Multi-Turn Conversational Chat Bot
Example Features
This example showcases multi-turn conversational AI in a RAG pipeline. The chain server stores the conversation history and knowledge base in a vector database and retrieves them at runtime to understand contextual queries.
The example supports ingestion of PDF and text files. The documents are ingested in a dedicated document vector store, multi_turn_rag. The prompt for the example is tuned to act as a document chat bot. To maintain the conversation history, the chain server stores the previously asked query and the model’s generated answer as a text entry in a different and dedicated vector store for conversation history, conv_store. Both of these vector stores are part of a LangChain LCEL chain as LangChain Retrievers. When the chain is invoked with a query, the query passes through both the retrievers. The retriever retrieves context from the document vector store and the closest-matching conversation history from conversation history vector store. Afterward, the chunks are added into the LLM prompt as part of the chain.
Developers get free credits for 10K requests to any of the available models.
This example uses models from the NVIDIA API Catalog.
Model |
Embedding |
Framework |
Description |
Multi-GPU |
TRT-LLM |
Model Location |
Triton |
Vector Database |
|---|---|---|---|---|---|---|---|---|
ai-llama2-70b |
nvolveqa_40k |
LangChain |
QA chatbot |
NO |
NO |
API Catalog |
NO |
Milvus |
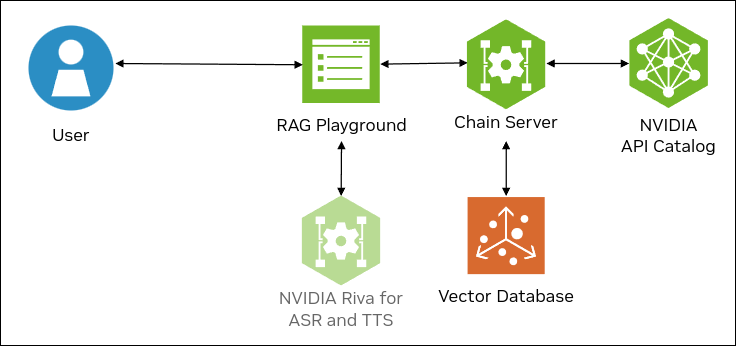
The following figure shows the sample topology:
The sample chat bot web application communicates with the chain server. The chain server sends inference requests to an NVIDIA API Catalog endpoint.
Optionally, you can deploy NVIDIA Riva. Riva can use automatic speech recognition to transcribe your questions and use text-to-speech to speak the answers aloud.
Prerequisites
Clone the Generative AI examples Git repository using Git LFS:
$ sudo apt -y install git-lfs $ git clone git@github.com:NVIDIA/GenerativeAIExamples.git $ cd GenerativeAIExamples/ $ git lfs pull
Install Docker Engine and Docker Compose. Refer to the instructions for Ubuntu.
Optional: Enable NVIDIA Riva automatic speech recognition (ASR) and text to speech (TTS).
To launch a Riva server locally, refer to the Riva Quick Start Guide.
In the provided
config.shscript, setservice_enabled_asr=trueandservice_enabled_tts=true, and select the desired ASR and TTS languages by adding the appropriate language codes toasr_language_codeandtts_language_code.After the server is running, assign its IP address (or hostname) and port (50051 by default) to
RIVA_API_URIindeploy/compose/compose.env.
Alternatively, you can use a hosted Riva API endpoint. You might need to obtain an API key and/or Function ID for access.
In
deploy/compose/compose.env, make the following assignments as necessary:export RIVA_API_URI="<riva-api-address/hostname>:<port>" export RIVA_API_KEY="<riva-api-key>" export RIVA_FUNCTION_ID="<riva-function-id>"
Get an API Key for the Llama 2 70B API Endpoint
Perform the following steps if you do not already have an API key. You can use different model API endpoints with the same API key.
Navigate to https://build.ngc.nvidia.com/explore/reasoning.
Find the Llama 2 70B card and click the card.

Click Get API Key.
