GEMM Speedups Across Precisions
Transformer Engine supports multiple low-precision formats for the linear-layer GEMMs that dominate transformer training time: BF16, FP8 tensor-wise scaling (CurrentScaling, DelayedScaling), FP8 Block Scaling, MXFP8, and NVFP4. Each step down in precision can accelerate the 12 GEMMs per transformer layer (4 Fprop + 4 Dgrad + 4 Wgrad), but the actual speedup depends on your model’s matrix dimensions.
A benchmark tool is provided at benchmarks/gemm/benchmark_gemm.py to measure GEMM performance for your specific model config. See the full tutorial for usage details.
The benchmark reports two numbers for each precision:
Autocast – the end-to-end speedup seen in real training. It includes both the GEMM and the per-step quantization work: converting the input tensors to the low-precision format and computing their scaling factors.
Pre-quantized – the raw GEMM kernel throughput with inputs already in the target format, excluding per-step quantization. Because the inputs are already quantized, recipes that differ only in how scaling factors are computed (e.g. DelayedScaling vs CurrentScaling) collapse to the same kernel here.
Example: 5B Model on B300 (Blackwell)
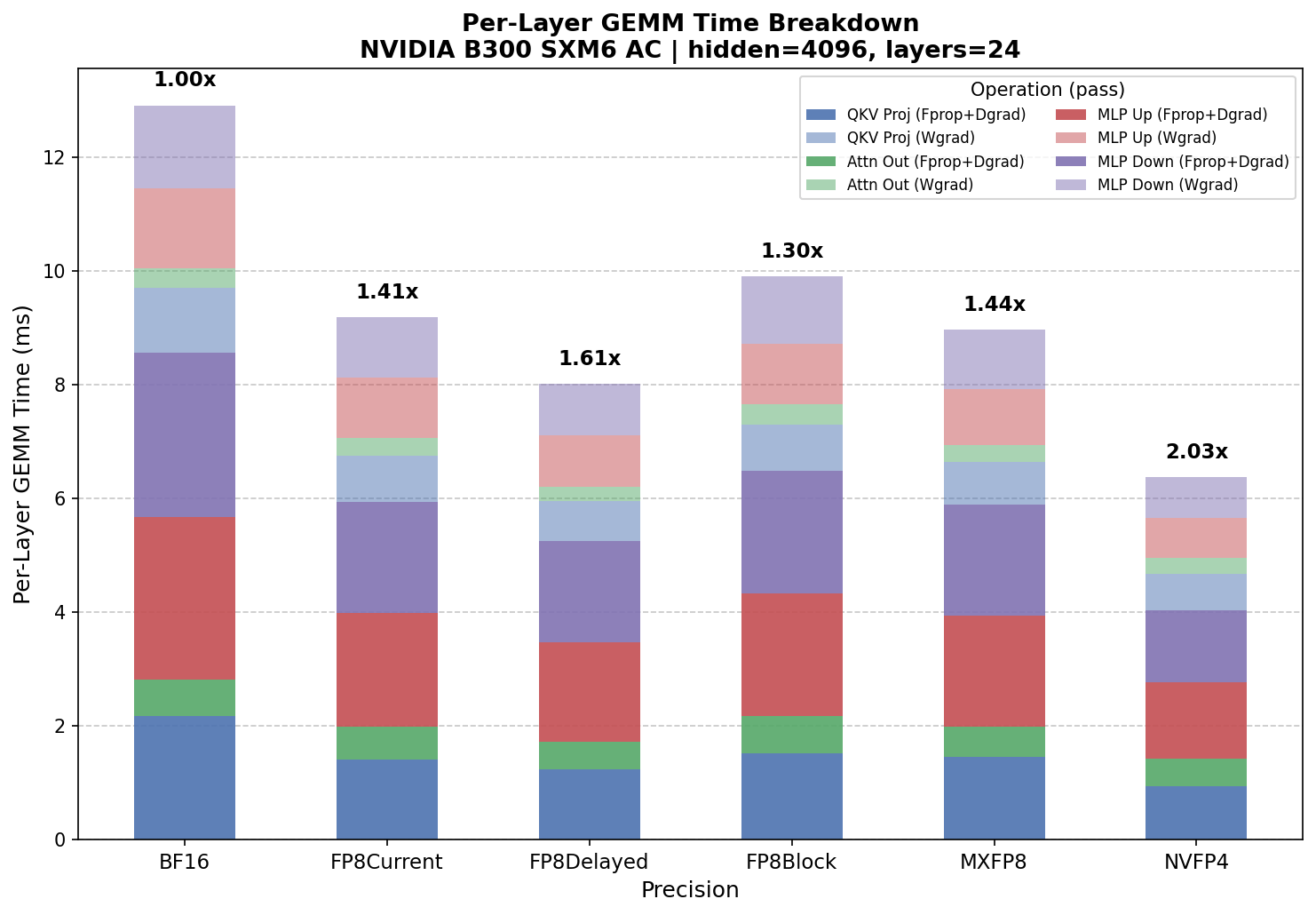
Autocast model config benchmark on NVIDIA B300 – per-layer GEMM time breakdown by precision and operation (Fprop+Dgrad and Wgrad).
