Q&A with LangChain
This notebook demonstrates how to use LangChain to build a chatbot that references a custom knowledge-base.
Suppose you have some text documents (PDF, blog, Notion pages, etc.) and want to ask questions related to the contents of those documents. LLMs, given their proficiency in understanding text, are a great tool for this.
LangChain
LangChain provides a simple framework for connecting LLMs to your own data sources. Since LLMs are both only trained up to a fixed point in time and do not contain knowledge that is proprietary to an Enterprise, they can’t answer questions about new or proprietary knowledge. LangChain solves this problem.
⚠️ The notebook after this one, 03_llama_index_simple.ipynb, contains the same functionality as this notebook but uses LlamaIndex instead of LangChain. Ultimately, we recommend reading about LangChain vs. LlamaIndex and picking the software/components of the software that makes the most sense to you.
Step 1: Integrate TensorRT-LLM to LangChain (Connector)
from langchain_nvidia_trt.llms import TritonTensorRTLLM
# Connect to the TRT-LLM Llama-2 model running on the Triton server at the url below
# Replace "llm" with the url of the system where llama2 is hosted
triton_url = "llm:8001"
pload = {
'tokens':500,
'server_url': triton_url,
'model_name': "ensemble"
}
llm = TritonTensorRTLLM(**pload)
Note: Follow this step for nemotron models
In case you have deployed a trt-llm optimized nemotron model following steps here, execute the cell below by uncommenting the lines. Here we use a custom wrapper for talking with the model server.
# from triton_trt_llm import TensorRTLLM
# llm = TensorRTLLM(server_url ="llm:8000", model_name="ensemble", tokens=500, streaming=False)
Step 2: Create a Prompt Template (Model I/O)
A prompt template is a common paradigm in LLM development.
They are a pre-defined set of instructions provided to the LLM and guide the output produced by the model. They can contain few shot examples and guidance and are a quick way to engineer the responses from the LLM. Llama 2 accepts the prompt format shown in LLAMA_PROMPT_TEMPLATE, which we manipulate to be constructed with:
The system prompt
The context
The user’s question Langchain allows you to create custom wrappers for your LLM in case you want to use your own LLM or a different wrapper than the one that is supported in LangChain. Since we are using a custom Llama2 model hosted on Triton with TRT-LLM, we have written a custom wrapper for our LLM.
from langchain.prompts import PromptTemplate
LLAMA_PROMPT_TEMPLATE = (
"<s>[INST] <<SYS>>"
"Use the following context to answer the user's question. If you don't know the answer, just say that you don't know, don't try to make up an answer."
"<</SYS>>"
"<s>[INST] Context: {context} Question: {question} Only return the helpful answer below and nothing else. Helpful answer:[/INST]"
)
LLAMA_PROMPT = PromptTemplate.from_template(LLAMA_PROMPT_TEMPLATE)
Step 3: Load Documents (Retrieval)
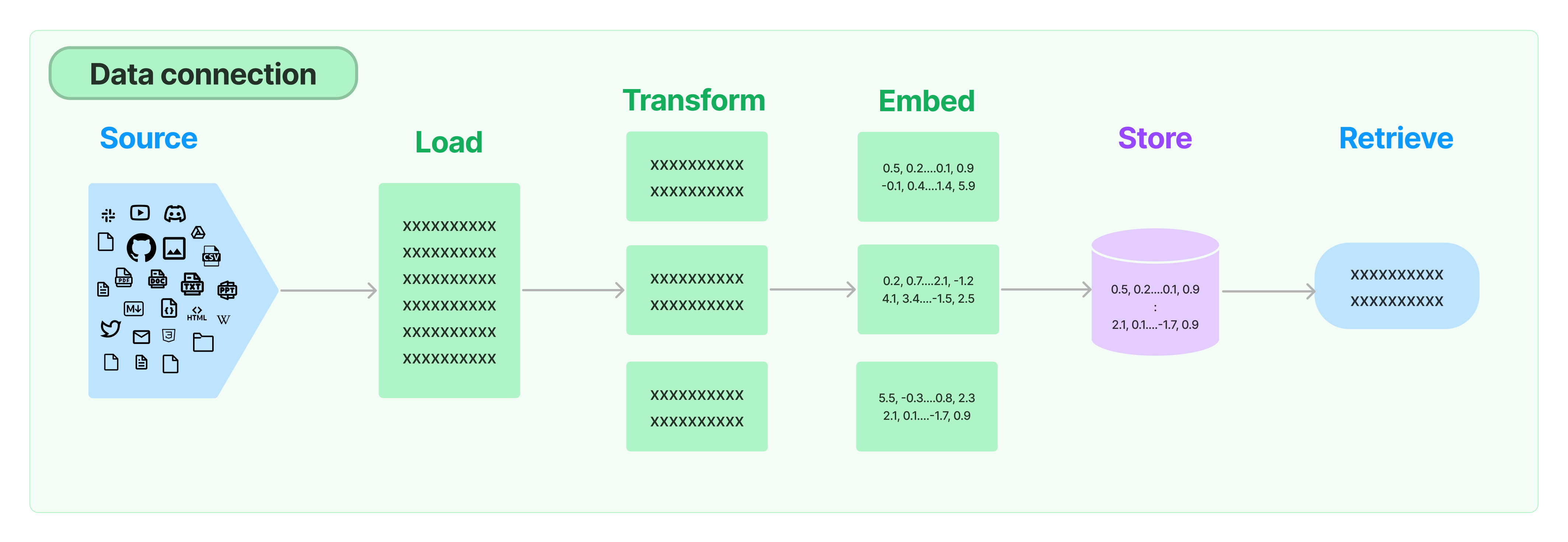
LangChain provides a variety of document loaders that load various types of documents (HTML, PDF, code) from many different sources and locations (private s3 buckets, public websites).
