Storage and Access#
NCore V4 components (see Data Formats) can be persisted in two storage formats and accessed from local or remote storage backends. Each group of component is represented as a zarr group, which can be stored as a directory-based zarr stores or as single-file indexed tar archives.
Indexed Tar Archive Format (.itar)#
NCore defines a custom .itar (indexed tar) container format specifically
tailored to dataset and use-case characteristics in robotics and autonomous
vehicle applications. The .itar format packages zarr chunks as sequential
tar members in a single file and appends a compressed index at the end of a
regular tar archive, combining the streaming efficiency of tar with random-access
capability.

Comparison of regular tar files with it’s 512 byte blocks (as used by, e.g., WebDataset, supporting linear streaming but no random access) with NCore’s indexed tar format, which appends a compressed index enabling O(1) key lookups and direct seeks to any chunk.#
The .itar store implements the abstract zarr Store interface, so it can
be used as a drop-in replacement for directory stores in all NCore APIs. Via
UPath, .itar containers can
also be accessed transparently from cloud storage backends (e.g., S3, GCS)
without requiring a local copy.
Tradeoffs#
.itar(container file) – efficient for distribution, cloud storage, and atomic transfers; supports both sequential streaming and random access via the appended indexdirectory store – individual chunk files on disk; simpler for debugging and incremental updates
Both formats are accessed through the same
SequenceComponentGroupsReader and
SequenceComponentGroupsWriter APIs.
Read Performance (local)#
The chart below compares .itar read throughput against four alternative
storage formats on a synthetic dataset of the same 1k JPEG images (2k and 4k
resolutions, ~4.5 GB on local SSD) with associated per-image meta-data (poses,
timestamps, etc.). Throughput is measured with init cost excluded (formats
pre-opened); init cost is reported separately as time-to-first-read.