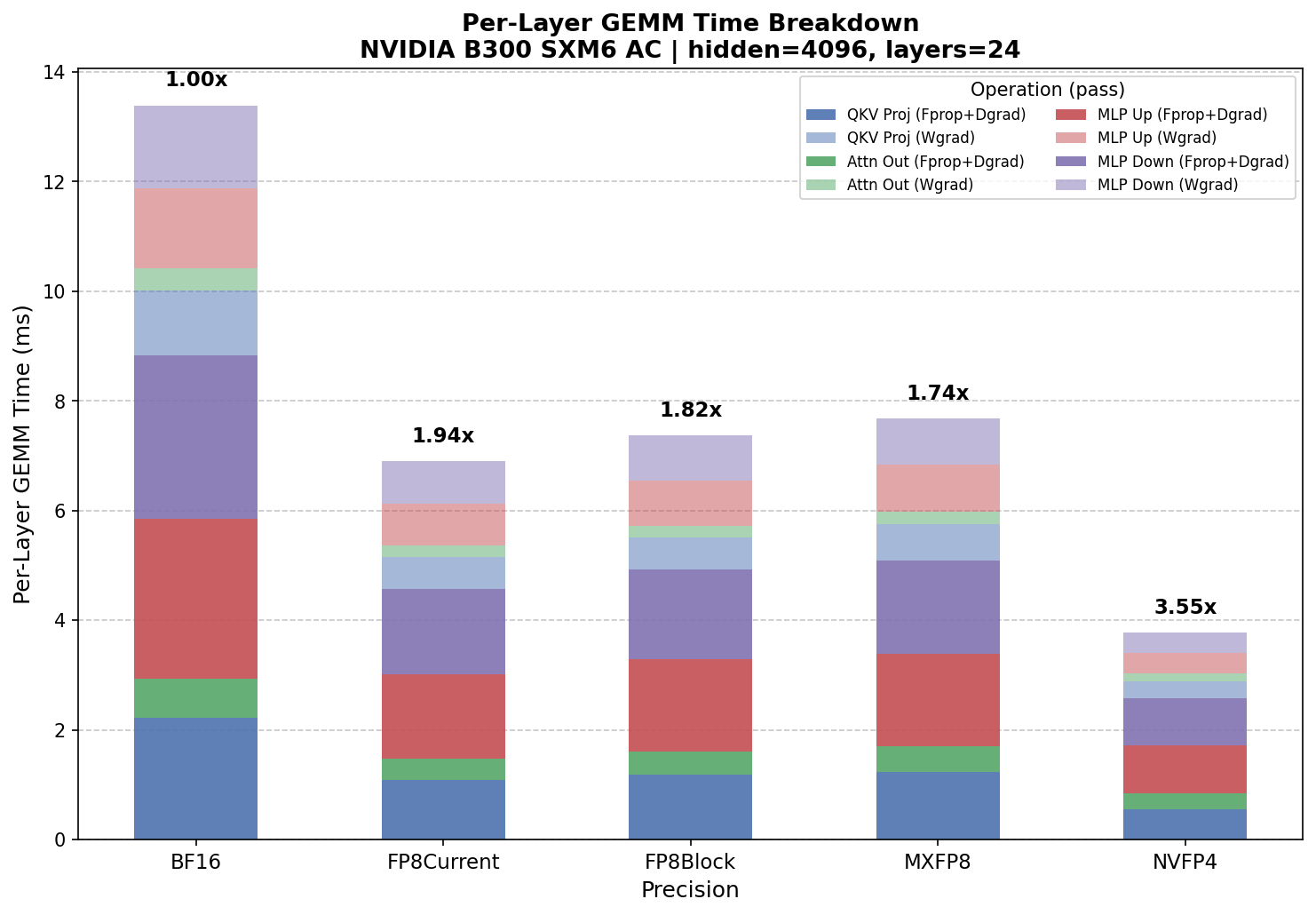
Pre-quantized model config benchmark on NVIDIA B300 – raw GEMM kernel throughput without quantization overhead.
For a 5B-parameter model (hidden=4096, intermediate=16384, 24 layers), MXFP8 delivers ~1.44x and NVFP4 delivers ~2.03x over BF16 in autocast mode. FP8 DelayedScaling reaches 1.61x, outperforming both FP8 CurrentScaling (1.41x) and MXFP8 on Blackwell.
In pre-quantized mode the gap widens: NVFP4 reaches 3.55x over BF16, nearly double its autocast speedup. The difference is the per-step quantization cost, which the pre-quantized number excludes.
