Multi-GPU Workflows¶
There are many backends available with CUDA-Q that enable seamless switching between GPUs, QPUs and CPUs and also allow for workflows involving multiple architectures working in tandem. This page will walk through the simple steps to accelerate any quantum circuit simulation with a GPU and how to scale large simulations using multi-GPU multi-node capabilities.
From CPU to GPU¶
The code below defines a kernel that creates a GHZ state using \(N\) qubits.
import cudaq
@cudaq.kernel
def ghz_state(qubit_count: int):
qubits = cudaq.qvector(qubit_count)
h(qubits[0])
for i in range(1, qubit_count):
cx(qubits[0], qubits[i])
mz(qubits)
def sample_ghz_state(qubit_count, target):
"""A function that will sample a variable sized GHZ state."""
cudaq.set_target(target)
result = cudaq.sample(ghz_state, qubit_count, shots_count=1000)
return result
You can run a state vector simulation using your CPU with the qpp-cpu backend. This is helpful for debugging code and testing small circuits.
cpu_result = sample_ghz_state(qubit_count=2, target="qpp-cpu")
cpu_result.dump()
{ 00:475 11:525 }
As the number of qubits increases to even modest size, the CPU simulation will become impractically slow. By switching to the nvidia backend, you can accelerate the same code on a single GPU and achieve a speedup of up to 425x. If you have a GPU available, this the default backend to ensure maximum productivity.
if cudaq.num_available_gpus() > 0:
gpu_result = sample_ghz_state(qubit_count=25, target="nvidia")
gpu_result.dump()
{ 0000000000000000000000000:510 1111111111111111111111111:490 }
Pooling the memory of multiple GPUs (mgpu)¶
As N gets larger, the size of the state vector that needs to be stored in memory increases exponentially.
The state vector has \(2^N\) elements, each a complex number requiring 8 bytes. This means a 30 qubit simulation
requires roughly 8 GB. Adding a few more qubits will quickly exceed the memory of as single GPU. The mqpu backend
solved this problem by pooling the memory of multiple GPUs across multiple nodes to perform a single state vector simulation.

If you have multiple GPUs, you can use the following command to run the simulation across \(n\) GPUs.
mpiexec -np n python3 program.py --target nvidia --target-option mgpu
This code will execute in an MPI context and provide additional memory to simulation much larger state vectors.
You can also set cudaq.set_target('nvidia', option='mgpu') within the file to select the target.
Parallel execution over multiple QPUs (mqpu)¶
Batching Hamiltonian Terms¶
Multiple GPUs can also come in handy for cases where applications might benefit from multiple QPUs running in parallel. The mqpu backend uses multiple GPUs to simulate QPUs so you can accelerate quantum applications with parallelization.

The most simple example is Hamiltonian Batching. In this case, an expectation value of a large Hamiltonian is distributed across multiple simulated QPUs, where each QPUs evaluates a subset of the Hamiltonian terms.
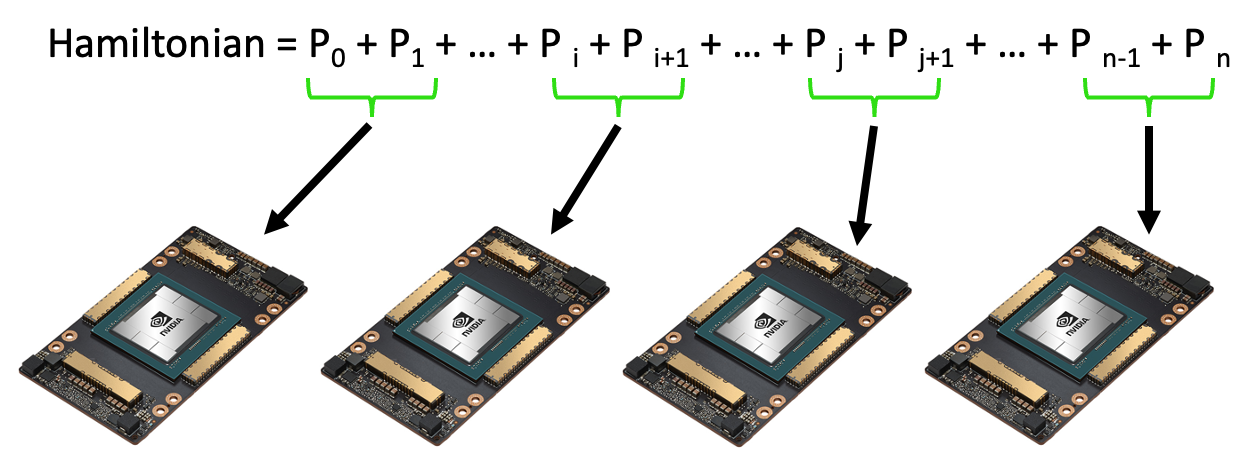
The code below evaluates the expectation value of a random 100000 term Hamiltonian. A standard observe call will run the program on a single GPU. Adding the argument execution=cudaq.parallel.thread or execution=cudaq.parallel.mpi will automatically distribute the Hamiltonian terms across multiple GPUs on a single node or multiple GPUs on multiple nodes, respectively.
The code is executed with mpiexec -np n python3 program.py --target nvidia --target-option mqpu where \(n\) is the number of GPUs available.
import cudaq
from cudaq import spin
if cudaq.num_available_gpus() == 0:
print("This example requires a GPU to run. No GPU detected.")
exit(0)
cudaq.set_target("nvidia", option="mqpu")
cudaq.mpi.initialize()
qubit_count = 15
term_count = 100000
@cudaq.kernel
def kernel(n_qubits: int):
qubits = cudaq.qvector(n_qubits)
h(qubits[0])
for i in range(1, n_qubits):
x.ctrl(qubits[0], qubits[i])
# Create a random Hamiltonian
hamiltonian = cudaq.SpinOperator.random(qubit_count, term_count)
# The observe calls allows calculation of the the expectation value of the Hamiltonian with respect to a specified kernel.
