Observability Tool
Introduction
Observability is a crucial aspect that facilitates the monitoring and comprehension of the internal state and behavior of a system or application. Applications based on RAG are intricate systems that encompass the interaction of numerous components. To enhance the performance of these RAG-based applications, observability is an efficient mechanism for both monitoring and debugging.
The following diagram shows high-level overview of how traces are captured.
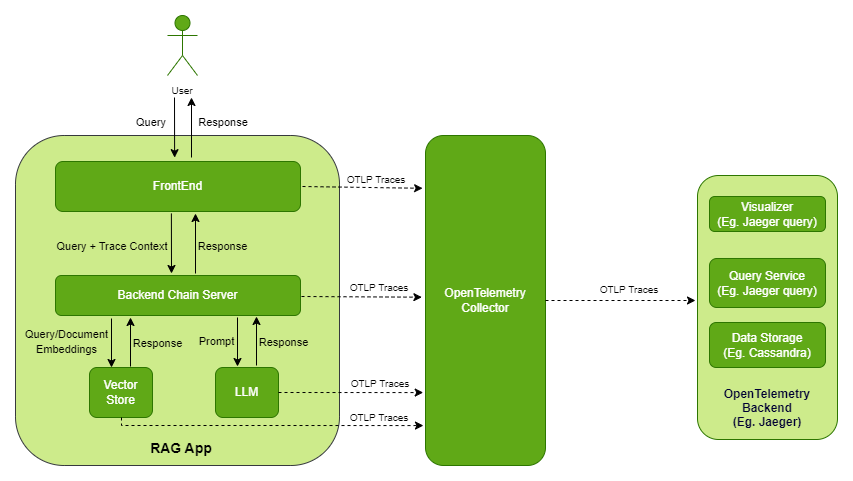
The observability stack adds following containers on top of the RAG app containers:
OpenTelemetry Collector: Receives, processes, and exports the traces.
Jaeger: Acts as an OpenTelemetry backend that provides storage, query service, and visualizer. You can configure any other OTLP-compatible backend such as Zipkin, Prometheus, and so on. To configure an alternative backend, refer to Configuration in the OpenTelemetry documentation.
Cassandra: Provides persistent storage for traces. Jaeger supports many other storage backends such as ElasticSearch, Kafka, and Badger. For a large scale, production deployment, the Jaeger team recommends ElasticSearch over Cassandra.
Key terms
- Span
A unit of work within a system, encapsulating information about a specific operation (Eg. LLM call, embedding generation etc).
- Traces
The recording of a request as it goes through a system, tracking every service the request comes in contact with. Multiple spans make a trace logically bound by parent-child relationship.
- Root Span
The first span in a trace, denoting the beginning and end of the entire operation.
- Span Attributes
Key-value pairs a Span may consist of to provide additional context or metadata.
- Collectors
Components that process and export telemetry data from instrumented applications.
- Context
Signifies current location within the trace hierarchy. The context determines whether a new span initiates a trace or connects to an existing parent span.
- Services
Microservices that generates telemetry data.
The following diagram shows a typical trace for query that uses a knowledge base and identifies the spans and root span.