Document loaders load data from a source as Documents. A Document is a piece of text (the page_content) and associated metadata. Document loaders provide a load method for loading data as documents from a configured source.
In this example, we use a LangChain UnstructuredFileLoader to load a research paper about Llama2 from Meta.
Here are some of the other document loaders available from LangChain.
! wget -O "llama2_paper.pdf" -nc --user-agent="Mozilla" https://arxiv.org/pdf/2307.09288.pdf
from langchain.document_loaders import UnstructuredFileLoader
loader = UnstructuredFileLoader("llama2_paper.pdf")
data = loader.load()
Step 4: Transform Documents (Retrieval)
Once documents have been loaded, they are often transformed. One method of transformation is known as chunking, which breaks down large pieces of text, for example, a long document, into smaller segments. This technique is valuable because it helps optimize the relevance of the content returned from the vector database.
LangChain provides a variety of document transformers, such as text splitters. In this example, we use a SentenceTransformersTokenTextSplitter. The SentenceTransformersTokenTextSplitter is a specialized text splitter for use with the sentence-transformer models. The default behaviour is to split the text into chunks that fit the token window of the sentence transformer model that you would like to use. This sentence transformer model is used to generate the embeddings from documents.
There are some nuanced complexities to text splitting since semantically related text, in theory, should be kept together.
import time
from langchain.text_splitter import SentenceTransformersTokenTextSplitter
TEXT_SPLITTER_MODEL = "intfloat/e5-large-v2"
TEXT_SPLITTER_TOKENS_PER_CHUNK = 510
TEXT_SPLITTER_CHUNCK_OVERLAP = 200
text_splitter = SentenceTransformersTokenTextSplitter(
model_name=TEXT_SPLITTER_MODEL,
tokens_per_chunk=TEXT_SPLITTER_TOKENS_PER_CHUNK,
chunk_overlap=TEXT_SPLITTER_CHUNCK_OVERLAP,
)
start_time = time.time()
documents = text_splitter.split_documents(data)
print(f"--- {time.time() - start_time} seconds ---")
Let’s view a sample of content that is chunked together in the documents.
documents[40].page_content
Step 5: Generate Embeddings and Store Embeddings in the Vector Store (Retrieval)
a) Generate Embeddings
Embeddings for documents are created by vectorizing the document text; this vectorization captures the semantic meaning of the text. This allows you to quickly and efficiently find other pieces of text that are similar. The embedding model used below is intfloat/e5-large-v2.
LangChain provides a wide variety of embedding models from many providers and makes it simple to swap out the models.
When a user sends in their query, the query is also embedded using the same embedding model that was used to embed the documents. As explained earlier, this allows to find similar (relevant) documents to the user’s query.
