Note
Go to the end to download the full example code.
Batched FIRE2 Optimization with LJ Clusters#
This example demonstrates batched geometry optimization using the FIRE2
optimizer (Guenole et al., 2020) with batch_idx batching.
Compared to FIRE (08_fire_batched.py), FIRE2:
Assumes unit mass (no
massesparameter)Has a simpler state: only
alpha,dt,nsteps_incper systemHyperparameters are Python scalars (
delaystep,dtgrow, etc.)Only supports
batch_idxmode (noatom_ptrvariant)
We optimize multiple independent LJ clusters in parallel, with per-system FIRE2 parameters that adapt independently.
from __future__ import annotations
import matplotlib.pyplot as plt
import numpy as np
import warp as wp
from _dynamics_utils import (
DEFAULT_CUTOFF,
DEFAULT_SKIN,
EPSILON_AR,
SIGMA_AR,
BatchedMDSystem,
create_random_box_cluster,
)
from nvalchemiops.batch_utils import create_atom_ptr, create_batch_idx
from nvalchemiops.dynamics.optimizers import fire2_step
from nvalchemiops.segment_ops import (
segmented_max_norm,
segmented_sum,
)
# ==============================================================================
# Main Example
# ==============================================================================
wp.init()
device = "cuda:0" if wp.is_cuda_available() else "cpu"
print(f"Using device: {device}")
Using device: cuda:0
Create Batch of LJ Clusters#
num_systems = 4
atom_counts = [16, 24, 20, 32] # Different sizes per system
total_atoms = sum(atom_counts)
# Box size large enough to avoid self-interaction
box_L = 30.0 # Å
min_dist = 0.9 * SIGMA_AR
print("\nBatch setup:")
print(f" Number of systems: {num_systems}")
print(f" Atoms per system: {atom_counts}")
print(f" Total atoms: {total_atoms}")
print(f" LJ parameters: ε = {EPSILON_AR:.4f} eV, σ = {SIGMA_AR:.2f} Å")
# Generate initial positions for all systems
all_positions = []
all_cells = []
for sys_id, count in enumerate(atom_counts):
pos = create_random_box_cluster(count, box_L, min_dist, seed=42 + sys_id)
all_positions.append(pos)
all_cells.append(np.eye(3, dtype=np.float64) * box_L)
# Concatenate into batched arrays
positions_np = np.concatenate(all_positions, axis=0)
cells_np = np.stack(all_cells, axis=0)
batch_idx_np = np.concatenate(
[np.full(count, sys_id, dtype=np.int32) for sys_id, count in enumerate(atom_counts)]
)
# Create Warp arrays
positions = wp.array(positions_np.copy(), dtype=wp.vec3d, device=device)
velocities = wp.zeros(total_atoms, dtype=wp.vec3d, device=device)
# Create batching arrays
atom_counts_wp = wp.array(np.array(atom_counts, dtype=np.int32), device=device)
atom_ptr = wp.zeros(num_systems + 1, dtype=wp.int32, device=device)
create_atom_ptr(atom_counts_wp, atom_ptr)
batch_idx = wp.zeros(total_atoms, dtype=wp.int32, device=device)
create_batch_idx(atom_ptr, batch_idx)
print(f" batch_idx shape: {batch_idx.shape}")
print(f" atom_ptr shape: {atom_ptr.shape}")
print(f" atom_ptr values: {atom_ptr.numpy()}")
# Create batched MD system (using BatchedMDSystem, ignoring velocities/masses for FIRE2)
lj_system = BatchedMDSystem(
positions=positions_np,
cells=cells_np,
batch_idx=batch_idx_np,
num_systems=num_systems,
epsilon=EPSILON_AR,
sigma=SIGMA_AR,
cutoff=DEFAULT_CUTOFF,
skin=DEFAULT_SKIN,
switch_width=1.0, # Smooth cutoff for optimization
device=device,
)
Batch setup:
Number of systems: 4
Atoms per system: [16, 24, 20, 32]
Total atoms: 92
LJ parameters: ε = 0.0104 eV, σ = 3.40 Å
batch_idx shape: (92,)
atom_ptr shape: (5,)
atom_ptr values: [ 0 16 40 60 92]
FIRE2 Parameters (per-system)#
FIRE2 state: only alpha, dt, nsteps_inc per system. Hyperparameters are Python scalars with sensible defaults.
# Per-system state arrays (shape (B,))
alpha = wp.array([0.09] * num_systems, dtype=wp.float64, device=device)
dt = wp.array([0.005] * num_systems, dtype=wp.float64, device=device)
nsteps_inc = wp.zeros(num_systems, dtype=wp.int32, device=device)
# Scratch buffers (shape (B,))
vf = wp.zeros(num_systems, dtype=wp.float64, device=device)
v_sumsq = wp.zeros(num_systems, dtype=wp.float64, device=device)
f_sumsq = wp.zeros(num_systems, dtype=wp.float64, device=device)
max_norm = wp.zeros(num_systems, dtype=wp.float64, device=device)
FIRE2 Optimization#
max_steps = 2000
force_tol = 1e-3 # eV/Å
log_interval = 200
check_interval = 50
# History
energy_hist = []
maxf_hist = []
print("\n" + "=" * 80)
print("FIRE2 BATCHED OPTIMIZATION (batch_idx)")
print("=" * 80)
print(f"\nRunning FIRE2 optimization ({max_steps} max steps)...")
