Multimodal Models from NVIDIA AI Endpoints with LangChain Agent
Prerequisites
To run this notebook, you need the following:
Performed the setup and generated an API key.
Installed Python dependencies from requirements.txt.
Installed additional packages for this notebook:
pip install gradio matplotlib scikit-image
This notebook covers the following custom plug-in components:
LLM using NVIDIA AI Endpoint mixtral_8x7b
A NVIDIA AI endpoint Deplot as one of the tool
A NVIDIA AI endpoint NeVa as one of the tool
Gradio as the simply User Interface where we will upload a few images
At the end of the day, as below illustrated, we would like to have a UI which allow user to upload image of their choice and have the agent choose tools to do visual reasoning.
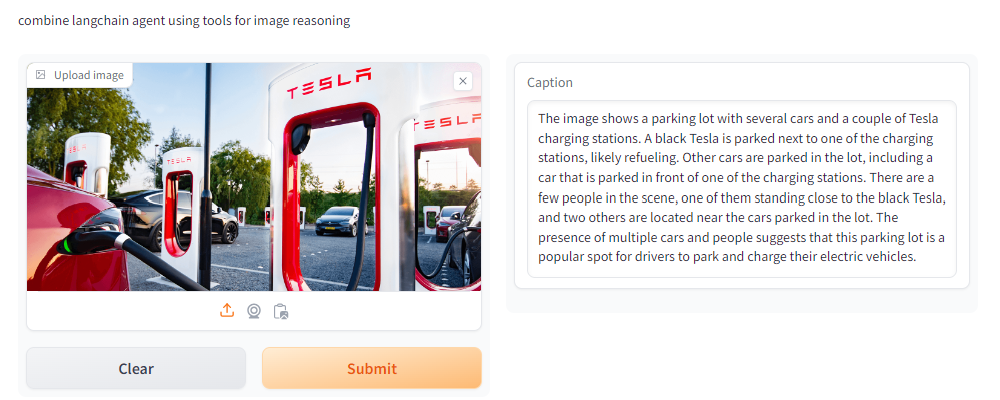
Note: As one can see, since we are using NVIDIA AI endpoints as an API, there is no further requirement in the prerequisites about GPUs as compute hardware
# uncomment the below to install additional python packages.
#!pip install unstructured
#!pip install matplotlib scikit-image
#!pip install gradio
Step 1 - Export the NVIDIA_API_KEY
You can supply the NVIDIA_API_KEY directly in this notebook when you run the cell below
import getpass
import os
## API Key can be found by going to NVIDIA NGC -> AI Foundation Models -> (some model) -> Get API Code or similar.
## 10K free queries to any endpoint (which is a lot actually).
# del os.environ['NVIDIA_API_KEY'] ## delete key and reset
if os.environ.get("NVIDIA_API_KEY", "").startswith("nvapi-"):
print("Valid NVIDIA_API_KEY already in environment. Delete to reset")
else:
nvapi_key = getpass.getpass("NVAPI Key (starts with nvapi-): ")
assert nvapi_key.startswith("nvapi-"), f"{nvapi_key[:5]}... is not a valid key"
os.environ["NVIDIA_API_KEY"] = nvapi_key
global nvapi_key
Step 2 - wrap the NeVa API call into a function and verify by supplying an image to get a respond
import openai, httpx, sys
import base64, io
from PIL import Image
def img2base64_string(img_path):
image = Image.open(img_path)
if image.width > 800 or image.height > 800:
image.thumbnail((800, 800))
buffered = io.BytesIO()
image.convert("RGB").save(buffered, format="JPEG", quality=85)
image_base64 = base64.b64encode(buffered.getvalue()).decode()
return image_base64
def nv_api_response(prompt, img_path):
base = "https://api.nvcf.nvidia.com"
url = "/v2/nvcf/pexec/functions/8bf70738-59b9-4e5f-bc87-7ab4203be7a0"
# Get your key at: https://catalog.ngc.nvidia.com/orgs/nvidia/teams/ai-foundation/models/neva-22b/api
# click on the "Generate Key" button
def hook(request):
request.url = httpx.URL(request.url, path=url)
request.headers['Accept'] = 'text/event-stream'
client = openai.OpenAI(
base_url=base,
api_key=nvapi_key,
http_client=httpx.Client(event_hooks={'request': [hook]})
)
base64_str=img2base64_string(img_path)
result = client.chat.completions.create(
model="neva-22b",
messages=[
{"role": "user", "content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": f"data:image/png;base64,{base64_str}"} # or image/jpeg
]
},
# {"role": "assistant", "labels": {'creativity': 0}} # Uncomment to get less verbose response
],
max_tokens=512, # Minimum 32, maximum 512. This is a bug.
temperature=0.2,
top_p=0.7,
stream=True # Use streaming mode for responses longer than 32 tokens.
