Optimizing DeepSeek R1 Throughput on NVIDIA Blackwell GPUs: A Deep Dive for Developers#
By NVIDIA TensorRT LLM team
Table of Contents#
Introduction#
The open source DeepSeek R1 model’s innovative architecture including the multi-head latent attention (MLA) and large sparse Mixture-of-Experts (MoE) significantly improved the inference efficiency of the LLM models. However, harnessing the full potential of such an innovative structure requires equally important hardware/software co-optimization. This post delves into the optimization strategies for DeepSeek R1 throughput oriented scenarios (TPS/GPU), developed by NVIDIA within TensorRT LLM on NVIDIA’s Blackwell B200 GPUs. We will explore the rationale behind each enhancement. The other min-latency optimization blog explained in detail how TensorRT LLM optimizes the R1 performance to achieve the best of the TPS/USER.
These optimizations have significantly boosted DeepSeek R1 throughput on Blackwell. Performance increased from approximately 2000 TPS/GPU in February to 4600 TPS/GPU on ISL/OSL 1K/2K dataset. The optimizations are general and applicable to other ISL/OSL configs too. These optimization items were broadly categorized into three areas: MLA layers, MoE layers, and runtime.
Precision strategy#
The mixed precision recipe for DeepSeek R1 throughput scenario is almost the same as what is used for latency oriented scenario, with the following differences:
FP8 KV cache and FP8 attention, rather than BF16 precision.
FP4 Allgather for better communication bandwidth utilization.
The checkpoint used in this blog is hosted in nvidia/DeepSeek-R1-FP4, generated by NVIDIA Model Optimizer. The accuracy score of common dataset on this FP4 checkpoint and TensorRT LLM implementations are:
Precision |
GPQA Diamond |
MATH-500 |
|---|---|---|
TensorRT LLM FP8 |
0.697 |
0.954 |
TensorRT LLM FP4 |
0.705 |
0.96 |
** Note there are some run-to-run variance for these evaluations, so FP4 data is slight higher here. We think FP4 has comparable accuracy with FP8 on these datasets.
The MoE layers inside this checkpoint have been quantized into FP4. Quantizing the MoE layer weights into FP4 has the following benefits:
Fully utilize the 5th generation Tensor Core FLOPS of the NVIDIA Blackwell GPUs
Reduce the memory load needs of the weights by almost half for MoE. Since the MoE parts are still memory bound for the decoding phase for the scenario, and 97% of the weights in the DeepSeek R1 model are from MoE layers.
Reduce the memory footprint of the model weights, thus freeing more GPU memories for KV cache and then increasing the max concurrency. The original FP8 model checkpoint of the DeepSeek R1 model is about 640GB, while the NVIDIA provided DeepSeek R1 FP4 quantized model is only about 400 GB.
The precision of FP8 KV cache and FP8 attention kernels are evaluated on the GSM8K dataset, with no obvious accuracy drops. For the accuracy numbers, please see the table in the FP8 KV cache section. Users can still opt-out to use BF16 KV cache and attention if on their dataset some accuracy differences are observed.
Parallel strategy#
The parallelism strategy for DeepSeek R1 throughput scenario is different from what is used for latency-oriented scenarios.
Components |
Parallel Patterns |
|---|---|
Attention Modules |
Data Parallelism 8 (DP8) |
MoE Sparse Experts |
Expert Parallelism 8 (EP8) |
MoE Shared Experts |
DP8 |
Fuse_A GEMM |
DP8 |
Router GEMM |
DP8 |
In the following sections we will explain the rationale why DP and EP are chosen and not using tensor parallel (TP).
Weights absorb and MQA#
The core idea of MLA is the low-rank joint compression for the attention keys and values to reduce KV-cache size during the inference. Based on the MLA formulas, the down-projected KV latent is up-projected to multiple heads and combined with the up-projected Q to establish a normal multi-head attention (MHA). Due to the nature of the matrix multiplication, the up projection weights matrix of the K (W^UK) can be multiplied by the up-projection weights matrix of Q (W^Q) firstly, the computed results of these 2 can be then multiplied to Q. The up-projection weights matrix of V (W^UV) and the attention output projection matrix W^O can also be multiplied after the attention output. The DeepSeek-V2 technical report calls this technique “absorb”. After the weights are absorbed, the MLA is equivalent to multiple query attention(MQA). Please see the original DeepSeek-V2 technical paper for the detailed formulas and explanations, the following block diagram shows the computational flow of weights absorbed MLA in TensorRT LLM.
