Note
Go to the end to download the full example code.
FIRE Geometry Optimization (LJ Cluster)#
This example demonstrates geometry optimization with the FIRE optimizer using:
- The package LJ implementation (neighbor-list accelerated)
- The package FIRE kernels (nvalchemiops.dynamics.optimizers)
- The shared example utilities in examples.dynamics._dynamics_utils
We optimize a small Lennard-Jones cluster (an isolated cluster inside a large box) and plot convergence (energy and max force).
from __future__ import annotations
import matplotlib.pyplot as plt
import numpy as np
import warp as wp
from _dynamics_utils import MDSystem, create_random_cluster
from nvalchemiops.dynamics.optimizers import fire_step
wp.init()
device = "cuda:0" if wp.is_cuda_available() else "cpu"
print(f"Using device: {device}")
Using device: cuda:0
Create a Lennard-Jones Cluster#
We use an “isolated cluster in a large box” approach (PBC far away), which works well with the existing neighbor-list machinery.
num_atoms = 32
epsilon = 0.0104 # eV (argon-like)
sigma = 3.40 # Å
cutoff = 2.5 * sigma
skin = 0.5
box_L = 80.0 # Å (large to avoid self-interaction across PBC)
cell = np.eye(3, dtype=np.float64) * box_L
initial_positions = create_random_cluster(
num_atoms=num_atoms,
radius=12.0,
min_dist=0.9 * sigma,
center=np.array([0.5 * box_L, 0.5 * box_L, 0.5 * box_L]),
seed=42,
)
system = MDSystem(
positions=initial_positions,
cell=cell,
masses=np.full(num_atoms, 39.948, dtype=np.float64), # amu (argon)
epsilon=epsilon,
sigma=sigma,
cutoff=cutoff,
skin=skin,
switch_width=0.0,
device=device,
dtype=np.float64,
)
Initialized MD system with 32 atoms
Cell: 80.00 x 80.00 x 80.00 Å
Cutoff: 8.50 Å (+ 0.50 Å skin)
LJ: ε = 0.0104 eV, σ = 3.40 Å
Device: cuda:0, dtype: <class 'numpy.float64'>
Units: x [Å], t [fs], E [eV], m [eV·fs²/Ų] (from amu), v [Å/fs]
FIRE Optimization Loop#
We use the unified fire_step API that handles:
- Velocity mixing (FIRE algorithm)
- Adaptive timestep (dt)
- Adaptive mixing parameter (alpha)
- MD-like position update with maxstep capping
max_steps = 3000
force_tolerance = 1e-3 # eV/Å (max force)
# FIRE parameters
dt0 = 1.0
dt_max = 10.0
dt_min = 1e-3
alpha0 = 0.1
f_inc = 1.1
f_dec = 0.5
f_alpha = 0.99
n_min = 5
maxstep = 0.2 * sigma # Å (max displacement per iteration)
# Device-side FIRE state arrays (shape = (1,) for single system)
wp_dtype = system.wp_dtype
dt_wp = wp.array([dt0], dtype=wp_dtype, device=device)
alpha_wp = wp.array([alpha0], dtype=wp_dtype, device=device)
alpha_start_wp = wp.array([alpha0], dtype=wp_dtype, device=device)
f_alpha_wp = wp.array([f_alpha], dtype=wp_dtype, device=device)
dt_min_wp = wp.array([dt_min], dtype=wp_dtype, device=device)
dt_max_wp = wp.array([dt_max], dtype=wp_dtype, device=device)
maxstep_wp = wp.array([maxstep], dtype=wp_dtype, device=device)
n_steps_positive_wp = wp.zeros(1, dtype=wp.int32, device=device)
n_min_wp = wp.array([n_min], dtype=wp.int32, device=device)
f_dec_wp = wp.array([f_dec], dtype=wp_dtype, device=device)
f_inc_wp = wp.array([f_inc], dtype=wp_dtype, device=device)
uphill_flag_wp = wp.zeros(1, dtype=wp.int32, device=device)
# Accumulators for diagnostic scalars (vf, vv, ff) - must be zeroed before each step
vf_wp = wp.zeros(1, dtype=wp_dtype, device=device)
vv_wp = wp.zeros(1, dtype=wp_dtype, device=device)
ff_wp = wp.zeros(1, dtype=wp_dtype, device=device)
# History for plotting
energy_hist: list[float] = []
maxf_hist: list[float] = []
dt_hist: list[float] = []
alpha_hist: list[float] = []
print("\n" + "=" * 95)
print("FIRE GEOMETRY OPTIMIZATION (LJ cluster)")
print("=" * 95)
print(f" atoms: {num_atoms}, cutoff={cutoff:.2f} Å, box={box_L:.1f} Å")
print(f" max_steps={max_steps}, force_tol={force_tolerance:.2e} eV/Å")
