Working with the CUDA-Q IR¶
Let’s see the output of nvq++ in verbose mode. Consider a simple code like the one below, saved to file simple.cpp.
#include <cudaq.h>
struct ghz {
void operator()(int N) __qpu__ {
cudaq::qvector q(N);
h(q[0]);
for (int i = 0; i < N - 1; i++) {
x<cudaq::ctrl>(q[i], q[i + 1]);
}
mz(q);
}
};
int main() { ... }
We see the following output from :code:`nvq++` verbose mode (up to some absolute paths).
$ nvq++ simple.cpp -v -save-temps
cudaq-quake --emit-llvm-file simple.cpp -o simple.qke
cudaq-opt --pass-pipeline=builtin.module(canonicalize,lambda-lifting,canonicalize,apply-op-specialization,kernel-execution,indirect-to-direct-calls,inline,func.func(quake-add-metadata),device-code-loader{use-quake=1},expand-measurements),lower-to-cfg,func.func(canonicalize,cse)) simple.qke -o simple.qke.LpsXpu
cudaq-translate --convert-to=qir simple.qke.LpsXpu -o simple.ll.p3De4L
fixup-linkage.pl simple.qke simple.ll
llc --relocation-model=pic --filetype=obj -O2 simple.ll.p3De4L -o simple.qke.o
llc --relocation-model=pic --filetype=obj -O2 simple.ll -o simple.classic.o
clang++ -L/usr/lib/gcc/x86_64-linux-gnu/12 -L/usr/lib64 -L/lib/x86_64-linux-gnu -L/lib64 -L/usr/lib/x86_64-linux-gnu -L/lib -L/usr/lib -L/usr/local/cuda/lib64/stubs -r simple.qke.o simple.classic.o -o simple.o
clang++ -Wl,-rpath,lib -Llib -L/usr/lib/gcc/x86_64-linux-gnu/12 -L/usr/lib64 -L/lib/x86_64-linux-gnu -L/lib64 -L/usr/lib/x86_64-linux-gnu -L/lib -L/usr/lib -L/usr/local/cuda/lib64/stubs simple.o -lcudaq -lcudaq-common -lcudaq-mlir-runtime -lcudaq-builder -lcudaq-ensmallen -lcudaq-nlopt -lcudaq-operator -lcudaq-em-default -lcudaq-platform-default -lnvqir -lnvqir-qpp
This workflow orchestration is represented in the figure below:
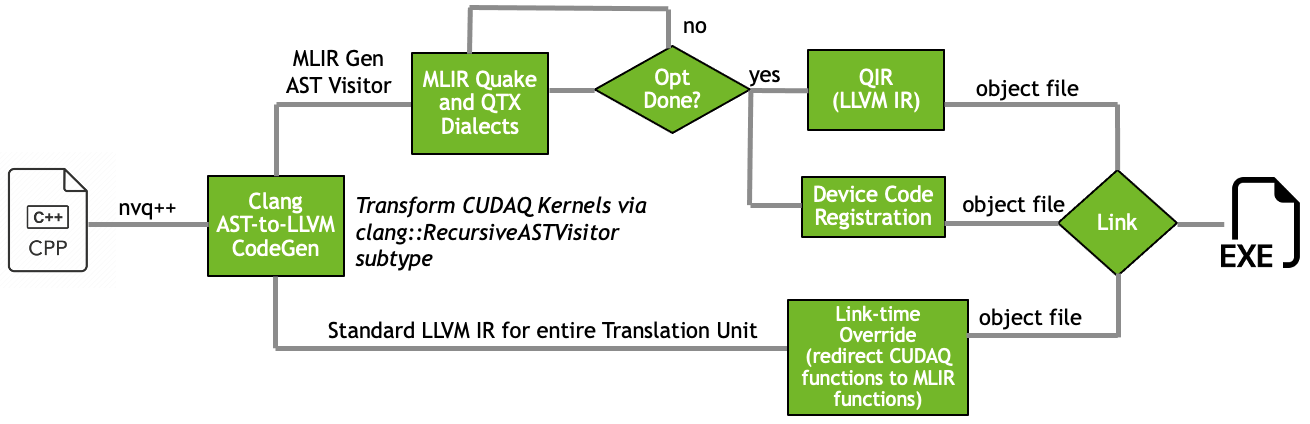
We start by mapping CUDA-Q C++ kernel representations (structs, lambdas, and free functions)
to the Quake dialect. Since we added -save-temps,
we can look at the IR code that was produced. The base Quake file, simple.qke, contains the following:
module attributes {qtx.mangled_name_map = {__nvqpp__mlirgen__ghz = "_ZN3ghzclEi"}} {
func.func @__nvqpp__mlirgen__ghz(%arg0: i32) attributes {"cudaq-entrypoint", "cudaq-kernel"} {
%alloca = memref.alloca() : memref<i32>
memref.store %arg0, %alloca[] : memref<i32>
%0 = memref.load %alloca[] : memref<i32>
%1 = arith.extsi %0 : i32 to i64
%2 = quake.alloca(%1 : i64) !quake.veq<?>
%c0_i32 = arith.constant 0 : i32
%3 = arith.extsi %c0_i32 : i32 to i64
%4 = quake.extract_ref %2[%3] : (!quake.veq<?>, i64) -> !quake.ref
quake.h %4 : (!quake.ref) -> ()
cc.scope {
%c0_i32_0 = arith.constant 0 : i32
%alloca_1 = memref.alloca() : memref<i32>
memref.store %c0_i32_0, %alloca_1[] : memref<i32>
cc.loop while {
%6 = memref.load %alloca_1[] : memref<i32>
%7 = memref.load %alloca[] : memref<i32>
%c1_i32 = arith.constant 1 : i32
%8 = arith.subi %7, %c1_i32 : i32
%9 = arith.cmpi slt, %6, %8 : i32
cc.condition %9
} do {
cc.scope {
%6 = memref.load %alloca_1[] : memref<i32>
%7 = arith.extsi %6 : i32 to i64
%8 = quake.extract_ref %2[%7] : (!quake.veq<?>, i64) -> !quake.ref