Example: 5B Model on H200 (Hopper)
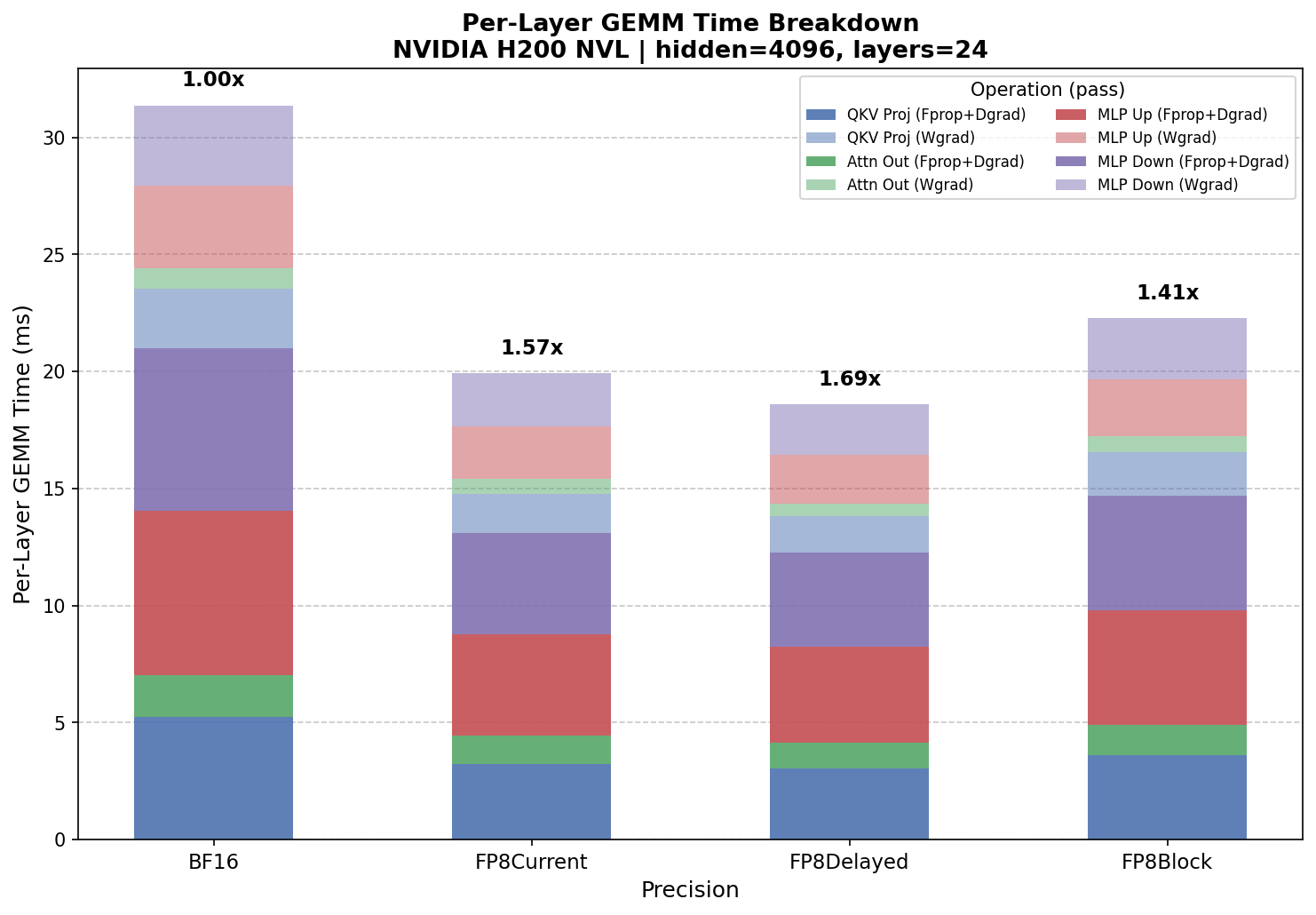
Autocast model config benchmark on NVIDIA H200 NVL – per-layer GEMM time breakdown by precision and operation (Fprop+Dgrad and Wgrad).