print(f"Force tolerance: {force_tol:.1e} eV/Å")
print("FIRE2 defaults: delaystep=60, dtgrow=1.05, alpha0=0.09, maxstep=0.1")
print("-" * 70)
print(f"{'Step':>6} {'Total E':>14} {'max|F|':>12} {'Converged':>12}")
print("-" * 70)
for step in range(max_steps):
# Update positions in LJ system and compute forces
wp.copy(lj_system.wp_positions, positions)
energies = lj_system.compute_forces()
# FIRE2 step
fire2_step(
positions=positions,
velocities=velocities,
forces=lj_system.wp_forces,
batch_idx=batch_idx,
alpha=alpha,
dt=dt,
nsteps_inc=nsteps_inc,
vf=vf,
v_sumsq=v_sumsq,
f_sumsq=f_sumsq,
max_norm=max_norm,
)
# Check convergence at intervals
if step % check_interval == 0 or step == max_steps - 1:
system_energies = wp.zeros(num_systems, dtype=wp.float64, device=device)
segmented_sum(energies, batch_idx, system_energies)
max_forces = wp.zeros(num_systems, dtype=wp.float64, device=device)
segmented_max_norm(lj_system.wp_forces, batch_idx, max_forces)
wp.synchronize()
system_energies_np = system_energies.numpy()
max_forces_np = max_forces.numpy()
total_energy = system_energies_np.sum()
global_max_f = max_forces_np.max()
num_converged = (max_forces_np < force_tol).sum()
energy_hist.append(total_energy)
maxf_hist.append(global_max_f)
if step % log_interval == 0 or step == max_steps - 1:
print(
f"{step:>6d} {total_energy:>14.6f} {global_max_f:>12.2e} {num_converged:>8d}/{num_systems}"
)
if num_converged == num_systems:
print(f"\nAll systems converged at step {step}!")
break
print(f"\nFinal per-system energies: {system_energies_np}")
print(f"Final max forces per system: {max_forces_np}")
================================================================================
FIRE2 BATCHED OPTIMIZATION (batch_idx)
================================================================================
Running FIRE2 optimization (2000 max steps)...
Force tolerance: 1.0e-03 eV/Å
FIRE2 defaults: delaystep=60, dtgrow=1.05, alpha0=0.09, maxstep=0.1
----------------------------------------------------------------------
Step Total E max|F| Converged
----------------------------------------------------------------------
0 -0.178234 2.85e-01 0/4
200 -0.302223 1.45e-02 0/4
400 -0.456152 5.03e-02 0/4
600 -0.600681 1.30e-02 0/4
800 -0.734234 3.88e-02 0/4
1000 -0.861586 1.64e-02 0/4
1200 -0.957798 3.51e-02 0/4
1400 -1.017783 1.08e-02 0/4
1600 -1.065102 1.43e-02 0/4
1800 -1.116602 7.41e-03 0/4
1999 -1.154061 5.18e-03 0/4
Final per-system energies: [-0.15214219 -0.27857798 -0.15079847 -0.5725424 ]
Final max forces per system: [0.00517704 0.00192463 0.00161538 0.00500106]
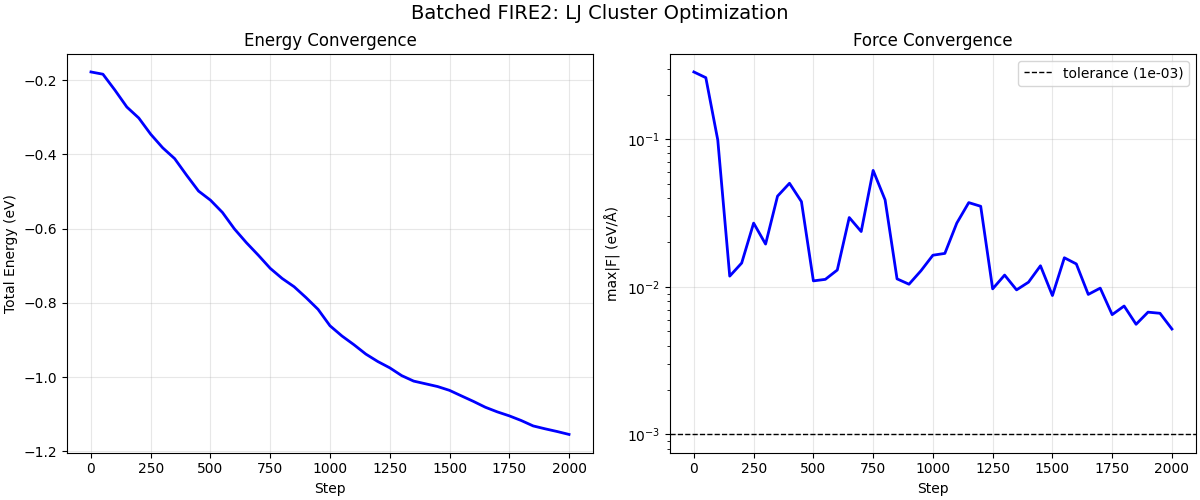
Plot Convergence#
fig, axes = plt.subplots(1, 2, figsize=(12, 5), constrained_layout=True)
steps_arr = np.arange(len(energy_hist)) * check_interval
axes[0].plot(steps_arr, energy_hist, "b-", lw=2)
axes[0].set_xlabel("Step")
axes[0].set_ylabel("Total Energy (eV)")
axes[0].set_title("Energy Convergence")
axes[0].grid(True, alpha=0.3)
axes[1].semilogy(steps_arr, maxf_hist, "b-", lw=2)
axes[1].axhline(
force_tol, color="k", ls="--", lw=1, label=f"tolerance ({force_tol:.0e})"
)
axes[1].set_xlabel("Step")
axes[1].set_ylabel("max|F| (eV/Å)")
axes[1].set_title("Force Convergence")
axes[1].legend()
axes[1].grid(True, alpha=0.3)
fig.suptitle("Batched FIRE2: LJ Cluster Optimization", fontsize=14)
plt.show()
Total running time of the script: (0 minutes 1.039 seconds)