%9 = memref.load %alloca_1[] : memref<i32>
%c1_i32 = arith.constant 1 : i32
%10 = arith.addi %9, %c1_i32 : i32
%11 = arith.extsi %10 : i32 to i64
%12 = quake.extract_ref %2[%11] : (!quake.veq<?>, i64) -> !quake.ref
quake.x [%8] %12 : (!quake.ref, !quake.ref) -> ()
}
cc.continue
} step {
%6 = memref.load %alloca_1[] : memref<i32>
%c1_i32 = arith.constant 1 : i32
%7 = arith.addi %6, %c1_i32 : i32
memref.store %7, %alloca_1[] : memref<i32>
}
}
%5 = quake.mz %2 : (!quake.veq<?>) -> !cc.stdvec<i1>
return
}
}
This base Quake file is unoptimized and unchanged. It is produced by the
cudaq-quake tool, which also allows us to output the full LLVM IR representation
for the code. This LLVM IR is classical-only, and is directly produced by clang++
code-generation. The LLVM IR file simple.ll contains the CUDA-Q kernel
operator()(Args...) LLVM function, with a mangled name. Ultimately, we
want to replace this function with our own MLIR-generated function.
Next, the cudaq-opt tool is invoked on the simple.qke file. This runs an
MLIR pass pipeline that canonicalizes and optimizes the code. It will also process quantum
lambdas, lift those lambdas to functions, and synthesis adjoint and controlled versions of
CUDA-Q kernel functions if necessary. The most important pass that this step applies is the
kernel-execution pass, which synthesizes a new entry point LLVM function with the
same name and signature as the original operator()(Args...) call function in the
classical simple.ll file. We also extract all Quake code representations as strings
and register them with the CUDA-Q runtime for runtime IR introspection.
After cudaq-opt, the cudaq-translate tool is used to lower the transformed
Quake representation to an LLVM IR representation, specifically the QIR. We finish by lowering
this representation to object code via standard LLVM tools (e.g. llc), and merge all
object files into a single object file, ensuring that our new mangled operator()(Args...)
call is injected first, thereby overwriting the original. Finally, based on user compile flags,
we configure the link line with specific libraries that implement the quantum_platform
(here the libcudaq-platform-default.so) and NVQIR circuit simulator backend (the
libnvqir-qpp.so Q++ CPU-only simulation backend). These latter libraries are controlled
via the --platform and --target compiler flags.
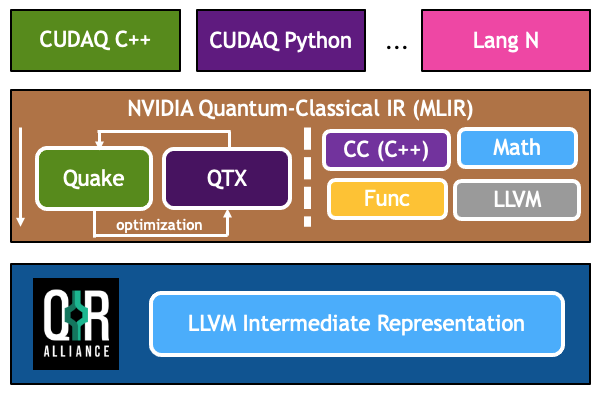
The above figure demonstrate the MLIR dialects involved and the overall workflow mapping high-level language constructs to lower-level MLIR dialect code, and ultimately LLVM IR.
CUDA-Q also provides value-semantics form of Quake for static circuit representation. This dialect directly enables robust circuit optimizations via data-flow analysis of the representative circuit. This dialect is typically produced just-in-time when the structure of the circuit is fully known.
You will notice that there are a number of CUDA-Q executable tools installed as part
of this open beta release. These tools are directly related to the generation,
processing, optimization, and lowering of the core nvq++ compiler representations.
