RAG Playground Web Application
About the Web Application
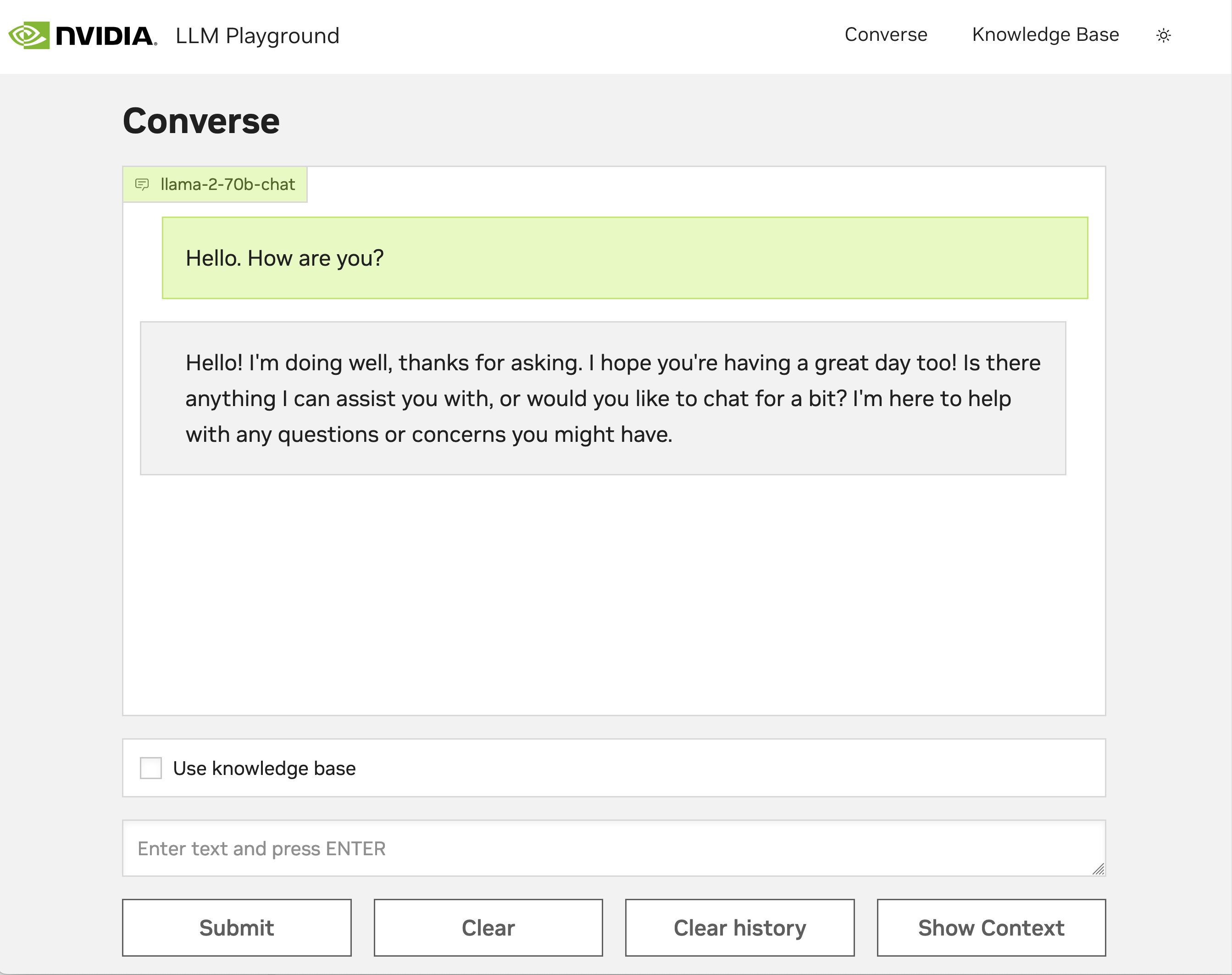
The web application provides a user interface to the RAG chain server APIs.
You can chat with the LLM and see responses streamed back for different examples.
By selecting Use knowledge base, the chat bot returns responses that are augmented with data from documents that you uploaded and were stored in the vector database.
To store content in the vector database, click Knowledge Base in the upper right corner and upload documents.
Web Application Design
At its core, the application is a FastAPI server written in Python. This FastAPI server hosts two Gradio applications, one for conversing with the model and another for uploading documents. These Gradio pages are wrapped in a static frame created with the NVIDIA Kaizen UI React+Next.js framework and compiled down to static pages. Iframes are used to mount the Gradio applications into the outer frame.
Running the Web Application Individually
To run the web application for development purposes, run the following commands:
Build the container from source:
$ source deploy/compose/compose.env $ docker compose -f deploy/compose/rag-app-text-chatbot.yaml build frontend
Start the container, which starts the server:
$ source deploy/compose/compose.env $ docker compose -f deploy/compose/rag-app-text-chatbot.yaml up frontend
Open the web application at
http://host-ip:8090.
If you upload multiple PDF files, the expected time of completion that is shown in the web application might not be correct.