print(f" dt0={dt0}, dt_max={dt_max}, alpha0={alpha0}, n_min={n_min}")
print(f" dt_min={dt_min}, maxstep={maxstep:.3f} Å")
log_interval = 100
check_interval = 50
for step in range(max_steps):
# Compute forces at current positions
energies = system.compute_forces()
# Zero the accumulators before each FIRE step
vf_wp.zero_()
vv_wp.zero_()
ff_wp.zero_()
# Single FIRE step using the unified API
# This performs: diagnostic computation, velocity mixing, parameter update, MD step
fire_step(
positions=system.wp_positions,
velocities=system.wp_velocities,
forces=system.wp_forces,
masses=system.wp_masses,
alpha=alpha_wp,
dt=dt_wp,
alpha_start=alpha_start_wp,
f_alpha=f_alpha_wp,
dt_min=dt_min_wp,
dt_max=dt_max_wp,
maxstep=maxstep_wp,
n_steps_positive=n_steps_positive_wp,
n_min=n_min_wp,
f_dec=f_dec_wp,
f_inc=f_inc_wp,
uphill_flag=uphill_flag_wp,
vf=vf_wp,
vv=vv_wp,
ff=ff_wp,
)
# Logging / stopping criteria (host read only at intervals)
if step % check_interval == 0 or step == max_steps - 1:
pe = float(energies.numpy().sum())
fmax = float(np.linalg.norm(system.wp_forces.numpy(), axis=1).max())
energy_hist.append(pe)
maxf_hist.append(fmax)
dt_hist.append(float(dt_wp.numpy()[0]))
alpha_hist.append(float(alpha_wp.numpy()[0]))
if step % log_interval == 0 or step == max_steps - 1:
print(
f"step={step:5d} PE={pe:12.6f} eV max|F|={fmax:10.3e} eV/Å "
f"dt={dt_hist[-1]:6.3f} alpha={alpha_hist[-1]:7.4f} "
f"n+={int(n_steps_positive_wp.numpy()[0]):3d}"
)
if fmax < force_tolerance:
print(f"\nConverged at step {step} (max|F|={fmax:.3e} eV/Å).")
break
===============================================================================================
FIRE GEOMETRY OPTIMIZATION (LJ cluster)
===============================================================================================
atoms: 32, cutoff=8.50 Å, box=80.0 Å
max_steps=3000, force_tol=1.00e-03 eV/Å
dt0=1.0, dt_max=10.0, alpha0=0.1, n_min=5
dt_min=0.001, maxstep=0.680 Å
step= 0 PE= -0.022508 eV max|F|= 3.541e-01 eV/Å dt= 0.500 alpha= 0.1000 n+= 0
step= 100 PE= -0.321531 eV max|F|= 1.081e-02 eV/Å dt=10.000 alpha= 0.0381 n+=100
step= 200 PE= -0.394863 eV max|F|= 2.618e-02 eV/Å dt=10.000 alpha= 0.0139 n+=200
step= 300 PE= -0.457969 eV max|F|= 2.563e-02 eV/Å dt=10.000 alpha= 0.0051 n+=300
step= 400 PE= -0.511123 eV max|F|= 1.267e-02 eV/Å dt=10.000 alpha= 0.0430 n+= 88
step= 500 PE= -0.567782 eV max|F|= 1.829e-02 eV/Å dt=10.000 alpha= 0.0157 n+=188
step= 600 PE= -0.621281 eV max|F|= 3.008e-02 eV/Å dt=10.000 alpha= 0.0058 n+=288
step= 700 PE= -0.668527 eV max|F|= 6.530e-03 eV/Å dt=10.000 alpha= 0.0662 n+= 45
step= 800 PE= -0.744103 eV max|F|= 1.079e-02 eV/Å dt=10.000 alpha= 0.0242 n+=145
step= 900 PE= -0.810186 eV max|F|= 1.669e-02 eV/Å dt=10.000 alpha= 0.0089 n+=245
step= 1000 PE= -0.872658 eV max|F|= 1.165e-02 eV/Å dt=10.000 alpha= 0.0611 n+= 53
step= 1100 PE= -0.934003 eV max|F|= 1.227e-02 eV/Å dt=10.000 alpha= 0.0224 n+=153
step= 1200 PE= -0.954023 eV max|F|= 3.749e-03 eV/Å dt=10.000 alpha= 0.0457 n+= 82
step= 1300 PE= -0.996963 eV max|F|= 8.952e-03 eV/Å dt=10.000 alpha= 0.0167 n+=182
step= 1400 PE= -1.016477 eV max|F|= 6.099e-03 eV/Å dt=10.000 alpha= 0.0747 n+= 33
step= 1500 PE= -1.034997 eV max|F|= 4.540e-03 eV/Å dt=10.000 alpha= 0.0273 n+=133
step= 1600 PE= -1.078106 eV max|F|= 1.045e-02 eV/Å dt=10.000 alpha= 0.0100 n+=233
step= 1700 PE= -1.097269 eV max|F|= 1.413e-02 eV/Å dt= 8.858 alpha= 0.0941 n+= 10
step= 1800 PE= -1.109143 eV max|F|= 2.956e-03 eV/Å dt=10.000 alpha= 0.0345 n+=110
step= 1900 PE= -1.117740 eV max|F|= 1.849e-03 eV/Å dt=10.000 alpha= 0.0778 n+= 29
step= 2000 PE= -1.119411 eV max|F|= 2.907e-03 eV/Å dt=10.000 alpha= 0.0285 n+=129
step= 2100 PE= -1.127265 eV max|F|= 1.813e-03 eV/Å dt=10.000 alpha= 0.0818 n+= 24
Converged at step 2150 (max|F|=5.054e-04 eV/Å).
