LangChain with Local Llama 2 Model
This notebook uses the checkpoint from the HuggingFace Llama-2-13b-chat-hf model.
⚠️ The notebook before this one, 07_Option(1)_NVIDIA_AI_endpoint_simple.ipynb, contains the same exercise as this notebook but uses NVIDIA AI endpoints’ models via API calls instead of loading the models’ checkpoints pulled from huggingface model hub, and then load from host to devices (i.e GPUs).
Noted that, since we will load the checkpoints, it will be significantly slower to go through this entire notebook.
If you do decide to go through this notebook, please kindly check the Prerequisite section below.
Prerequisite
To run this notebook, you need the following:
Prior approval to use the checkpoints by applying for access to the meta-llama model.
At least 2 NVIDIA GPUs, each with at least 32G mem, preferably using Ampere architecture.
Installed Docker and nvidia-container-toolkit.
Registered with NVIDIA NGC and can pull and run NGC PyTorch containers.
Installed Python dependencies for this notebook, by overwriting langchain-core version:
pip install langchain-core==0.1.15
If you are using the Dockerfile.gpu_notebook, the dependency is already installed for you.
The notebook will walk you through how to build an end-to-end RAG pipeline using LangChain, faiss as the vectorstore and a custom llm of your choice from huggingface ( more specifically, we will be using HuggingFace Llama-2-13b-chat-hf in this notebook, but the process is similar for other llms from huggingface.
Generically speaking, the RAG pipeline will involve 2 phases -
The first one is the preprocessing phase illustrated below -
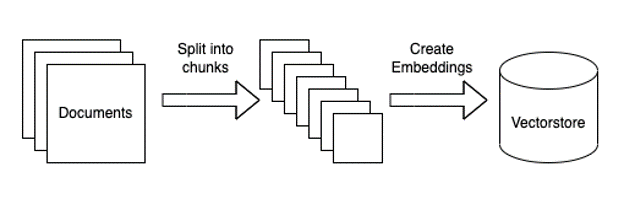
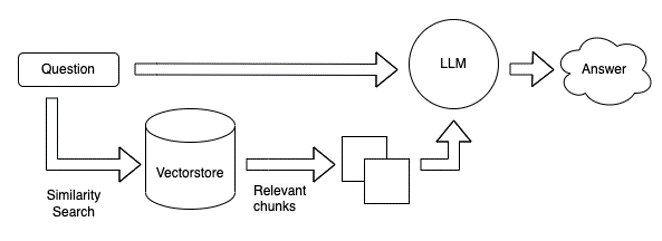
The second phase is the inference runtime -
!pip install langchain-core==0.1.15 faiss-gpu
Let’s now go through this notebook step-by-step
For the first phase, reminder of the flow
Step 1 - Load huggingface embedding
### load custom embedding and use it in Faiss
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
from langchain.embeddings import HuggingFaceEmbeddings
embedding_model_name = "sentence-transformers/all-mpnet-base-v2" # sentence-transformer is the most commonly used embedding
emd_model_kwargs = {"device": "cuda"}
hf_embedding = HuggingFaceEmbeddings(model_name=embedding_model_name, model_kwargs=emd_model_kwargs)
Step 2 - Prepare the toy text dataset
We will prepare the XXX.txt files ( there should be Sweden.txt and and using the above embedding to parse chuck of text and store them into faiss-gpu vectorstore
Let’s have a look at text datasets
%%bash
head -1 ./toy_data/Sweden.txt
%%bash
head -3 ./toy_data/Titanic_film.txt
Step 3 - Process the document into faiss vectorstore and save to disk
import os
from tqdm import tqdm
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.text_splitter import CharacterTextSplitter
from pathlib import Path
from langchain.text_splitter import CharacterTextSplitter
import faiss
from langchain.vectorstores import FAISS,utils
import pickle
# Here we read in the text data and prepare them into vectorstore
ps = list(Path("./toy_data/").glob('**/*.txt'))
print(ps)
data = []
sources = []
for p in ps:
with open(p,encoding="utf-8") as f:
data.append(f.read())
sources.append(p)