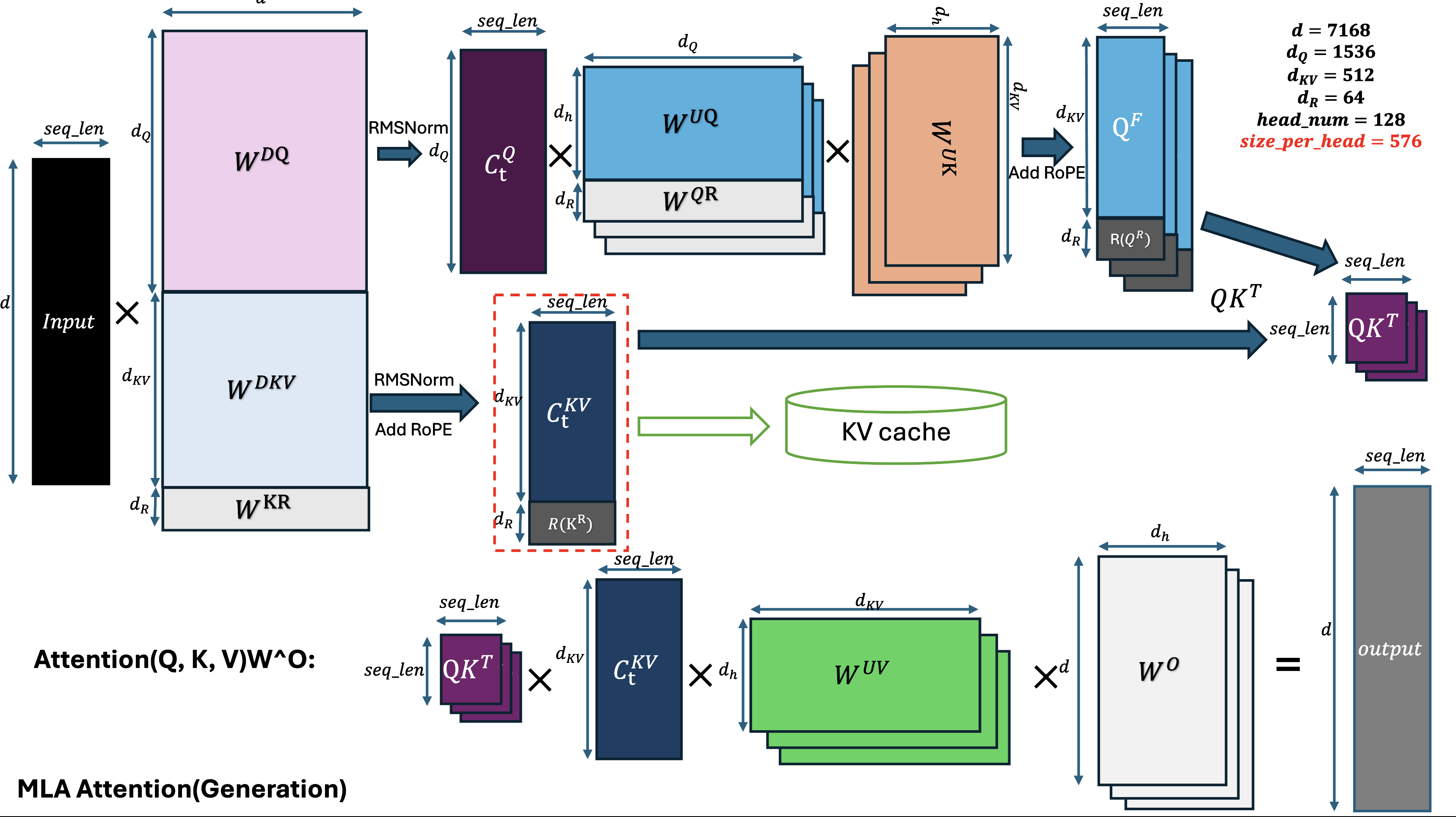
For the decoding phase, the weights absorb significantly reduces the math FLOPS needed to up project the K and V, since the FLOPs needed for these up projections of KV are linear to the KV cache length, while length of Q vector is always 1 in the decoding phase. The longer the KV cache history is, the more FLOPs are needed, and the up projections are repeated for every decoded token since only the projected KV latent were saved, which further increases the FLOPs needed. For the prefill phase, the weights absorbed version changes the dimensions of Q and KV thus increasing the number of FLOPs for attention. Based on roofline analysis, non absorbed version is beneficial for the prefill phase with input length 256 or larger The TensorRT LLM MLA implementation chooses different highly optimized kernels for prefill and decoding, see MLA.
Data Parallel for Attention module (ADP)#
The intuition of choosing attention DP is that doing TP for the MQA (where different GPUs compute different attention Q heads) will duplicate the KV cache memory, which limits the concurrency being achieved by the system. The duplication factor is equal to the TP group size, thus 8x for TP8. Small concurrency will hurt the throughput for the powerful system like NVIDIA DGX B200.
