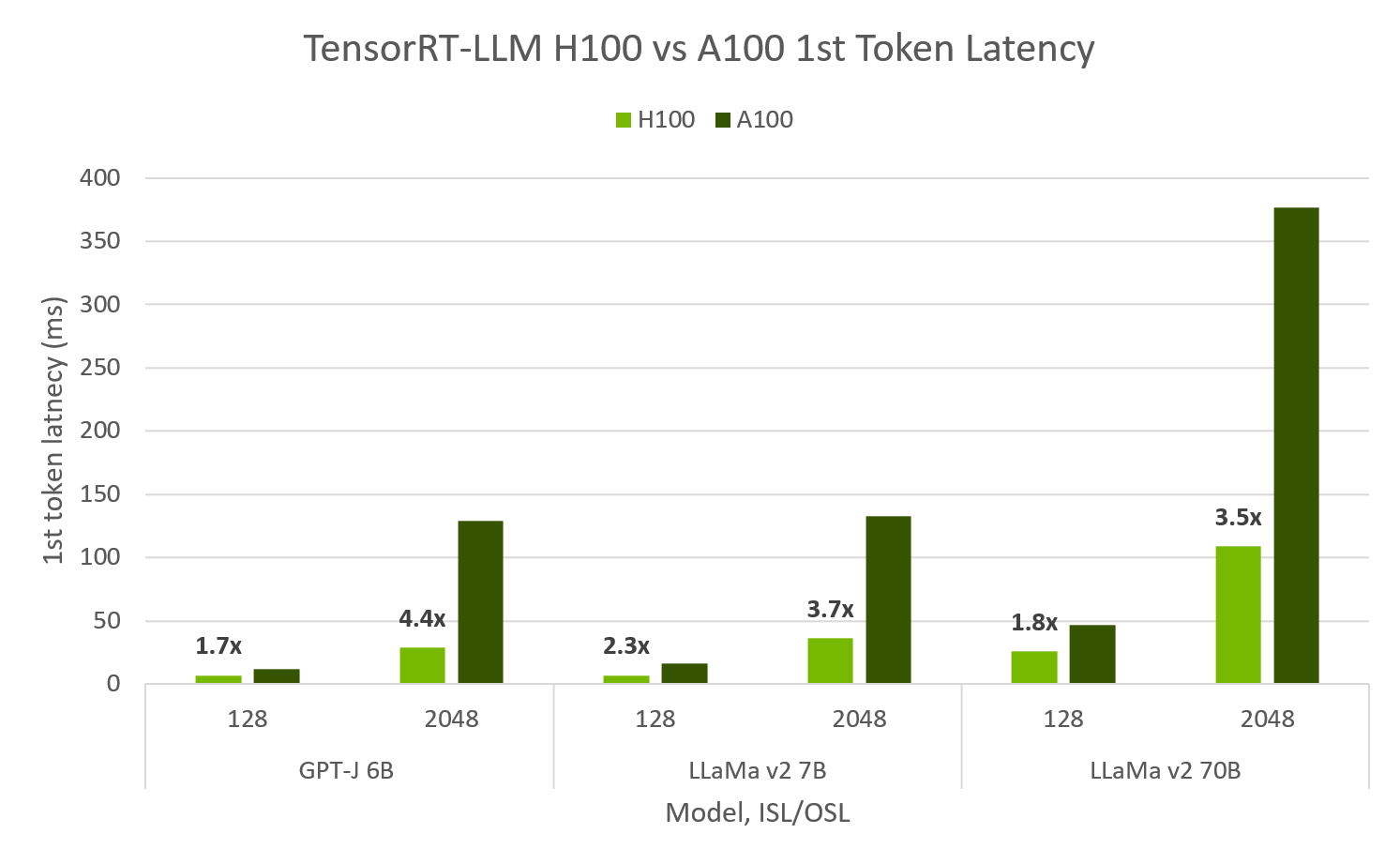
TensorRT LLM throughput & first token latency on H100 & A100. H100 FP8, A100 FP16, SXM 80GB GPUs, ISL/OSL’s provided, TP=1, BS=32/64 max throughput, BS=1 1st token latency. TensorRT LLM v0.5.0, TensorRT 9.1. Max throughput calculated by sweeping BS 1,2,…,64. Throughput taken at largest successful.
Max Throughput & Min Latency
Model |
Batch Size |
Input Length |
Output Length |
Throughput (out tok/s) |
1st Token Latency (ms) |
|---|---|---|---|---|---|
H100 |
|||||
GPT-J 6B |
64 |
128 |
128 |
10,907 |
102 |
GPT-J 6B |
1 |
128 |
- |
185 |
7.1 |
A100 |
|||||
GPT-J 6B |
64 |
128 |
128 |
3,679 |
481 |
GPT-J 6B |
1 |
128 |
- |
111 |
12.5 |
Speedup |
|||||
GPT-J 6B |
64 |
128 |
128 |
3.0x |
4.7x |
GPT-J 6B |
1 |
128 |
- |
2.4x |
1.7x |
FP8 H100, FP16 A100, SXM 80GB GPUs, TP1, ISL/OSL’s provided, TensorRT LLM v0.5.0., TensorRT 9.1
The full data behind these charts & tables and including larger models with higher TP values can be found in TensorRT LLM’s Performance Documentation
Stay tuned for a highlight on Llama coming soon!
MLPerf on H100 with FP8#
In the most recent MLPerf results, NVIDIA demonstrated up to 4.5x speedup in model inference performance on the NVIDIA H100 compared to previous results on the NVIDIA A100 Tensor Core GPU. Using the same data types, the H100 showed a 2x increase over the A100. Switching to FP8 resulted in yet another 2x increase in speed.
What is H100 FP8?#
H100 is NVIDIA’s next-generation, highest-performing data center GPU. Based on the NVIDIA Hopper GPU architecture, H100 accelerates AI training and inference, HPC, and data analytics applications in cloud data centers, servers, systems at the edge, and workstations. Providing native support for FP8 data types H100 can double performance and halve memory consumption, compared to 16-bit floating point options on H100.
FP8 specification introduced in the paper FP8 Formats for Deep Learning can be used to speed up training as well as inference with post-training-quantization of models trained using 16-bit formats. The specification consists of two encodings - E4M3 (4-bit exponent and 3-bit mantissa) and E5M2 (5-bit exponent and 2-bit mantissa). The recommended use of FP8 encodings is E4M3 for weight and activation tensors, and E5M2 for gradient tensors.
In practice, FP8 can improve perceived performance on H100 (FP8 vs FP16) by more than 2x. FP8 is a W8A8 format, meaning the weights are stored in 8bit, as are the activations, or compute. 8bit weights decrease GPU memory consumption & bandwidth meaning a larger model, sequence length, or batchsize can be fit into the same GPU. This can enable new use cases, and larger max batch size can increase max throughput beyond 2x of FP16 H100.