# Single node, single GPU.
result = cudaq.observe(kernel, hamiltonian, qubit_count)
result.expectation()
# If multiple GPUs/ QPUs are available, the computation can parallelize with the addition of an argument in the observe call.
# Single node, multi-GPU.
result = cudaq.observe(kernel,
hamiltonian,
qubit_count,
execution=cudaq.parallel.thread)
result.expectation()
# Multi-node, multi-GPU.
result = cudaq.observe(kernel,
hamiltonian,
qubit_count,
execution=cudaq.parallel.mpi)
result.expectation()
cudaq.mpi.finalize()
Circuit Batching¶
A second way to leverage the mqpu backend is to batch circuit evaluations across multiple simulated QPUs.
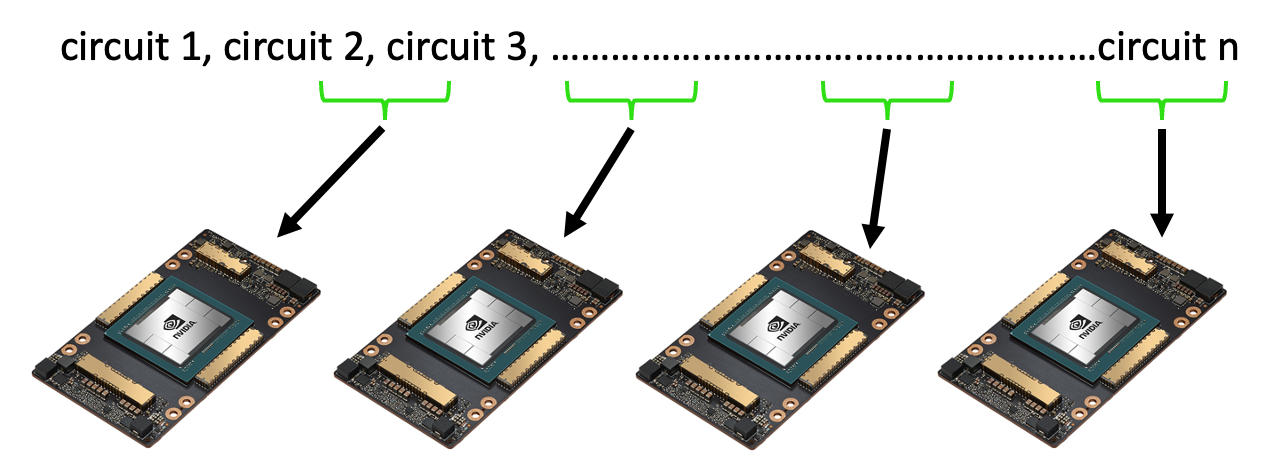
One example where circuit batching is helpful might be evaluating a parameterized circuit many times with different parameters. The code below prepares a list of 10000 parameter sets for a 5 qubit circuit.
import cudaq
from cudaq import spin
import numpy as np
if cudaq.num_available_gpus() == 0:
print("This example requires a GPU to run. No GPU detected.")
exit(0)
np.random.seed(1)
cudaq.set_target("nvidia")
qubit_count = 5
sample_count = 10000
h = spin.z(0)
parameter_count = qubit_count
# prepare 10000 different input parameter sets.
parameters = np.random.default_rng(13).uniform(low=0,
high=1,
size=(sample_count,
parameter_count))
@cudaq.kernel
def kernel(params: list[float]):
qubits = cudaq.qvector(5)
for i in range(5):
rx(params[i], qubits[i])
All of these circuits can be broadcast through a single :code”observe call and run by default on a single GPU. The code below times this entire process.
import time
start_time = time.time()
cudaq.observe(kernel, h, parameters)
end_time = time.time()
print(end_time - start_time)
3.185340642929077
This can be greatly accelerated by batching the circuits on multiple QPUs. The first step is to slice the large list of parameters unto smaller arrays. The example below divides by four, in preparation to run on four GPUs.
print('There are', parameters.shape[0], 'parameter sets to execute')
xi = np.split(
parameters,
4) # Split the parameters into 4 arrays since 4 GPUs are available.
print('Split parameters into', len(xi), 'batches of', xi[0].shape[0], ',',
xi[1].shape[0], ',', xi[2].shape[0], ',', xi[3].shape[0])
There are now 10000 parameter sets split into 4 batches of 2500 , 2500 , 2500 , 2500
As the results are run asynchronously, they need to be stored in a list (asyncresults) and retrieved later with the get command. The following loops over the parameter batches, and the sets of parameters in each batch. The parameter sets are provided as inputs to observe_async along with specification of a qpu_id which designates the GPU (of the four available) which will run computation. A speedup of up to 4x can be expected with results varying by problem size.
# Timing the execution on a single GPU vs 4 GPUs,
# one will see a nearly 4x performance improvement if 4 GPUs are available.
cudaq.set_target("nvidia", option="mqpu")
asyncresults = []
num_gpus = cudaq.num_available_gpus()
start_time = time.time()
for i in range(len(xi)):
for j in range(xi[i].shape[0]):
qpu_id = i * num_gpus // len(xi)
asyncresults.append(
cudaq.observe_async(kernel, h, xi[i][j, :], qpu_id=qpu_id))
result = [res.get() for res in asyncresults]
end_time = time.time()
print(end_time - start_time)
1.1754660606384277