)
for chunk in result:
print(chunk.choices[0].delta.content, end="")
sys.stdout.flush()
return result
fetch a test image of a pair of white sneakers and verify the function works
!wget "https://docs.google.com/uc?export=download&id=12ZpBBFkYu-jzz1iz356U5kMikn4uN9ww" -O ./toy_data/jordan.png
img_path="./toy_data/jordan.png"
prompt="describe the image"
out=nv_api_response(prompt,img_path)
Step 3 - we are gonna use mixtral_8x7b model as our main LLM
# test run and see that you can genreate a respond successfully
from langchain_nvidia_ai_endpoints import ChatNVIDIA
llm = ChatNVIDIA(model="mixtral_8x7b", nvidia_api_key=nvapi_key)
#Set up Prerequisites for Image Captioning App User Interface
import os
import io
import IPython.display
from PIL import Image
import base64
import requests
import gradio as gr
Step 4- wrap Deplot and Neva as tools for later usage
#Set up Prerequisites for Image Captioning App User Interface
import os
import io
import IPython.display
from PIL import Image
import base64
import requests
import gradio as gr
from langchain.tools import BaseTool
from transformers import BlipProcessor, BlipForConditionalGeneration, DetrImageProcessor, DetrForObjectDetection
from PIL import Image
import torch
#
import os
from tempfile import NamedTemporaryFile
from langchain.agents import initialize_agent
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
class ImageCaptionTool(BaseTool):
name = "Image captioner from NeVa"
description = "Use this tool when given the path to an image that you would like to be described. " \
"It will return a simple caption describing the image."
# generate api key via https://catalog.ngc.nvidia.com/orgs/nvidia/teams/ai-foundation/models/neva-22b/api
def img2base64_string(self,img_path):
print(img_path)
image = Image.open(img_path)
if image.width > 800 or image.height > 800:
image.thumbnail((800, 800))
buffered = io.BytesIO()
image.convert("RGB").save(buffered, format="JPEG", quality=85)
image_base64 = base64.b64encode(buffered.getvalue()).decode()
return image_base64
def _run(self, img_path):
invoke_url = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/8bf70738-59b9-4e5f-bc87-7ab4203be7a0"
fetch_url_format = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/status/"
headers = {
"Authorization": f"Bearer {nvapi_key}",
"Accept": "application/json",
}
base64_str = self.img2base64_string(img_path)
prompt = """\
can you summarize what is in the image\
and return the answer \
"""
payload = {
"messages":[
{"role": "user", "content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": f"data:image/png;base64,{base64_str}"} # or image/jpeg
]
},
{
"labels": {
"creativity": 6,
"helpfulness": 6,
"humor": 0,
"quality": 6
},
"role": "assistant"
} ],
"temperature": 0.2,
"top_p": 0.7,
"max_tokens": 512,
"stream": False
}
# re-use connections
session = requests.Session()
response = session.post(invoke_url, headers=headers, json=payload)
print(response)
while response.status_code == 202:
request_id = response.headers.get("NVCF-REQID")
fetch_url = fetch_url_format + request_id
response = session.get(fetch_url, headers=headers)
response.raise_for_status()
response_body = response.json()
print(response_body)
return response_body['choices'][0]['message']['content']
def _arun(self, query: str):
raise NotImplementedError("This tool does not support async")
class TabularPlotTool(BaseTool):
name = "Tabular Plot reasoning tool"
description = "Use this tool when given the path to an image that contain bar, pie chart objects. " \
"It will extract and return the tabular data "
def img2base64_string(self, img_path):
print(img_path)
image = Image.open(img_path)
if image.width > 800 or image.height > 800:
image.thumbnail((800, 800))
buffered = io.BytesIO()
image.convert("RGB").save(buffered, format="JPEG", quality=85)
image_base64 = base64.b64encode(buffered.getvalue()).decode()
return image_base64
def _run(self, img_path):
# using DePlot from NVIDIA AI Endpoint playground, generate your key via :https://catalog.ngc.nvidia.com/orgs/nvidia/teams/ai-foundation/models/deplot/api
invoke_url = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/3bc390c7-eeec-40f7-a64d-0c6a719985f7"
fetch_url_format = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/status/"
headers = {
"Authorization": f"Bearer {nvapi_key}",
"Accept": "application/json",
}
base64_str = self.img2base64_string(img_path)
prompt = """\
can you summarize what is in the image\
and return the answer \
"""
payload = {
"messages":[
{"role": "user", "content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": f"data:image/png;base64,{base64_str}"} # or image/jpeg
]
},
],
"temperature": 0.2,
"top_p": 0.7,
"max_tokens": 512,
"stream": False
}
# re-use connections
session = requests.Session()
response = session.post(invoke_url, headers=headers, json=payload)
while response.status_code == 202:
request_id = response.headers.get("NVCF-REQID")
fetch_url = fetch_url_format + request_id
response = session.get(fetch_url, headers=headers)
response.raise_for_status()
response_body = response.json()
print(response_body)
return response_body['choices'][0]['message']['content']
def _arun(self, query: str):
raise NotImplementedError("This tool does not support async")
Step 5 - initaite the agent with tools we previously defined
#initialize the gent
tools = [ImageCaptionTool(),TabularPlotTool()]
conversational_memory = ConversationBufferWindowMemory(
memory_key='chat_history',
k=5,
return_messages=True
)
agent = initialize_agent(
agent="chat-conversational-react-description",
tools=tools,
llm=llm,
max_iterations=5,
verbose=True,
memory=conversational_memory,
handle_parsing_errors=True,
early_stopping_method='generate'
)
Step 6 - verify the agent can indeed use the tools with the supplied image and query
user_question = "What is in this image?"
img_path="./toy_data/jordan.png"
response = agent.run(f'{user_question}, this is the image path: {img_path}')
print(response)
Step 7 - wrap the agent into a simple gradio UI so we can interactively upload arbitrary image
import gradio as gr
ImageCaptionApp = gr.Interface(fn=agent,
inputs=[gr.Image(label="Upload image", type="filepath")],
outputs=[gr.Textbox(label="Caption")],
title="Image Captioning with langchain agent",
description="combine langchain agent using tools for image reasoning",
allow_flagging="never")
ImageCaptionApp.launch(share=True)