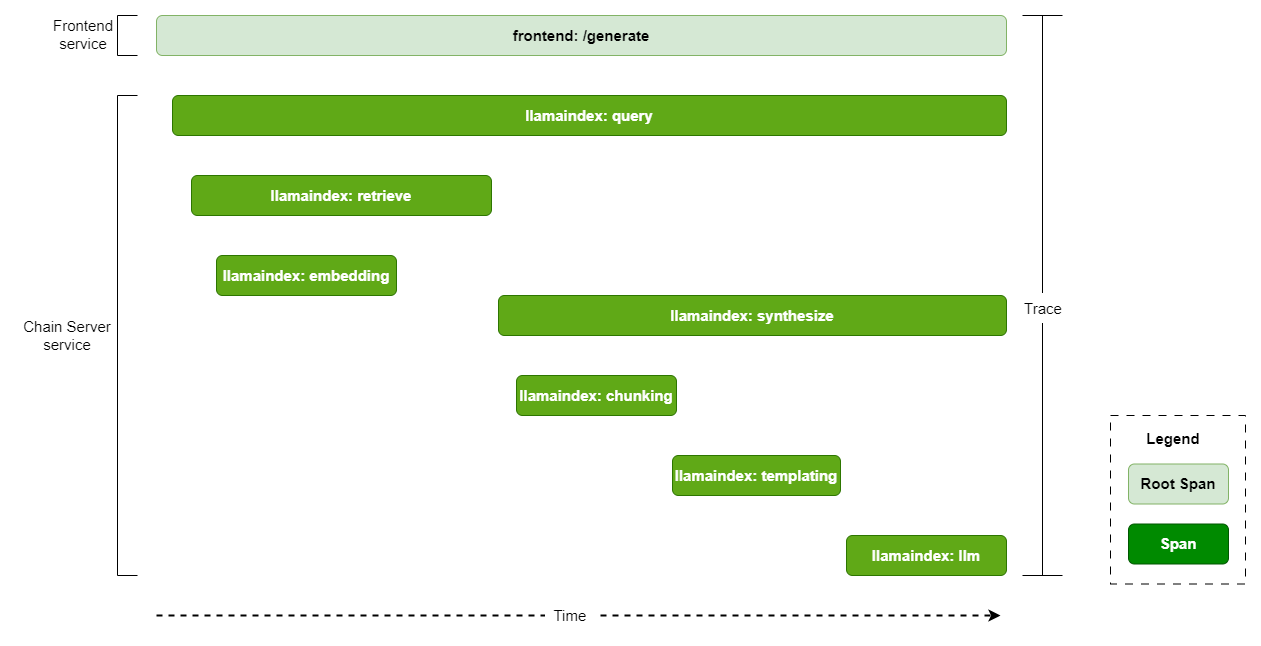
Prerequisites
Clone the Generative AI examples Git repository using Git LFS:
$ sudo apt -y install git-lfs $ git clone git@github.com:NVIDIA/GenerativeAIExamples.git $ cd GenerativeAIExamples/ $ git lfs pull
A host with an NVIDIA A100, H100, or L40S GPU.
Verify NVIDIA GPU driver version 535 or later is installed and that the GPU is in compute mode:
$ nvidia-smi -q -d compute
Example Output
==============NVSMI LOG============== Timestamp : Sun Nov 26 21:17:25 2023 Driver Version : 535.129.03 CUDA Version : 12.2 Attached GPUs : 1 GPU 00000000:CA:00.0 Compute Mode : Default
If the driver is not installed or below version 535, refer to the NVIDIA Driver Installation Quickstart Guide.
Install Docker Engine and Docker Compose. Refer to the instructions for Ubuntu.
Install the NVIDIA Container Toolkit.
Refer to the installation documentation.
When you configure the runtime, set the NVIDIA runtime as the default:
$ sudo nvidia-ctk runtime configure --runtime=docker --set-as-default
If you did not set the runtime as the default, you can reconfigure the runtime by running the preceding command.
Verify the NVIDIA container toolkit is installed and configured as the default container runtime:
$ cat /etc/docker/daemon.json
Example Output
{ "default-runtime": "nvidia", "runtimes": { "nvidia": { "args": [], "path": "nvidia-container-runtime" } } }
Run the
nvidia-smicommand in a container to verify the configuration:$ sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi -L
Example Output
GPU 0: NVIDIA A100 80GB PCIe (UUID: GPU-d8ce95c1-12f7-3174-6395-e573163a2ace)
Build and Start the Containers
In the Generative AI Examples repository, edit the
deploy/compose/configs/otel-collector-config.yamlanddeploy/compose/configs/jaeger.yamlfiles.Refer to configuration in the OpenTelemetry documentation and the Jaeger all-in-one with Cassandra reference in the Jaeger documentation.