# We do this due to the context limits of the LLMs.
# Here we split the documents, as needed, into smaller chunks.
# We do this due to the context limits of the LLMs.
text_splitter = CharacterTextSplitter(chunk_size=200, separator="\n")
docs = []
metadatas = []
for i, d in enumerate(data):
splits = text_splitter.split_text(d)
docs.extend(splits)
metadatas.extend([{"source": sources[i]}] * len(splits))
# Here we create a vector store from the documents and save it to disk.
store = FAISS.from_texts(docs, hf_embedding, metadatas=metadatas)
faiss.write_index(store.index, "./toy_data/hf_embedding_docs.index")
store.index = None
with open("./toy_data/hf_embeddingfaiss_store.pkl", "wb") as f:
pickle.dump(store, f)
# you will only need to do this once, later on we will restore the already saved vectorstore
Step 4 - Reload the already saved vectorstore and prepare for retrival
# Load the LangChain.
from pathlib import Path
from langchain.text_splitter import CharacterTextSplitter
import faiss
from langchain.vectorstores import FAISS
import pickle
index = faiss.read_index("./toy_data/hf_embedding_docs.index")
with open("./toy_data/hf_embeddingfaiss_store.pkl", "rb") as f:
store = pickle.load(f)
store.index = index
Step 5 - Prepare the loaded vectorstore into a retriver
retriever = store.as_retriever(search_type='similarity', search_kwargs={"k": 3}) # k is a hyperparameter, usally by default set to 3
Now we are finally done with the preprocessing step, next we will proceed to phase 2
Recall phase 2 involve a runtime which we could query the already loaded faiss vectorstore.
Step 6 - Load the HuggingFace Llama-2-13b-chat-hf to your GPUs
Note: Scroll down and make sure you supply the hf_token in code block below [FILL_IN] your huggingface token , for how to generate the token from huggingface, please following instruction from this link
Note: The execution of cell below will take up sometime, please be patient until the checkpoint is fully loaded. Alternatively, turn to previous notebook 07_Option(1)_NVIDIA_AI_endpoint_simply.ipynb if you wish to use already deployed models as API calls instead.
import torch
import torch
import transformers
from langchain import HuggingFacePipeline
from transformers import (
AutoConfig,
AutoModel,
AutoModelForCausalLM,
AutoTokenizer,
GenerationConfig,
LlamaForCausalLM,
LlamaTokenizer,
pipeline,
)
def load_model(model_name_or_path, device, num_gpus, hf_auth_token=None, debug=False):
"""Load an HF locally saved checkpoint."""
if device == "cpu":
kwargs = {}
elif device == "cuda":
kwargs = {"torch_dtype": torch.float16}
if num_gpus == "auto":
kwargs["device_map"] = "auto"
else:
num_gpus = int(num_gpus)
if num_gpus != 1:
kwargs.update(
{
"device_map": "auto",
"max_memory": {i: "20GiB" for i in range(num_gpus)},
}
)
elif device == "mps":
kwargs = {"torch_dtype": torch.float16}
# Avoid bugs in mps backend by not using in-place operations.
print("mps not supported")
else:
raise ValueError(f"Invalid device: {device}")
if hf_auth_token is None:
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path, low_cpu_mem_usage=True, **kwargs
)
else:
tokenizer = AutoTokenizer.from_pretrained(
model_name_or_path, use_auth_token=hf_auth_token, use_fast=False
)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
use_auth_token=hf_auth_token,
**kwargs,
)
if device == "cuda" and num_gpus == 1:
model.to(device)
if debug:
print(model)
return model, tokenizer
model_name="meta-llama/Llama-2-13b-chat-hf"
device = "cuda"
num_gpus = 2 ## minimal requirement is that you have 2x NVIDIA GPUs
## Remember to supply your own huggingface access token
hf_token= "[FILL_IN]"
model, tokenizer = load_model(model_name, device, num_gpus,hf_auth_token=hf_token, debug=False)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=256,
temperature=0.1,
do_sample=True,
)
hf_llm = HuggingFacePipeline(pipeline=pipe)
Step 7 - Supply the hf_llm as well as the retriver we prepared above into langchain’s RetrievalQA chain
# create the using RetrievalQA
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm=hf_llm, # supply meta llama2 model
chain_type="stuff",
retriever=retriever, # using our own retriever
return_source_documents=True)
Step 8 - We are now ready to ask questions
query = "When is the film Titanic being made ?"
#query ="Who is the director for the film?"
llm_response = qa_chain(query)
print("llm response after retrieve from KB, the answer is :\n")
print(llm_response['result'])
print("---"*10)
print("source paragraph >> ")
llm_response['source_documents'][0].page_content