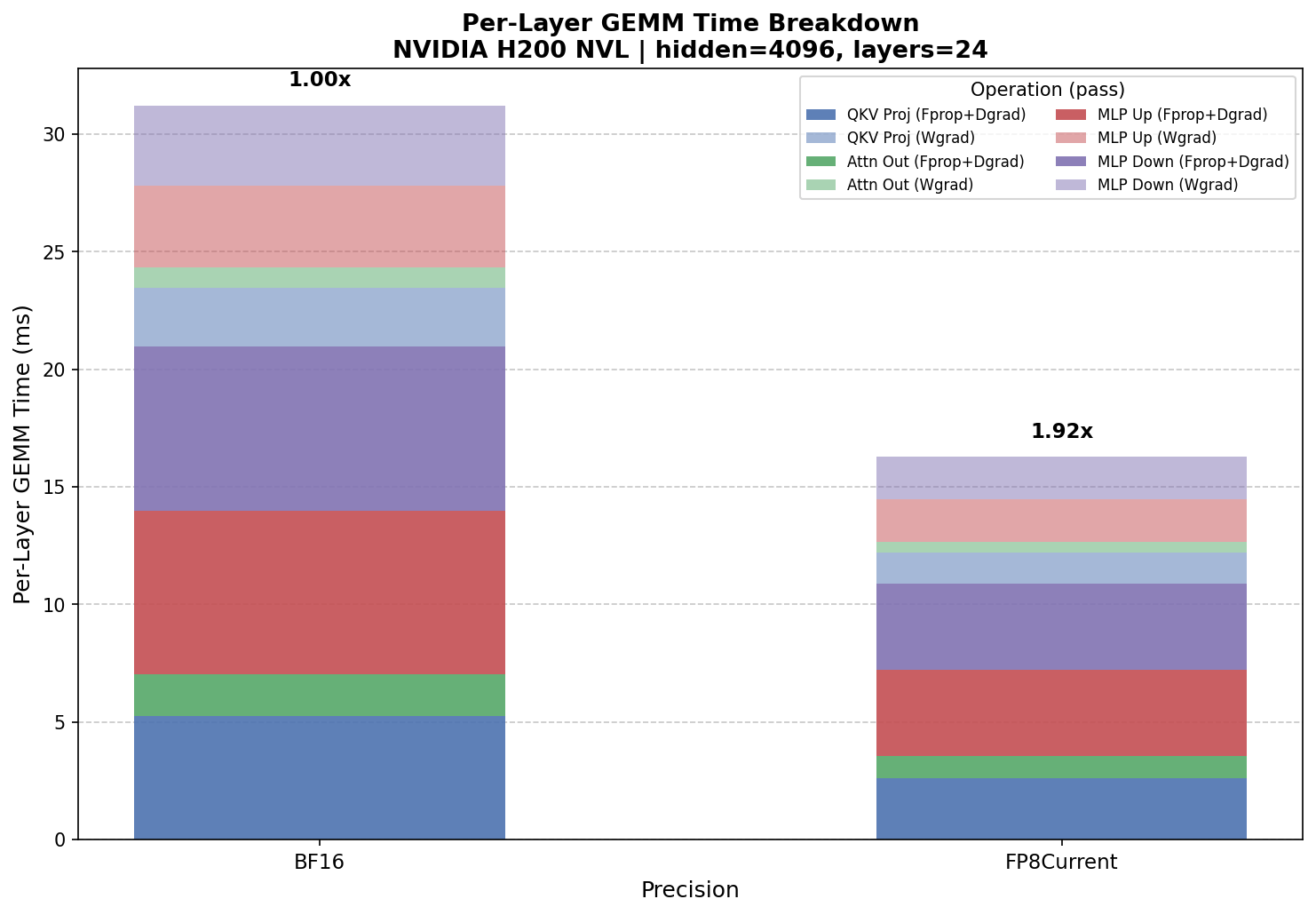
Pre-quantized model config benchmark on NVIDIA H200 NVL – raw GEMM kernel throughput without quantization overhead.
For the same 5B-parameter model on H200 (Hopper), the available precisions are BF16, FP8 CurrentScaling, FP8 DelayedScaling, and FP8 Block Scaling. FP8 DelayedScaling delivers ~1.69x over BF16, followed by FP8 CurrentScaling at ~1.57x and FP8 Block Scaling at ~1.41x. FP8 Block Scaling runs natively on Hopper and is the only block-scaled FP8 recipe available on this device. In pre-quantized mode, raw FP8 reaches 1.92x over BF16.
Speedup Is Shape-Dependent
The speedup from lower precision depends on the matrix dimensions set by your model
config. Large GEMMs – from big hidden and intermediate sizes and high token counts
(micro_batch_size * sequence_length) – amortize the fixed quantization overhead
over more compute and see meaningful speedups. Small GEMMs (e.g. the attention output
projection, with K=N=hidden_size and no expansion) may see little benefit or even a
slowdown when the overhead outweighs what the faster kernel saves.
This is why you should benchmark with your actual config: the theoretical tensor-core speedup (e.g. 2x for FP4 vs FP8) is an upper bound that assumes the GEMM is large enough to saturate the hardware. It also makes the tool useful for architecture co-design – run candidate configs through it before committing to a training run.
See the full tutorial for detailed analysis on both Blackwell and Hopper, including per-operation (Fprop, Dgrad, Wgrad) breakdowns and manual shape mode for non-standard architectures.