For DeepSeek R1 FP4 checkpoint with 8 B200 GPUs, the weights and activation occupies about 80 GB memory for each GPU, and the free KV cache per GPU will be 100GB. Assuming ISL 1K, OSL 2K, each request will consume about 200MB KV cache, which results in a per GPU max concurrency of 500. A single node 8xGPU system has a global concurrency of 4000. When using attention TP, the global concurrency will become just 500.
Silicon experiments show the attention DP technique provides a significant 400% speedup in the max throughput cases, when keeping all other factors the same.
Expert parallel for MoE (EP)#
The DeepSeek R1 MoE design features 256 small sparse experts and 1 shared expert, the GEMM problem size of these experts are as follows.
GEMM |
group |
GEMM N |
GEMM K |
|---|---|---|---|
shared_fc1 |
1 |
4096 |
7168 |
shared_fc2 |
1 |
7168 |
2048 |
sparse_fc1 |
256 |
4096 |
7168 |
sparse_fc2 |
256 |
7168 |
2048 |
These experts can be done in either Tensor-Parallelism or Expert-Parallelism ways. Our current ablation study reveals that Expert-Parallelism achieves better GEMM FLOPS because it has better GEMM problem sizes. And Expert-Parallelism can save GPU communication bandwidth compared to AllReduce, because the tokens only need to be sent to GPUs where the active experts for this token are located, while TP needs an AllReduce for all the tokens between all the GPUs. Also to be noted that, to scale the DeepSeek R1 inference to systems like GB200 NVL72 fully utilizing the aggregated memory bandwidth and tensor core flops, large EPs are needed. We are actively working on implementing it.
Silicon performance measurements show that Expert-Parallelism can provide 142% speedup for 1K/2K max throughput case, when keeping other factors the same.
MLA Layers Optimizations#
Other than the parallel strategy and precision strategy we explained above, we have done the following optimizations for layers/kernels inside the MLA module.
Attention Kernels Optimization
This provided a 20% E2E speedup compared to February baseline implementation. It involved implementing high-throughput generation MLA kernels. Techniques include using 2CTA Group variant of the Tensor Core 5th MMA instructions of Blackwell GPUs, overlapping MLA with softmax using interleaved tiles, and fine-tuning kernel selection heuristics for the DeepSeek R1 problem size.
FP8 KV Cache
An important optimization that yielded a 6% E2E throughput increase when assuming the concurrency was identical. Another benefit of FP8 KV cache is compressing the KV cache size by half, which allows for larger concurrency. It also enables the use of faster FP8 attention kernels compared to BF16. We recommend that users always turn on FP8 KV cache to get better performance. In the context phase, KV is quantized to FP8 and saved to the KV cache pool. In the generation phase, both Q and KV are quantized to FP8, and FP8 Multi-Query Attention (MQA) is used. Evaluation on GSM8k showed no meaningful accuracy drop. The quantization typically uses static per-tensor FP8 with a scaling factor defaulting to 1.0, but KV cache scaling factor can also be generated by calibrating on a target dataset. Below are the accuracy metrics of different combinations on the GSM8K dataset.
KV Cache Type
FP8 Checkpoint
FP4 Checkpoint
BF16 MLA and KV cache
0.9629
0.9606
FP8 MLA and KV cache
0.9613
0.9606
Manual GEMM tactics tuning
This optimization addresses cases where the default heuristic algorithm in cuBLAS is not performing best for specific GEMM shapes existing in the model. We built an internal tool to find the best algorithm for these specific shapes offline and then used the
cublasLtMatmulAPI to apply this specific, optimized algorithm at runtime. This is a necessary system optimization when general-purpose heuristics don’t find the most efficient kernel for all specific cases. We are also working actively with the cuBLAS team to further enhance the heuristics such that the best performance can always be achieved OOTB. See cublasScaledMM.cpp for the tuning details.Horizontal Fusions
This involves fusing GEMM operations of down projection of Q/KV and rope dimensions of K tensor. See modeling_deepseekv3.py for details. Horizontal fusion reduces the kernel launch overhead and increases the GEMM problem sizes which can achieve better HW utilization. It is a common technique shared by both min-latency and throughput optimizations.
2-stream optimizations
There are some small operations which can be run in parallel like the Q norm and KV norm inside the MLA. These operations cannot fully utilize the GPU math flops and the memory bandwidth, thus running in parallel CUDA streams can bring speed-up.
MoE Layers Optimizations#
The following optimizations are already done for MoE layers.
Mix I/O data type for the router GEMM
Achieved a 4% E2E speedup by avoiding casting operations and performing the GEMM using a mixture of input and output data types (e.g., BF16 input and FP32 output) directly. This eliminates the need to explicitly cast inputs to the output type and saves memory bandwidth.