Edit the
deploy/compose/rag-app-text-chatbot.yamlfile. For the rag-playground and chain-server services, set the following environment variables:environment: OTEL_EXPORTER_OTLP_ENDPOINT: http://otel-collector:4317 OTEL_EXPORTER_OTLP_PROTOCOL: grpc ENABLE_TRACING: true
Deploy the developer RAG example:
$ docker compose --env-file deploy/compose/compose.env -f deploy/compose/rag-app-text-chatbot.yaml build $ docker compose --env-file deploy/compose/compose.env -f deploy/compose/rag-app-text-chatbot.yaml up -d
Start the Milvus vector database:
$ docker compose --env-file deploy/compose/compose.env -f deploy/compose/docker-compose-vectordb.yaml up -d milvus
Deploy the observability services:
$ docker compose --env-file deploy/compose/compose.env -f deploy/compose/docker-compose-observability.yaml build $ docker compose --env-file deploy/compose/compose.env -f deploy/compose/docker-compose-observability.yaml up -d
Example Output
✔ Container otel-collector Started ✔ Container cassandra Started ✔ Container compose-cassandra-schema-1 Started ✔ Container jaeger Started
Optional: Confirm the services are started:
$ docker ps --format "table {{.ID}}\t{{.Names}}\t{{.Status}}"
Example Output
CONTAINER ID NAMES STATUS beb1582320d6 jaeger Up 5 minutes 674c7bbb367e cassandra Up 6 minutes d11e35ee69f4 rag-playground Up 5 minutes 68f22b3842cb chain-server Up 5 minutes 751dd4fd80ec milvus-standalone Up 5 minutes (healthy) b435006c95c1 milvus-minio Up 6 minutes (healthy) 9108253d058d notebook-server Up 6 minutes 5315a9dc9eb4 milvus-etcd Up 6 minutes (healthy) d314a43074c8 otel-collector Up 6 minutes
Access the Jaeger web interface at
http://host-ip:16686from your web browser.
Example Traces
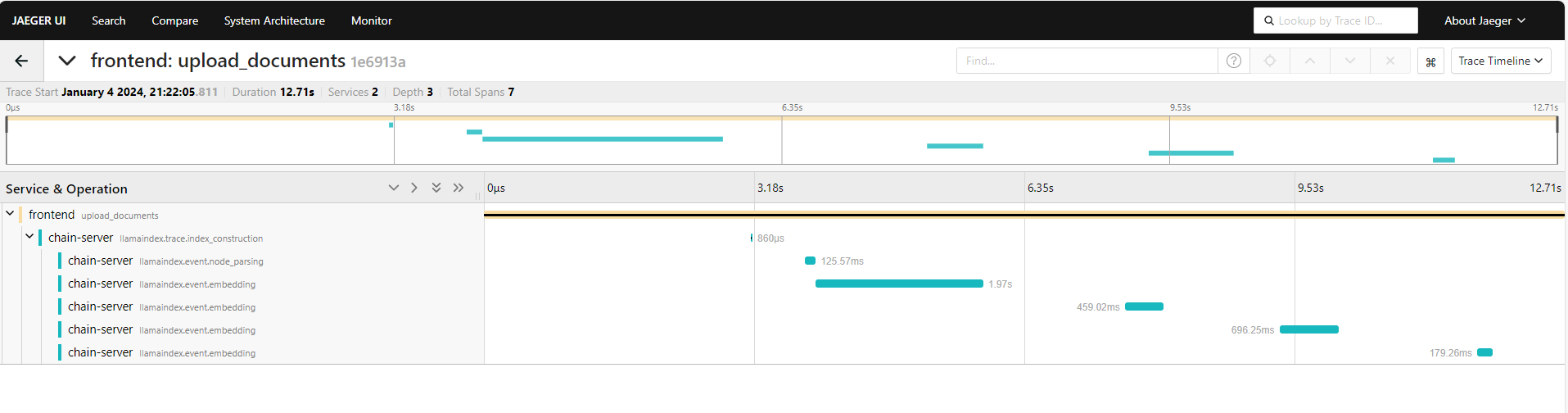
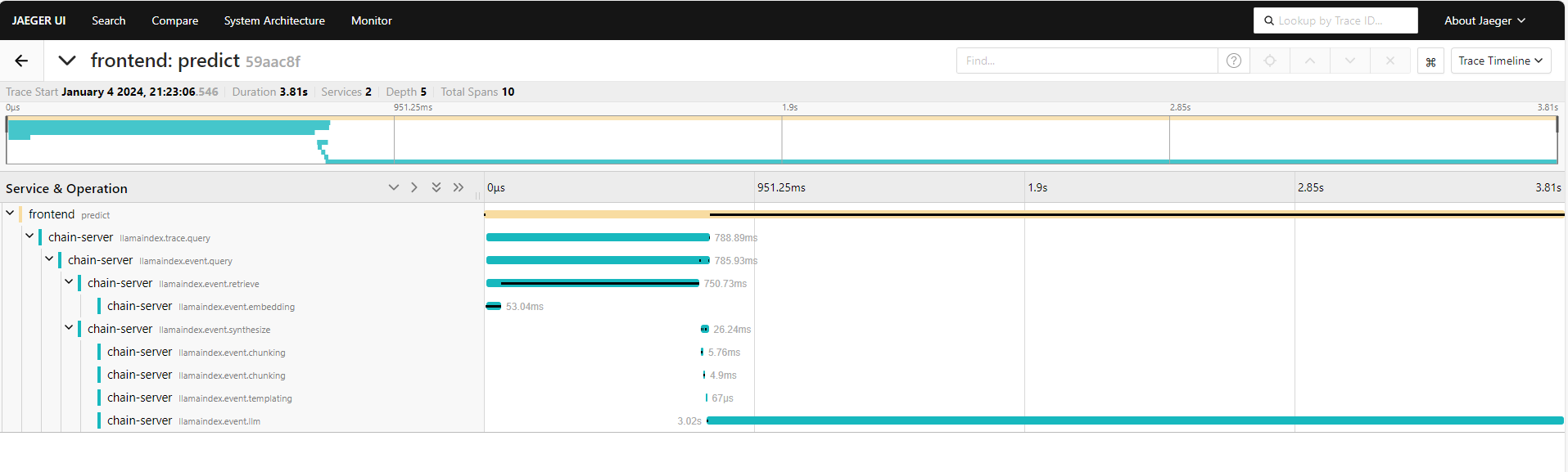
The following screenshots show traces from the Jaeger web interface.
Upload document trace