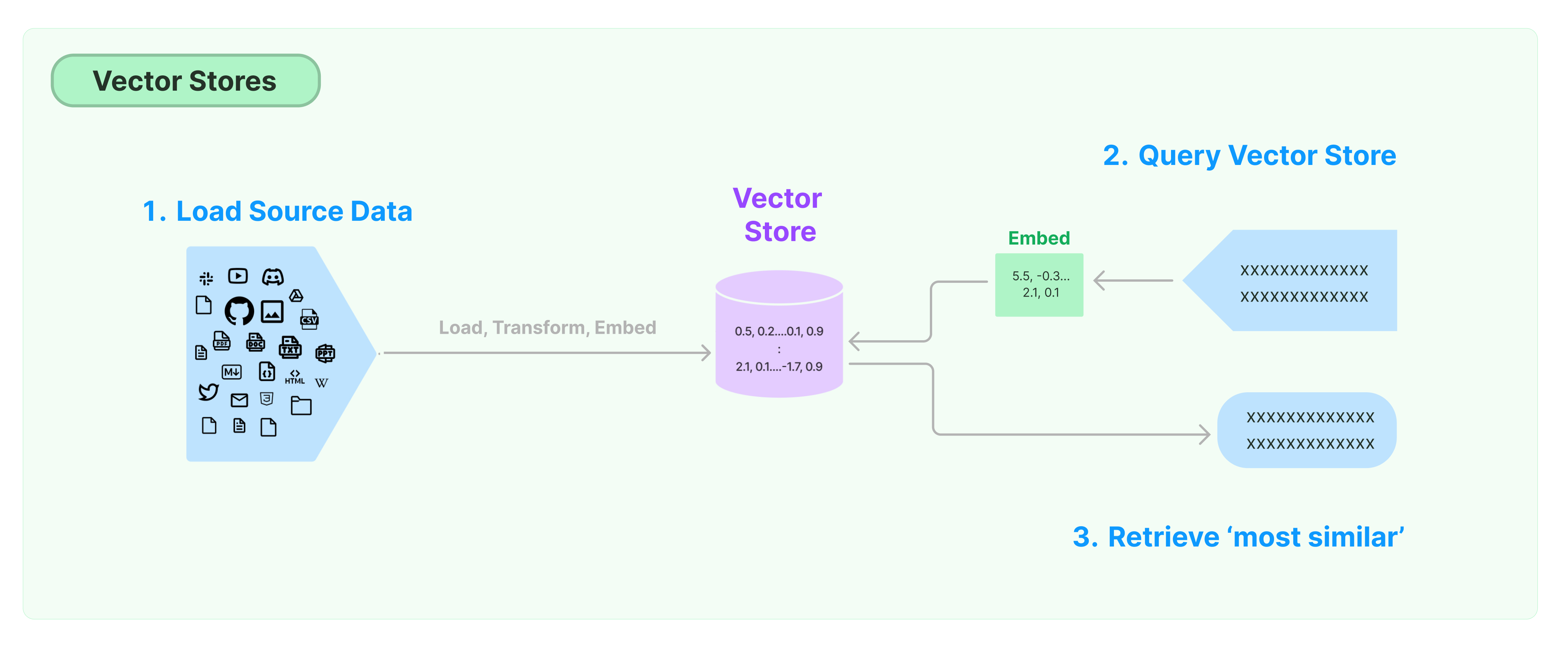
b) Store Document Embeddings in the Vector Store
Once the document embeddings are generated, they are stored in a vector store so that at query time we can:
Embed the user query and
Retrieve the embedding vectors that are most similar to the embedding query.
A vector store takes care of storing the embedded data and performing a vector search.
LangChain provides support for a great selection of vector stores.
⚠️ For this workflow, Milvus vector database is running as a microservice.
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Milvus
import torch
import time
#Running the model on CPU as we want to conserve gpu memory.
#In the production deployment (API server shown as part of the 5th notebook we run the model on GPU)
model_name = "intfloat/e5-large-v2"
model_kwargs = {"device": "cpu"}
encode_kwargs = {"normalize_embeddings": False}
hf_embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)
start_time = time.time()
vectorstore = Milvus.from_documents(documents=documents, embedding=hf_embeddings, connection_args={"host": "milvus", "port": "19530"})
print(f"--- {time.time() - start_time} seconds ---")
# Simple Example: Retrieve Documents from the Vector Database
# note: this is just for demonstration purposes of a similarity search
question = "Can you talk about safety evaluation of llama2 chat?"
docs = vectorstore.similarity_search(question)
print(docs[2].page_content)
Simple Example: Retrieve Documents from the Vector Database (Retrieval)
Given a user query, relevant splits for the question are returned through a similarity search. This is also known as a semantic search, and it is done with meaning. It is different from a lexical search, where the search engine looks for literal matches of the query words or variants of them, without understanding the overall meaning of the query. A semantic search tends to generate more relevant results than a lexical search.
Step 6: Compose a streamed answer using a Chain
We have already integrated the Llama2 TRT LLM with the help of LangChain connector, loaded and transformed documents, and generated and stored document embeddings in a vector database. To finish the pipeline, we need to add a few more LangChain components and combine all the components together with a chain.
A LangChain chain combines components together. In this case, we use Langchain Expression Language to build a chain.
We formulate the prompt placeholders (context and question) and pipe it to our trt-llm connector as shown below and finally stream the result.
from langchain_core.runnables import RunnablePassthrough
import time
chain = (
{"context": vectorstore.as_retriever(), "question": RunnablePassthrough()}
| LLAMA_PROMPT
| llm
)
start_time = time.time()
for token in chain.stream(question):
print(token, end="", flush=True)
print(f"\n--- {time.time() - start_time} seconds ---")