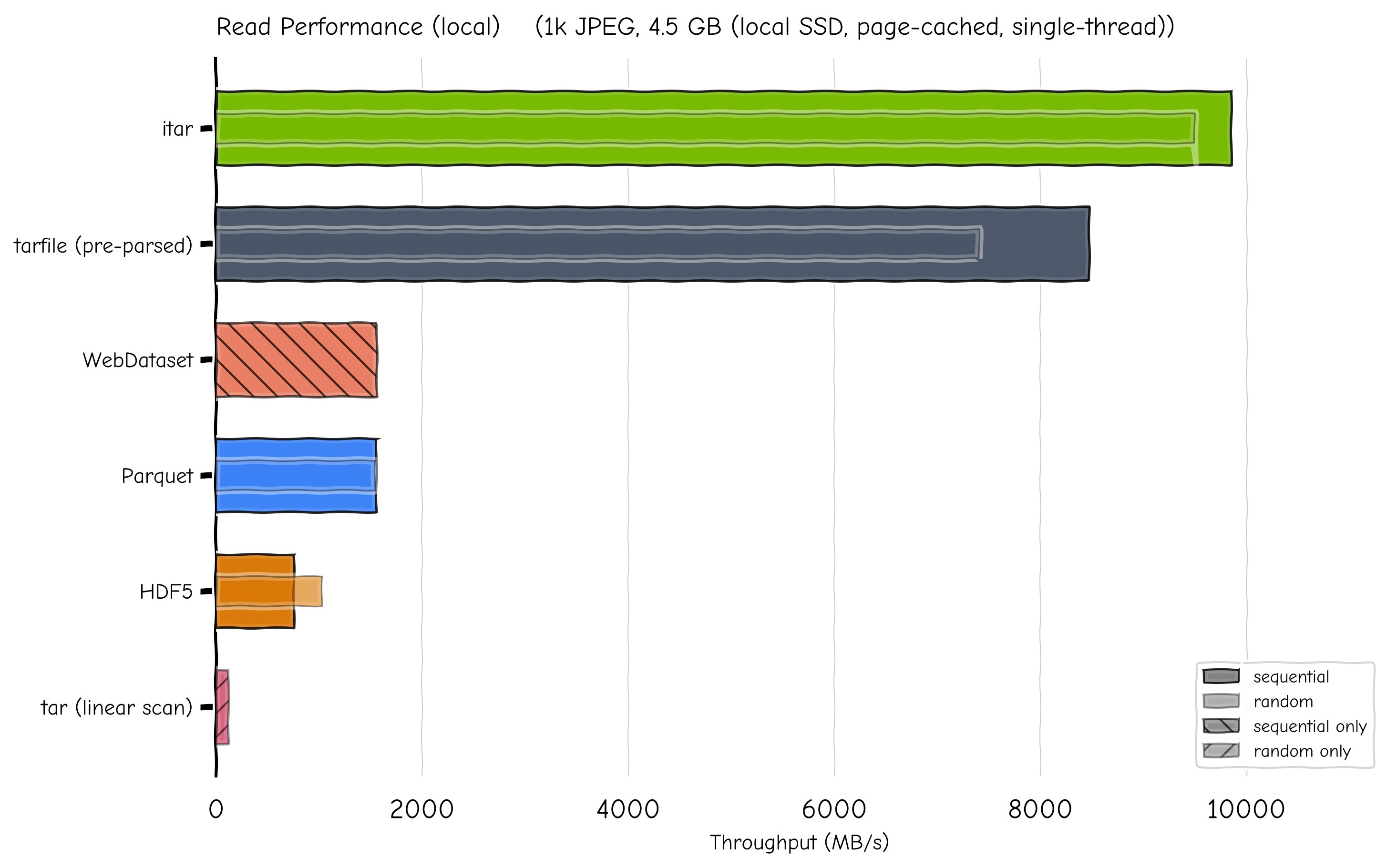
Read throughput across five storage formats. Full bar = sequential; inner bar = random access.#
Format |
Seq (MB/s) |
Rand (MB/s) |
Seq latency |
Rand latency |
Time-to-first-read |
|---|---|---|---|---|---|
|
9847 |
9492 |
0.46 ms |
0.48 ms |
2.1 ms (decompress index) |
|
8470 |
7402 |
0.54 ms |
0.62 ms |
82.6 ms (scan all file headers) |
|
— |
119 |
— |
38.2 ms |
per-access (no index) |
1 557 |
— |
2.91 ms |
— |
3.2 ms (pipeline build) |
|
1552 |
1542 |
2.92 ms |
2.98 ms |
2 929 ms (materialise table) |
|
754 |
1027 |
6.01 ms |
4.48 ms |
1.0 ms (B-tree open) |
Even with tarfile’s headers pre-parsed, .itar is 16% faster sequential and
28% faster random. The gap comes from tarfile’s extractfile() wrapping
data in three Python layers (ExFileObject → _FileInFile →
BufferedReader), while .itar does a single seek + read.
.itar’s time-to-first-read is 2.1 ms (decompressing a ~14 KB CBOR/LZMA
trailer index) vs tarfile’s 82.6 ms (sequential scan of all tar headers).
The tarfile linear-scan scenario (119 MB/s) shows the 80 × penalty of
random access without any index.
Note
All reads are from OS page cache (local SSD). On cold disk or network I/O the differences narrow.
Loading V4 Data#
V4 sequences are loaded by specifying one or more component store paths:
from ncore.data.v4 import SequenceComponentGroupsReader
from pathlib import Path
# Load sequence from multiple component stores
reader = SequenceComponentGroupsReader([
Path("ncore4.zarr.itar"), # default components
Path("ncore4-calibv2.zarr.itar"), # alternative calibration
])
# Access specific components
poses_readers = reader.open_component_readers(PosesComponent.Reader)
camera_readers = reader.open_component_readers(CameraSensorComponent.Reader)
Cloud and Remote Storage Access#
NCore accesses all data paths through
UPath (universal_pathlib),
a drop-in pathlib.Path replacement built on top of
fsspec. This means component
stores can be read transparently from cloud storage backends – the same
SequenceComponentGroupsReader API works for local
files and remote URLs alike.