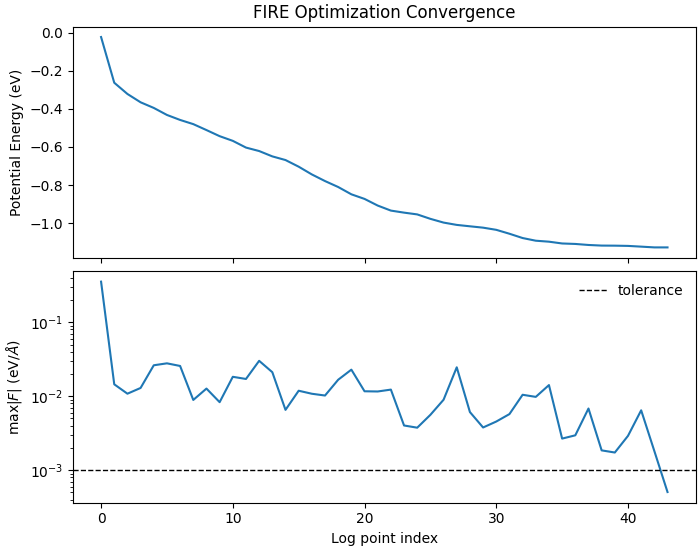
Plot convergence
steps = np.arange(len(energy_hist))
fig, ax = plt.subplots(2, 1, figsize=(7.0, 5.5), sharex=True, constrained_layout=True)
ax[0].plot(steps, energy_hist, lw=1.5)
ax[0].set_ylabel("Potential Energy (eV)")
ax[0].set_title("FIRE Optimization Convergence")
ax[1].semilogy(steps, maxf_hist, lw=1.5)
ax[1].axhline(force_tolerance, color="k", ls="--", lw=1.0, label="tolerance")
ax[1].set_xlabel("Log point index")
ax[1].set_ylabel(r"max$|F|$ (eV/$\AA$)")
ax[1].legend(frameon=False, loc="best")
<matplotlib.legend.Legend object at 0x1551b7e17c50>
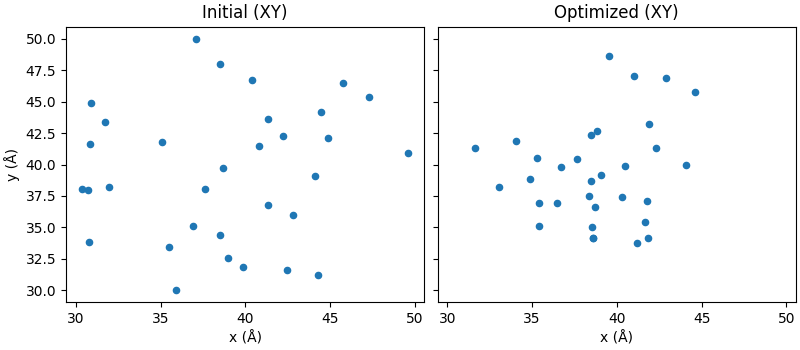
Visualize initial vs final geometry (XY projection)
pos0 = initial_positions
pos1 = system.wp_positions.numpy()
fig2, ax2 = plt.subplots(
1, 2, figsize=(8.0, 3.5), sharex=True, sharey=True, constrained_layout=True
)
ax2[0].scatter(pos0[:, 0], pos0[:, 1], s=20)
ax2[0].set_title("Initial (XY)")
ax2[0].set_xlabel("x (Å)")
ax2[0].set_ylabel("y (Å)")
ax2[1].scatter(pos1[:, 0], pos1[:, 1], s=20)
ax2[1].set_title("Optimized (XY)")
ax2[1].set_xlabel("x (Å)")
plt.show()
Total running time of the script: (0 minutes 1.091 seconds)