Top-K Kernels Fusions
Resulted in a 7.4% E2E speedup. For DeepSeek R1, selecting the top 8 experts from 256 is done in a two-phase approach: first selecting top groups, then finding the top 8 within those groups. DeepSeek R1 uses some additional techniques for better expert load balance which involves adding bias and scales to the topK complications. All these operations resulted in 18 PyTorch ops when not fused, see Deepseekv3RoutingImpl. Fusing the multiple kernels involved in these Top-K calculations significantly reduces the overall computation time. Compared to using 18 native PyTorch ops, fusion can reduce the operation to as few as 2 kernels. Based on the measurement on B200, fusing these kernels can reduce the kernel time from 252us to 15us in the target setting.
FP4 AllGather Optimizations
Showed a 4% E2E speedup. This optimization replaces the BF16 AllGather operation with an FP4 version. Using a lower precision for this communication primitive reduces the amount of data transferred over the network, significantly improving communication efficiency. Also, since the original BF16 Tensor to be transferred will get cast into FP4 format after the AllGather communication, this optimization will not bring any impact to the accuracy. At the kernel level, we are seeing about 3x when switching from BF16 to FP4 AllGather.
CUTLASS Group GEMM optimizations
Provided a 1.3% E2E speedup. There are some CUTLASS level optimizations shared by both min-latency and throughput cases. Just updating CUTLASS to the latest version gives us 13% kernel improvement for the MoE groupGemm, and resulted in +1.3% E2E TPS/GPU.
Multi-stream optimizations Running the shared and routed experts in 2 streams combined with other multi-streaming optimizations in the MLA modules, contributing a 5.3% E2E speedup.
Runtime Optimizations#
These optimizations target the overall execution flow, scheduling, and resource management within the inference system. They are shared between DeepSeek R1 models and other models supported in the TensorRT LLM, here we are sharing some ablation study for the performance benefits on DeepSeek R1 on B200.
CUDA Graph
This had a significant 22% E2E performance impact for throughput scenarios.
CUDA Graphs allow capturing a sequence of CUDA operations and launching them as a single unit, drastically reducing kernel launch overheads. This is particularly beneficial for models with many small kernels, and particularly on the PyTorch flow, because the python host code normally executes slower than C++. Since the CUDA Graph freezes the kernel launch parameters, which is normally associated with the tensor shapes, it can only be safely used with static shape, meaning that different CUDA graphs need to be captured for different batch sizes. Each graph will have some cost of memory usage, and capturing time, thus we cannot capture every possible CUDA graph for all possible batches. For the non-captured batch sizes, PyTorch eager mode code will be executed.
There is a feature called CUDA Graph padding in TensorRT LLM, which is a good trade-off between the number of CUDA Graphs and the CUDA Graph hit ratio; it tries to pad a batch to the nearest one with a captured CUDA Graph. Normally you should enable the CUDA Graph padding feature to increase the CUDA Graph hit rate, but the padding itself has some overhead due to wasted tokens computation.
Users can opt-out the CUDA Graph padding feature to see the perf benefits, by setting the
cuda_graph_config:\n enable_padding: False, see API here Pytorch backend configOverlap Scheduler:
Showed a 4% E2E performance impact and should generally always be used. This scheduler manages the execution of different operations (like computation and communication) to overlap them effectively on the GPU and network. The intuition is to hide latency by performing computation while waiting for data transfers or vice versa, improving overall hardware utilization. The overlap schedule is already defaulted on in TensorRT LLM by commit. In case there are corner cases where it does not work, users can still opt-out this feature by set disable_overlap_scheduler to true.
Memory Optimizations
Resulted in a 4GB improvement. This includes techniques like chunked MoE (specifically for Hopper) and fixing a cuda context init bug. These methods reduce the memory footprint of the model weights or intermediate tensors, allowing for larger batch sizes or sequence lengths, and preventing Out-of-Memory (OOM) errors.
How to reproduce#
See Perf practices
Future Works#
Large EP
Chunked context
More communication overlap
Acknowledgment#
The substantial throughput advancements for DeepSeek R1 on Blackwell GPUs, as detailed in this post, are the fruit of a dedicated and collaborative engineering effort. Achieving nearly a 2.3x increase in TPS/GPU required a deep dive into MLA layers, MoE layers, and runtime optimizations. We extend our sincere appreciation to all the engineers involved in this intensive optimization process. Their collective expertise in pushing the boundaries of throughput performance within TensorRT LLM has been instrumental. We trust that sharing these specific strategies for maximizing throughput will prove beneficial to the developer community as they tackle demanding LLM inference workloads on NVIDIA hardware.