Supported URL Schemes#
Any protocol that fsspec supports can be used as a component store path. Common examples:
Protocol |
Example URL |
|---|---|
S3 |
|
GCS |
|
Azure Blob |
|
HTTP(S) |
|
Local |
|
Required Dependencies#
nvidia-ncore ships with universal_pathlib (and its transitive
dependency fsspec), which is sufficient for local paths. To access
remote storage you need to install the corresponding fsspec filesystem
implementation:
Protocol |
Extra package |
Credentials / configuration |
|---|---|---|
S3 |
AWS credentials ( |
|
GCS |
|
|
Azure Blob |
|
|
HTTP(S) |
(built-in) |
n/a |
Install the extra package for the protocol you need, for example:
pip install nvidia-ncore s3fs # for S3
pip install nvidia-ncore gcsfs # for GCS
pip install nvidia-ncore adlfs # for Azure Blob
Loading Remote Component Stores#
Pass remote URLs directly to
SequenceComponentGroupsReader:
from ncore.data.v4 import SequenceComponentGroupsReader
from upath import UPath
reader = SequenceComponentGroupsReader([
UPath("s3://my-bucket/sequences/seq01/ncore4.zarr.itar"),
UPath("s3://my-bucket/sequences/seq01/ncore4-labels.zarr.itar"),
])
For S3-compatible endpoints or when a specific AWS profile is needed,
pass additional keyword arguments through UPath:
# Use a named AWS profile
store_path = UPath(
"s3://my-bucket/sequences/seq01/ncore4.zarr.itar",
profile="my-aws-profile",
)
# Tune download performance
store_path = UPath(
"s3://my-bucket/sequences/seq01/ncore4.zarr.itar",
profile="my-aws-profile",
default_block_size=5 * 1024 * 1024, # 5 MB download chunks
default_cache_type="blockcache", # fsspec file-descriptor caching strategy
)
# Point to an S3-compatible endpoint (e.g. MinIO)
store_path = UPath(
"s3://my-bucket/sequences/seq01/ncore4.zarr.itar",
client_kwargs={"endpoint_url": "https://minio.example.com"},
)
reader = SequenceComponentGroupsReader([store_path])
All keyword arguments accepted by the underlying S3FileSystem (or the respective fsspec filesystem class for other protocols) can be forwarded this way.
Read Performance (S3)#
The chart below compares streaming read throughput from S3 on the same
synthetic dataset. .itar reads individual samples via byte-range
requests using the trailer index; other formats use their native streaming
or fsspec-based file-object capabilities.