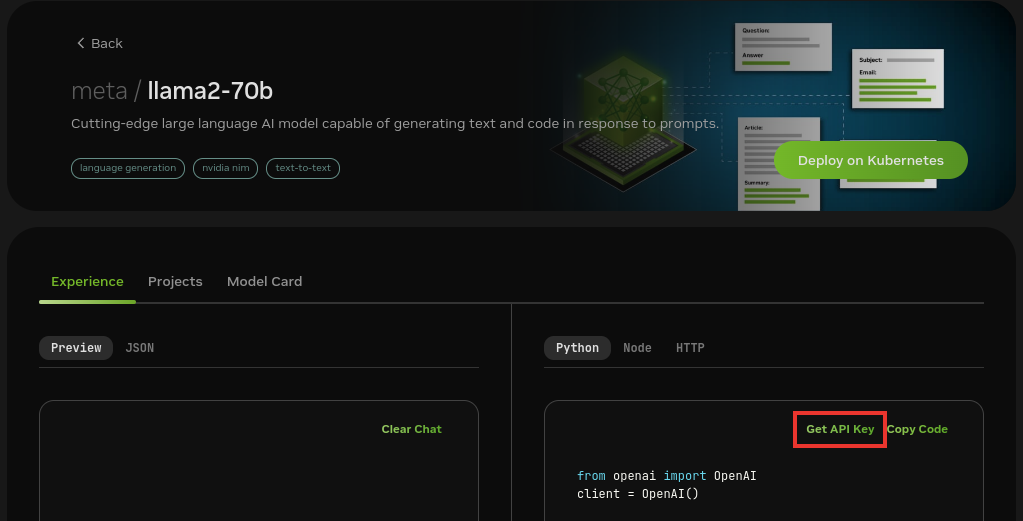
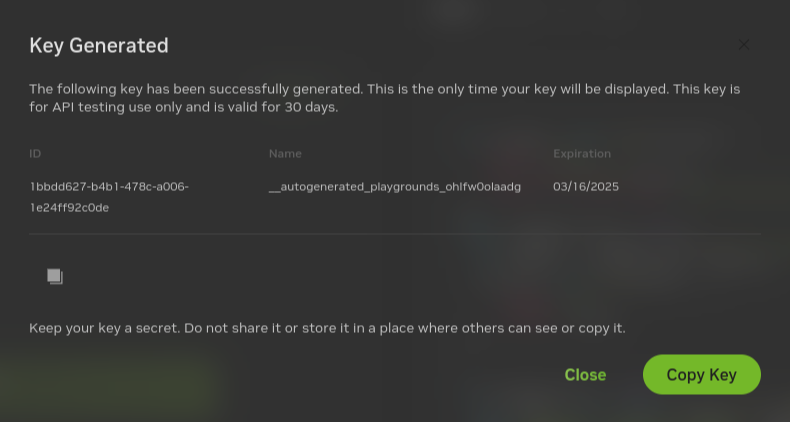
Click Generate Key.

Click Copy Key and then save the API key. The key begins with the letters nvapi-.
Build and Start the Containers
In the Generative AI examples repository, edit the
deploy/compose/compose.envfile.Add the API key for the model endpoint:
export NVIDIA_API_KEY="nvapi-..."
From the root of the repository, build the containers:
$ docker compose --env-file deploy/compose/compose.env -f deploy/compose/rag-app-multiturn-chatbot.yaml build
Start the containers:
$ docker compose --env-file deploy/compose/compose.env -f deploy/compose/rag-app-multiturn-chatbot.yaml up -d
Example Output
✔ Network nvidia-rag Created ✔ Container chain-server Started ✔ Container rag-playground Started
Start the Milvus vector database:
$ docker compose --env-file deploy/compose/compose.env -f deploy/compose/docker-compose-vectordb.yaml up -d milvus
Example Output
✔ Container milvus-minio Started ✔ Container milvus-etcd Started ✔ Container milvus-standalone Started
Confirm the containers are running:
$ docker ps --format "table {{.ID}}\t{{.Names}}\t{{.Status}}"
Example Output
CONTAINER ID NAMES STATUS f21cf089312a milvus-standalone Up 8 seconds 44189aa5836b milvus-minio Up 9 seconds (health: starting) 6024a6304e4b milvus-etcd Up 9 seconds (health: starting) 4656c2e7640e rag-playground Up 20 seconds 2e2e8f4decc9 chain-server Up 20 seconds
Next Steps
Access the web interface for the chat server. Refer to Using the Sample Chat Web Application for information about using the web interface.
Upload one or more PDF and .txt files to the knowledge base.
Enable the Use knowledge base checkbox when you submit a question.
Stop the containers by running
docker compose -f deploy/compose/rag-app-multiturn-chatbot.yaml downanddocker compose -f deploy/compose/docker-compose-vectordb.yaml down.