User query using knowledge base trace
Implementation Details
The user interface web application, named the RAG playground, and the chain server, are instrumented.
RAG Playground
The tracing.py module in the frontend application code performs the instrumentation. At high level, the code performs the following:
Sets up the OpenTelemetry configurations for resource name, frontend, span processor, and context propagator.
Provides instrumentation decorator functions,
instrumentation_wrapperandpredict_instrumentation_wrapper, for managing trace context across different services. This decorator function is used with the API functions in chat_client.py to create new span contexts. The span contexts can then be injected in the headers of the request made to the chain server. The code also logs span attributes that are extracted from the API request.
Chain Server
The tracing.py module in the chain server application code is responsible for instrumentation. At high level, the code performs the following:
Sets up the OpenTelemetry configurations for resource name, chain-server, span processor, and context propagator.
Initializes the LlamaIndex OpenTelemetry callback handler. The callback handler uses LlamaIndex callbacks to track various events such as LLM calls, chunking, embedding, and so on.
Provides an instrumentation decorator function,
instrumentation_wrapper, for managing trace context across different services. This decorator function is used with the API functions in server.py to extract the trace context that is present in requests from the frontend service and attach it in the new span created by the chain-server.
The instrumentation decorator function, instrumentation_wrapper, can be used to instrument any LlamaIndex application as long as LlamaIndex OpenTelemetry callback handler, opentelemetry_callback.py, is set as global handler in the application.