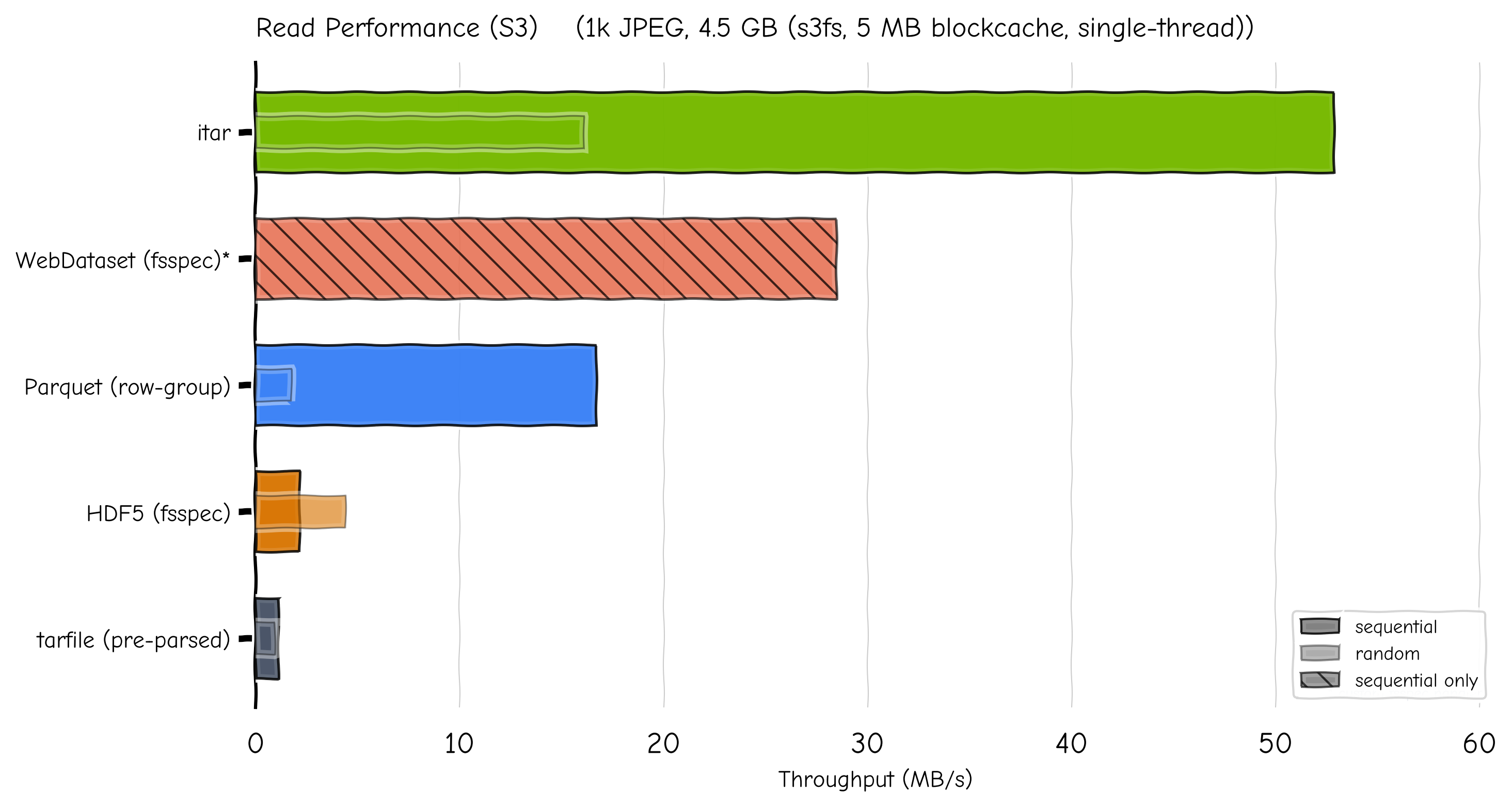
S3 streaming throughput. Full bar = sequential; inner bar = random access.#
Format |
Seq (MB/s) |
Rand (MB/s) |
Seq latency |
Rand latency |
Time-to-first-read |
|---|---|---|---|---|---|
|
53 |
16 |
53 ms |
281 ms |
240 ms (decompress index) |
|
28 |
— |
98 ms |
— |
536 ms |
|
17 |
2 |
167 ms |
2 614 ms |
8.7 s (read footer) |
|
2 |
4 |
1 303 ms |
1 031 ms |
304 ms |
|
1 |
1 |
2 564 ms |
4 906 ms |
119 s (scan all headers) |
.itar’s time-to-first-read over S3 is 240 ms — fast enough for
interactive use. In contrast, tarfile must scan all 2 000 tar headers
over the network before any random access is possible (119 s). Parquet
reads only the footer on open (8.7 s for this dataset) and then fetches
individual row groups via byte-range requests.
1 WebDataset does not natively support s3:// URLs. Results
use a custom fsspec-based handler registered in gopen_schemes.
Note
Measured from cluster nodes to S3-compatible storage (SwiftStack).
s3fs with 5 MB blockcache, single-threaded.
Performance Recommendations#
Use the
.itarformat for cloud-stored data. The indexed tar archive enables random access with a single file, avoiding the large number of small HTTP requests that directory-based zarr stores would incur.Enable consolidated metadata (the default). The
open_consolidatedparameter onSequenceComponentGroupsReaderisTrueby default, which pre-loads all zarr metadata in a single read. This is especially important for remote stores where each metadata lookup would otherwise be a separate round-trip.Tune the block size and cache type for your workload. The
default_block_sizeanddefault_cache_typeparameters onUPathcontrol how much data is fetched per HTTP request and how it is cached in memory. For mixed sequential/random workloads, 5 MB withblockcacheprovides the best balance (~50 MB/s sequential, ~16 MB/s random on.itar). Larger block sizes (16–64 MB) improve sequential throughput at the cost of random access performance.Consider local caching for repeated access to the same data. fsspec supports transparent caching via the
simplecacheorfilecacheprotocols:# Cache remote files locally on first access store_path = UPath( "simplecache::s3://my-bucket/sequences/seq01/ncore4.zarr.itar", s3={"profile": "my-aws-profile"}, simplecache={"cache_storage": "/tmp/ncore_cache"}, )