The tools available are
cudaq-quake- Lower C++ to Quake, can also output classical LLVM IR filecudaq-opt- Process Quake with various MLIR Passescudaq-translate- Lower Quake to external representations like QIR
CUDA-Q and nvq++ rely on Quake for the core quantum intermediate representation.
Quake represents an IR closer to the CUDA-Q source language and models qubits and
quantum instructions via memory semantics. Quake can be fully dynamic and in
that sense represents a quantum circuit template or generator. With runtime
arguments fully specified, Quake code can be used to generate or synthesize
a fully known quantum circuit. The value semantics form of Quake can thus be
used as a representation for fully known
or synthesized quantum circuits. Its utility, therefore, lies in its ability to
optimize quantum code. It departs from the memory semantics model of Quake and
expresses the flow of quantum information explicitly as MLIR values.
This approach makes it easier for finding circuit patterns and leveraging it for common
optimization tasks.
To demonstrate how these tools work together, let’s take the simple GHZ CUDA-Q program and lower the kernel from C++ to Quake, synthesize that Quake code, and produce QIR. Recall the code snippet for the kernel
// Define a quantum kernel
struct ghz {
auto operator()() __qpu__ {
cudaq::qarray<5> q;
h(q[0]);
for (int i = 0; i < 4; i++)
x<cudaq::ctrl>(q[i], q[i + 1]);
mz(q);
}
};
Using the toolchain, we can lower this directly to QIR,
cudaq-quake simple.cpp | cudaq-opt --canonicalize | cudaq-translate --convert-to=qir
which prints:
; ModuleID = 'LLVMDialectModule'
source_filename = "LLVMDialectModule"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
define void @__nvqpp__mlirgen__ghz() local_unnamed_addr {
%1 = tail call ptr @__quantum__rt__qubit_allocate_array(i64 5)
%2 = tail call ptr @__quantum__rt__array_get_element_ptr_1d(ptr %1, i64 0)
%3 = load ptr, ptr %2, align 8
tail call void @__quantum__qis__h(ptr %3)
%4 = tail call ptr @__quantum__rt__array_get_element_ptr_1d(ptr %1, i64 1)
%5 = load ptr, ptr %4, align 8
tail call void (i64, i64, i64, i64, ptr, ...) @generalizedInvokeWithRotationsControlsTargets(i64 0, i64 0, i64 1, i64 1, ptr nonnull @__quantum__qis__x__ctl, ptr %3, ptr %5)
%6 = tail call ptr @__quantum__rt__array_get_element_ptr_1d(ptr %1, i64 2)
%7 = load ptr, ptr %6, align 8
tail call void (i64, i64, i64, i64, ptr, ...) @generalizedInvokeWithRotationsControlsTargets(i64 0, i64 0, i64 1, i64 1, ptr nonnull @__quantum__qis__x__ctl, ptr %5, ptr %7)
%8 = tail call ptr @__quantum__rt__array_get_element_ptr_1d(ptr %1, i64 3)
%9 = load ptr, ptr %8, align 8
tail call void (i64, i64, i64, i64, ptr, ...) @generalizedInvokeWithRotationsControlsTargets(i64 0, i64 0, i64 1, i64 1, ptr nonnull @__quantum__qis__x__ctl, ptr %7, ptr %9)
%10 = tail call ptr @__quantum__rt__array_get_element_ptr_1d(ptr %1, i64 4)
%11 = load ptr, ptr %10, align 8
tail call void (i64, i64, i64, i64, ptr, ...) @generalizedInvokeWithRotationsControlsTargets(i64 0, i64 0, i64 1, i64 1, ptr nonnull @__quantum__qis__x__ctl, ptr %9, ptr %11)
%12 = tail call ptr @__quantum__qis__mz(ptr %3)
%13 = tail call ptr @__quantum__qis__mz(ptr %5)
%14 = tail call ptr @__quantum__qis__mz(ptr %7)
%15 = tail call ptr @__quantum__qis__mz(ptr %9)
%16 = tail call ptr @__quantum__qis__mz(ptr %11)
tail call void @__quantum__rt__qubit_release_array(ptr %1)
ret void
}
declare ptr @__quantum__rt__qubit_allocate_array(i64) local_unnamed_addr
declare void @__quantum__rt__qubit_release_array(ptr) local_unnamed_addr
declare ptr @__quantum__rt__array_get_element_ptr_1d(ptr, i64) local_unnamed_addr
declare void @__quantum__qis__x__ctl(ptr, ptr)
declare void @generalizedInvokeWithRotationsControlsTargets(i64, i64, i64, i64, ptr, ...) local_unnamed_addr
declare void @__quantum__qis__h(ptr) local_unnamed_addr
declare ptr @__quantum__qis__mz(ptr) local_unnamed_addr
!llvm.module.flags = !{!0}
!0 = !{i32 2, !"Debug Info Version", i32 3}
Note that the results of each tool can be piped to further tools, creating a composable pipeline of compiler lowering tools.